Penerapan Computer Vision dalam License Plate Reader (LPR): Metodologi
Nergi Rahardi , Carvin Wirama, Jonathan , Kevin Chandra , Michael Young , dan Rini Wongso, S.Kom., M.T.I
Dalam artikel sebelumnya (Penerapan Computer Vision dalamLicense Plate Reader (LPR)), telah dibahas mengenai pengenalan LPR dan gambaran mengenai metode yang dipakai. Dalam artikel berikut ini akan dibahas secara mendetail untuk metodologi yang digunakan.
Pendeteksian huruf dan angka pada plat secara umum meliputi 3 tahap utama yaitu: Image Preprocessing, Segmentation, dan Recognition. Berikut adalah penjelasan lengkap untuk tiap tahap.
Pemrosesan awal gambar (Image Pre-processing)
Pemosresan awal gambar yang dilakukan adalah mengubah gambar yang diberikan menjadi berwarna hitam dan putih saja. Pemrosesan awal bertujuan untuk menguranginoise pada gambar agar karakter lebih mudah tersegmentasi dan terdeteksi nantinya. Metode yang digunakan adalah thresholding.
Thresholding adalah metode untuk mengsegmentasi gambar yang paling sederhana yang merubah gambar berwarna dan grayscale menjadi hitam dan putih. Cara kerja thresholding adalah dengan menentukan sebuah konstanta T yang mendefinisikan sebuah batas nilai untuk suatu pixel Ii,jyang dimana pixel akan dikategorikan sebagai warna hitam apabila Ii,j>T dan sebagai warna putih apabila Ii,j<= T.

Segmentasi karakter (Character Segmentation)
Segmentasi karakter adalah pemisahan satu karakter dengan karakter yang lainnya agar setiap karakter nantinya bisa dideteksi secara terpisah dari satu sama lain. Segmentasi karakter ini sendiri dibagi menjadi dua bagian, pemisahan tiap karakter dan pengkategorian apakah sebuah karakter merupakan huruf atau angka.
Pemisahan karakter dilakukan dalam beberapa tahap:
- Untuk tiap karakter, cari kemunculan pixel berwarna putih berdasarkan tiap kolom pada
- Modelkan sebagai sebuah graf degan tiap pixel sebagai nodenya.
- Tetapkan pixel putih yang telah ditemukan di tahap 1 sebagai root dari graf.
- Cari seluruh connected component (semua pixel putih yang terhubung) dari pixel putih tersebut untuk ditetapkan sebagai sebuah karakter menggunakan algoritma Breadth-First-Search.
Breadth-First-Search (BFS) adalah algoritma yang digunakan untuk melakukan pencarian pada sebuah graf yang dimulai dari satu buah root dan melebar ke node-node tetangganya. BFS akan terus melakukan pencarian sampai semua node yang bisa dikunjungi sudah terkunjungi semua. Sehingga BFS menjadi salah satu algoritma pencarian yang cocok untuk menemukan connected component.
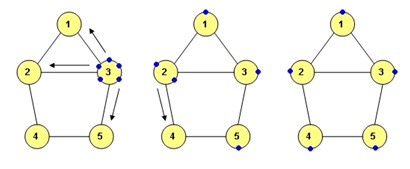
Kemudian, akan dilakukan beberapa validasi untuk menentukan apakah connected component yang ditemukan valid atau tidak berdasarkan panjang, lebar dan luasnya, serta apakah panjang karakter melebihi lebarnya. Hal ini bertujuan untuk menghindari pixel putih yang hanya merupakan sebuah titik kecil karena cat yang kurang rapih atau bising pada gambar yang tidak berhasil dihilangkan pada proses thresholding di tahap sebelumnya.
Pengkategorian tiap karakter dilakukan dalam beberapa tahap :
- Menentukan jarak minimum dari setiap dua buah karakter yang letaknya bersebelahan. Jarak minimum didefinisikan sebagai jarak dari titik terkanan pada karakter di posisi kiri dengan titik terkiri pada karakter di posisi kanan.
- Menentukan sebuah konstanta sebagai faktor pengali untuk dikalikan dengan jarak minimum tersebut.
