
Weka: Software untuk Memahami Konsep Data Mining
WEKA merupakan sebuah perangkat lunak yang menerapkan berbagai algoritma machine learning untuk melakukan beberapa proses yang berkaitan dengan sistem temu kembali informasi atau data mining. Beberapa fitur unggulan yang dimiliki oleh WEKA yaitu:
- Classification
Di dalam WEKA terdapat banyak algoritma yang mendukung untuk proses klasifikasi sebuah objek serta pengguna dimudahkan dalam melakukan implementasi secara langsung. User dapat melakukan load dataset, melakukan pemilihan algoritma untuk klasifikasi, kemudian diberikan beberapa representasi data yang mewakili hasil akurasi, tingkat kesalahan dari proses klasifikasi.
- Regression
Regression merupakan sebuah proses yang dapat melakukan suatu prediksi terhadap berbagai pola yang sudah terbentuk sebelumnya yang dijadikan sebagai model data. Tujuan dari regression adalah menciptakan suatu variabel baru yang mewakili suatu representasi perkembangan data pada masa yang akan datang. WEKA mendukung proses regression dan hal tersebut dipermudah dengan user interface/user experience yang sederhana.
- Clustering
Clustering merupakan salah satu cabang konsep dari unsupervised method dari machine learning yang bertujuan untuk melakukan pengelompokan data dan juga menjelaskan hubungan/relasi yang ada di antara data tersebut dan memaksimalkan kesamaan antar satu kelas/cluster tetapi meminimumkan kesamaan antar kelas/cluster. Clustering digunakan untuk analisa suatu data dan diharapkan menghasilkan suatu representasi data yang mewakili suatu pola yang terbentuk akibat relasi yang ada antar data.Di dalam WEKA tersedia beberapa pendekatan algoritma untuk menangani permasalahan clustering dan pada fitur ini juga terdapat bagian kesimpulan dari proses clustering data yang memberikan secara garis besar perhitungan dan hasil yang diberikan dalam implementasi algoritma clustering.
- Association Rules
Association Rules merupakan metode yang digunakan untuk menemukan berbagai relasi antara banyaknya variabel yang terdapat di dalam sebuah basis data dengan jumlah yang besar.
- Visualization
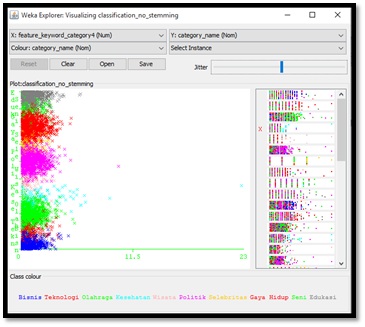
WEKA memiliki fitur untuk memberikan sebuah representasi data hasil sebuah proses data mining dalam bentuk gambar atau chart yang juga dapat dilakukan pemilihan berbagai parameter yang mendukung dalam membentuk representasi data yang ada dalam aplikasi WEKA.
- Data Preprocessing
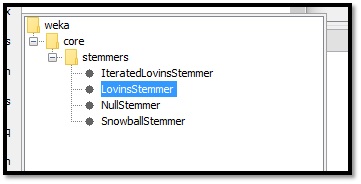
WEKA menyediakan fitur dalam hal data preprocessing yaitu stemming dan stopword removal. Proses stemming dan stopword removal yang ada di dalam perangkat lunak WEKA berbasiskan Bahasa Inggris, sehingga untuk implementasi bahasa diluar bahasa Inggris diharuskan untuk melakukan proses preprocessing data di luar aplikasi WEKA. Beberapa algoritma stemming yang telah disediakan oleh WEKA adalah Iterated Lovins Stemmer, Lovins Stemmer dan Snowball Stemmer.
Data yang digunakan pada Weka adalah dengan format ekstensi .arff. Anda bisa membuka file dengan ekstensi ini dengan berbagai macam text editor, misalnya Notepad.
Contoh file berformat .arff adalah sebagai berikut:

Apabila Anda ingin mencoba langsung software Weka ini, Anda bisa unduh secara langsung pada link berikut ini: https://www.cs.waikato.ac.nz/ml/weka/downloading.html
Anda akan dapat lebih mudah memahami, apabila Anda mencoba software ini dan melakukan berbagai macam percobaan dengan menggunakan software ini.
Selamat mencoba, dan selamat belajar.