
Syntactic Parsing
Struktur pada proses syntactic parsing biasanya berupa parse-tree. Pada area natural language processing, syntactic parsing berarti bahwa parser akan mencoba mencari cara untuk membuat tree sesuai dengan grammar dari bahasa tersebut.
Contoh dari grammar bahasa inggris dan lexiconnya adalah sebagai berikut:

Misalkan input kalimat yang dibaca adalah “book that flight”, maka parser akan mencoba membuat syntax tree dari kalimat tersebut berdasarkan grammar bahasa inggris diatas. Ada 2 strategi yang dapat dilakukan oleh parser, yaitu metode top-down parsing (goal-directed search) dan bottom-up parsing (data-directed search). Top-down parsing akan membuat tree mulai dari root sampai menemukan lexicon yang sesuai dengan input kalimat (melakukan derivasi). Sedangkan bottom-up parsing akan mulai dari informasi lexicon yang diberikan, kemudian akan mencari grammar yang sesuai hingga mencapai root.
Berikut adalah contoh dari top-down parsing.
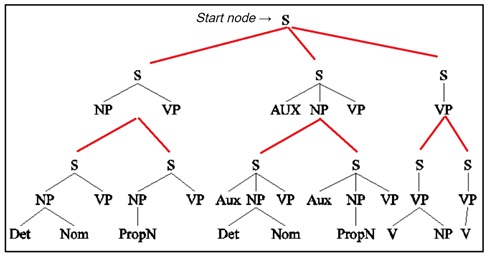
Top-down parsing akan mencari semua kemungkinan yang dapat dibentuk dari root. Pencarian dimulai dari grammar paling utama (biasanya terletak dipaling atas dari sebuah grammar) yaitu S dimana S dapat diderivasi menjadi NP VP atau AUX NP VP atau VP. Dapat dilihat pada gambar diatas dimana setelah perulangan yang pertama maka akan terbentuk menjadi 3 kemungkinan tree. Kemudian pencarian akan dilakukan kembali untuk menemukan semua kemungkinan subtree yang bisa terbentuk dari level terakhir, dengan melihat kemungkinan derivasi dari masing-masing node non-terminal paling kiri. Pencarian akan terus dilakukan sampai terbentuk tree yang menghasilkan string yang sama dengan input. Langkah pencarian tersebut dapat dilakukan dengan Depth First Search ataupun Breadth First Search.
Sedangkan untuk bottom-up parsing pencarian akan dimulai dengan memperhatikan input string yang ada dan berusaha mencapai root. Contoh subtree yang dapat terbentuk dari metode bottom-up parsing dapat dilihat pada gambar dibawah ini.
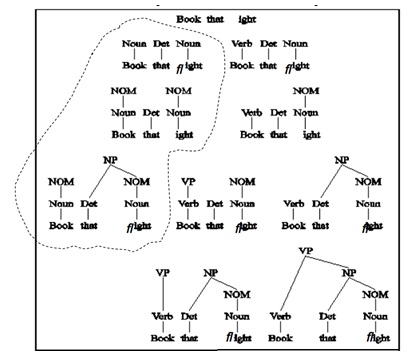
Dengan menggunakan metode top-down parsing maka waktu tidak akan terbuang untuk mencari tree yang tidak bisa diderivasi dari S, sedangkan bottom-up parsing tidak membuang waktu untuk membuat tree yang tidak bisa di-reduce (digantikan rule di RHS menjadi LHS) ke root.
Salah satu kendala pada top-down parsing adalah masalah left recursive, dimana sebuah LHS memiliki banyak rule. Bayangkan jika S memiliki 500 rules, dimana 499 dimulai dengan NP dan 1 sisanya dimulai dengan V, dan kalimat yang dicari dimulai dengan V. Pencarian akan terasa useless karena akan dilakukan ekspansi sebanyak kemungkinan yang terjadi padahal tidak digunakan. Pencarian menggunakan top-down parsing akan lebih menguntungkan jika grammar yang ada memiliki aturan yang baik (grammar-driven control).
Bottom-up parsing tidak dapat menangani kategori empty seperti termination problem. Bottom-up parsing dirasa kurang menguntungkan jika terjadi ambiguitas yang besar pada level lexical. Salah satu solusi yang bisa dilakukan sama dengan top-down parsing juga yaitu mengontrol dari sisi grammar yang baik diproduksi seperti apa (grammar-driven control). Namun keduanya tetap memiliki substructure umum dimana saja (repeated work).
References:
- Daniel Jurafsky & James H. Martin. 2006. Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition. Prentice Hall. New Jersey. ISBN:978-0131873216
- Christopher D. Manning. 1999. Foundations of statistical natural language processing. Massachusetts Institute of Technology Press. Cambridge, Mass.. ISBN:0262133601