- Mencari jarak rata-rata dari setiap dua buah karakter yang jaraknya berada dibawah jarak minimum dikalikan faktor pengali.
- Definisikan karakter pertama sebagai huruf. Kemudian, untuk tiap karakter setelah karakter pertama, apabila jarak antar karakter melebihi jarak rata-rata yang sudah didapat, maka kategori karakter tersebut akan menjadi kebalikan dari kategori karakter sebelumnya (apabila karakter sebelumnya dikategorikan sebagai huruf, maka karakter saat ini dikategorikan sebagai angka, begitu juga sebaliknya). Sedangkan, apabila jarak antar karakter saat ini dengan karakter sebelumnya kurang dari jarak rata-rata yang sudah didapat, maka kategori karakter tersebut akan sama dengan kategori karakter sebelumnya.

Pendeteksian karakter
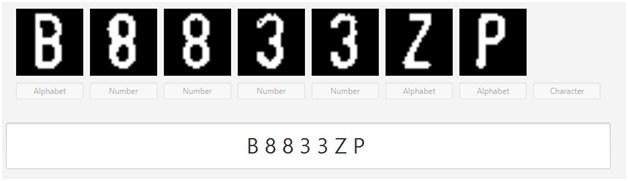
Pendeteksian karakter adalah proses yang mendeteksi huruf atau angka apa yang tertera pada gambar yang diberikan. Sebelum karakter dideteksi, akan dilakukan beberapa processing lagi pada gambar masing-masing karakter. Pertama, ratio panjang dan lebar gambar setiap karakter akan dibuat menjadi 1 : 1 (bentuk persegi) dan ukurannya akan dibuat menjadi 28×28. Kedua, akan dilakukan normalisasi pada tiap pixel agar berada di range 0.0 – 1.0. Kedua tahap ini dilakukan untuk menyesuaikan gambar dengan dataset yang digunakan untuk melatih model artificial neural network.
Kemudian gambar yang telah diproses ulang akan dikirim ke fungsi pendeteksian dalam bentuk matrix. Fungsi pendeteksian akan mendeteksi gambar menggunakan model artificial neural network yang telah dilatih dan akan mengembalikan hasil berupa huruf / angka yang berhasil diprediksi.
Artificial Neural Network (ANN) adalah sebuah jaringan dari beberapa unit komputasi yang saling terhubung yang dimodelkan seperti jaringan saraf manusia. Pada dasarnya, ANN merupakan fungsi yang menerima input dan akan menghasilkan output f(x) -> y. Dikarenakan ANN merupakan metode pemodelan data non-linear, ANN dapat memodelkan hubungan kompleks antara input dan output.
ANN dibagi menjadi 3 layer yang saling berhubungan :
- Input layer : Layer masukan yang terdiri dari neuron yang berfungsi sebagai penerima input untuk diproses. Layer ini akan terhubung dengan hidden layer atau langsung dengan output layer jika tidak ada hidden layer (perceptron).
- Hidden layer : Layer tersembunyi yang terdiri dari neuron yang berfungsi untuk memodelkan fitur pada input menjadi lebih kompleks agar model ANN dapat lebih menyesuaikan output nantinya dengan hasil yang diinginkan.
- Output layer : Layer luaran yang terdiri dari neuron yang memproses hasil dari proses pada layer sebelumnya menjadi output dari input yang diberikan. Output merupakan sebuah angka yang menunjukkan seberapa mungkin input yang diberikan akan menghasilkan keluaran tersebut.

Tahap cara pemodelan dan pelatihan ANN :
- Menetapkan jumlah unit pada input layer. Kami menggunakan 784 inputunits untuk input layer menyesuaikan dengan ukuran gambar pada dataset yang didapat yaitu 28×28 pixel.
- Menetapkan jumlah unit pada hidden layer jika ada. Kami menggunakan hidden layer dengan 200 hidden units.
- Menetapkan jumlah unit pada output layer. Karena ANN untuk huruf dan angka dimodelkan secara terpisah maka, ANN untuk huruf memiliki 26 output units dan ANN untuk angka memiliki 10 output untis.
