Vector Space Model dalam Pengolahan Teks
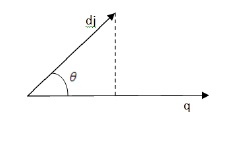
Vector Space Model (VSM) merupakan sebuah pendekatan natural yang berbasis pada vektor dari setiap kata dalam suatu dimensi spasial. Dokumen dipandang sebagai sebuah vektor yang memiliki magnitude (jarak) dan direction (arah). Pada VSM, sebuah kata direpresentasikan dengan sebuah dimensi dari ruang vektor. Relevansi sebuah dokumen ke sebuah kueri didasarkan pada similaritas diantara vektor dokumen dan vektor kueri.
VSM memungkinkan sebuah kerangka pencocokan parsial. Hal ini dicapai dengan menetapkan bobot non-biner untuk istilah indeks dalam kueri dan dokumen. Bobot istilah yang akhirnya digunakan untuk menghitung tingkat kesamaan antara setiap dokumen yang tersimpan dalam sistem dan permintaan pengguna. Dokumen yang terambil disortir dalam urutan yang memiliki kemiripan, model vektor memperhitungkan pertimbangan dokumen yang relevan dengan permintaan pengguna. Hasilnya adalah himpunan dokumen yang terambil jauh lebih akurat. Sebuah dokumen dj dan sebuah query q direpresentasikan sebagai vektor t-dimensi.
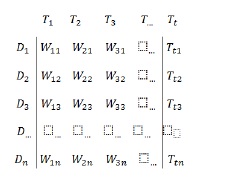
Dalam VSM, koleksi dokumen direpresentasikan sebagai sebuah matrik term-document (atau matrik term frequency). Setiap sel dalam matrik bersesuaian dengan bobot yang diberikan dari suatu term dalam dokumen yang ditentukan. Nilai nol berarti bahwa term tersebut tidak ada dalam dokumen.
Proses perhitungan VSM melalui tahapan perhitungan term frequency (tf) menggunakan persamaan:
![]()
Dengan tf adalah term frequency, dan tfi,j adalah banyaknya kemunculan term ti dalam dokumen dj, Term frequency (tf) dihitung dengan menghitung banyaknya kemunculan term ti dalam dokumen dj. Perhitungan Inverse Document Frequency (idf), menggunakan persamaan:
![]()
Dengan idfi adalah inverse document frequency, N adalah jumlah dokumen yang terambil oleh sistem, dan dfi adalah banyaknya dokumen dalam koleksi dimana term ti muncul di dalamnya, maka perhitungan idfi digunakan untuk mengetahui banyaknya term yang dicari (dfi) yang muncul dalam dokumen lain yang ada pada database (korpus). Perhitungan term frequency Inverse Document Frequency (tfidf), menggunakan persamaan:
![]()
Dengan Wij adalah bobot dokumen, N adalah jumlah dokumen yang terambil oleh sistem, tfi,j adalah banyaknya kemunculan term ti pada dokumen dj, dan dfi adalah banyaknya dokumen dalam koleksi dimana term ti muncul didalamnya. Bobot dokumen (Wij) dihitung untuk didapatkannya suatu bobot hasil perkalian atau kombinasi antara term frequency (tfi,j) dan Inverse Document Frequency (dfi).
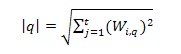
Dengan |q| adalah jarak kueri, dan Wiq adalah bobot kueri dokumen ke-i, maka jarak kueri (|q|) dihitung untuk didapatkan jarak kueri dari bobot kueri dokumen (Wiq) yang terambil oleh sistem. Jarak kueri bisa dihitung dengan persamaan akar jumlah kuadrat dari query.
![]()
Dengan |dj| adalah jarak dokumen, dan Wij adalah bobot dokumen ke-i, maka jarak dokumen (|dj|) dihitung untuk didapatkan jarak dokumen dari bobot dokumen (Wij) yang terambil oleh sistem. Jarak dokumen bisa dihitung dengan persamaan akar jumlah kuadrat dari dokumen. Perhitungan pengukuran similaritas query document (inner product), menggunakan persamaan
![]()
Dengan Wij adalah bobot term dalam dokumen, Wiq adalah bobot kueri, dan sim (q, dj) adalah similaritas antara kueri dan dokumen. Similaritas antara kueri dan dokumen atau inner product / Sim (q, dj) digunakan untuk mendapatkan bobot dengan didasarkan pada bobot term dalam dokumen (Wij) dan bobot query (Wiq) atau dengan cara menjumlah bobot q dikalikan dengan bobot dokumen.
Pengukuran cosine similarity (menghitung nilai kosinus sudut antara dua vektor) menggunakan persamaan:
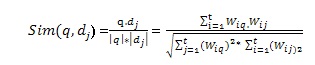
Similaritas antara kueri dan dokumen atau sim(q,dj) berbanding lurus terhadap jumlah bobot kueri (q) dikali bobot dokumen (dj) dan berbanding terbalik terhadap akar jumlah kuadrat q (|q|) dikali akar jumlah kuadrat dokumen (|dj|).
Perhitungan similaritas akan menghasilkan bobot dokumen dari 0 mendekati 1 atau menghasilkan bobot dokumen yang lebih besar dibandingkan dengan nilai yang dihasilkan dari perhitungan inner product.
Hasil tersebut akan diuji lagi dengan recall dan precision. Precision dapat dianggap sebagai ukuran ketepatan atau ketelitian, sedangkan recall adalah kesempurnaan.
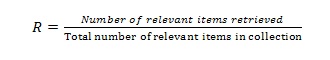
Dengan R adalah recall, maka nilai R didapatkan dengan membandingkan jumlah item relevan yang diperoleh dengan jumlah total item relevan pada collection.
![]()
Dengan P adalah precision. maka nilai P didapatkan dengan membandingkan jumlah item relevan yang diperoleh dengan jumlah total item yang diperoleh. Precision adalah jumlah dokumen relevan yang diperoleh dari database setelah dinilai user dengan informasi yang dibutuhkan.
![]()
Dengan F adalah F-measure yang merupakan ukuran hasil kombinasi dari precision dan recall.