- ANN kemudian dilatih dengan 1016 data untuk masing-masing angka dan 880 data untuk masing-masing huruf. Pelatihan ANN menggunakan metode Back propagation.
Back Propagation adalah metode pelatihan yang umum digunakan untuk melatih sebuah model ANN dan sering digunakan bersamaan dengan metode optimisasi seperti gradient descent. Cara kerja back propagation adalah mengulang dua siklus, yaitu propagation dan weight update. Pertama, input yang diberikan melalui input layer akan diteruskan ke layer-layer berikutnya hingga ke output layer (Forward propagation) menggunakan fungsi aktivasi sigmoid function. Kedua, output yang dihasilkan akan dibandingkan dengan output yang diinginkan / seharusnya dan dihitung error value dari perbandingan kedua output tersebut. Error value ini kemudian akan dihitung terus ke belakang sampai ke input layer (Backward propagation) untuk menghitung error value pada tiap neuron. Error value ini akan digunakan untuk menyesuaikan weight antara tiap neuron agar saat dilakukan forward propagation kembali, error value yang dihasilkan akan berkurang. Kedua siklus tersebut akan diulang terus-menerus sampai jumlah iterasi yang telah ditetapkan.
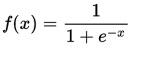
Tahap pendeteksian karakter oleh ANN :
- Input matrix yang diberikan akan dibuat menjadi neuron untuk input layer.
- Melakukan feed forward propagation dengan weight hasil pelatihan ANN.
- Cari probabilitas tertinggi dari semua neuron pada output layer.
- Fungsi pendeteksian mengembalikan nomor neuron pada output layer yang memiliki probabilitas tertinggi bahwa karakter merupakan huruf / angka tersebut.
Data yang diuji berupa gambar plat nomor mobil dengan mengambil foto plat di tempat-tempat umum dan juga gambar dari internet. Adapun syarat pengambilan data seperti berikut :
- Gambar plat harus di ambil dari depan, tidak boleh miring.
- Gambar plat yang diambil harus bersih dari kotoran dan gangguan lain (baut, pantulan sinar, stiker yang mencolok, dll.).
- Gambar plat diusahakan harus terang dan jelas.
- Angka dan huruf diplat tidak boleh menempel satu sama lain.
- Jarak antara angka dan huruf mengikuti standar yang berlaku di Indonesia.
Dataset untuk pelatihan model didapat dari:
Huruf dan angka dari plat mobil yang berasal dari foto secara langsung dan gambar di https://www.google.co.id/search?q=plat+mobil&source=lnms&tbm=isch&sa=X&ved=0ahUKEwjh0eHj97HRAhWCF5QKHejBBLMQ_AUICCgB&biw=1242&bih=580.
Sebagaimana di sampaikan dalam artikel sebelumnya, hasil uji dari metode di atas didapatkan akurasi deteksi karakter sebesar 92.74% dengan akurasi pembacaan keseluruhan plat sebesar 51%.
References:
- Liu, C., Suen, C., Cheriet, M., Kharma, N. (2007).Character Recognition Systems: A Guide for Students and Practitioners. 1st Edition,John Willy & Sons, INC: New Jersey
- Khan, S. A. (1998).Character segmentation heuristics for check amount verification (Doctoral dissertation, Massachusetts Institute of Technology).
- Nugroho, D. (2012).Perbandingan dan Implementasi Sistem Deteksi Citra Plat Mobil Menggunakan Metode Deteksi Tepi Prewitt dan Deteksi Tepi Sobel (Doctoral dissertation, Program Studi Teknik Informatika FTI-UKSW).
- Setiawan, A. (2008). Sistem pengenalan plat nomor mobil untuk aplikasi informasi karcis parkir [skripsi].Surabaya: Teknik Komputer, Institut Teknologi Sepuluh Nopember.
- Yuniarti, A., & Amaliah, B. (2011). Pengenalan Merek Mobil Berbasis Deteksi Plat dan Logo Menggunakan Jaringan Syaraf Probabitistik.
Published at :