
Mekanisme Atensi (Attention Mechanism) pada Teks
Mekanisme atensi (attention mechanism) merupakan algoritma yang membantu model neural network supaya lebih baik performanya dengan berfokus pada local feature yang memiliki hubungan lebih kuat ketika model melakukan pelatihan. Peran mekanisme atensi ini diilustrasikan pada gambar 1. Konsep dasar mekanisme atensi adalah dengan memberikan weighted access pada setiap timestep untuk memperkuat kemampuan model dalam memproses sequential data. Teknik atensi ini dicetuskan pertama kali untuk atensi visual pada pemrosesan image dimana latar belakangnya adalah permasalahan kapasitas yang terbatas untuk memproses informasi.

Gambar 1. Visualisasi Mekanisme Atensi pada Teks
Neural network memiliki permasalahan ketika harus menghafalkan sebuah data sekuensial yang panjang. Hal ini dapat digambarkan pada machine translation task. Analoginya adalah seperti ketika manusia hendak melakukan penerjemahan dari satu Bahasa ke Bahasa lain untuk sebuah kalimat yang panjang. Penerjemahan akan dilakukan secara bertahap dari anak kalimat pertama, anak kalimat kedua, dan seterusnya. Mekanisme seperti ini yang menjadi solusi ketika neural network hendak menerjemahkan sebuah kalimat yang panjang, yaitu dengan mekanisme atensi.
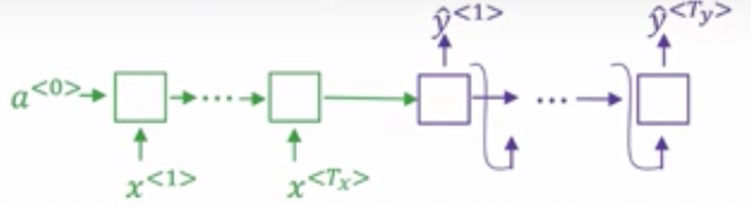
Gambar 2. Permasalahan Long Sequence
Machine translation menjadi salah satu field dimana mekanisme atensi digunakan untuk tipe data teks dengan memfokuskan translasi pada bagian tertentu pada kalimat aslinya. Penelitian terkait yang sudah pernah dilakukan mengusulkan 2 pendekatan atensi, yaitu pendekatan global dan local. Perbedaan dari 2 kelas ini adalah letak model atensinya. Ketika penempatan model atensi diletakkan pada semua posisi data sumber maka model merupakan global attentional model, dan sebaliknya maka model merupakan local attentional model.
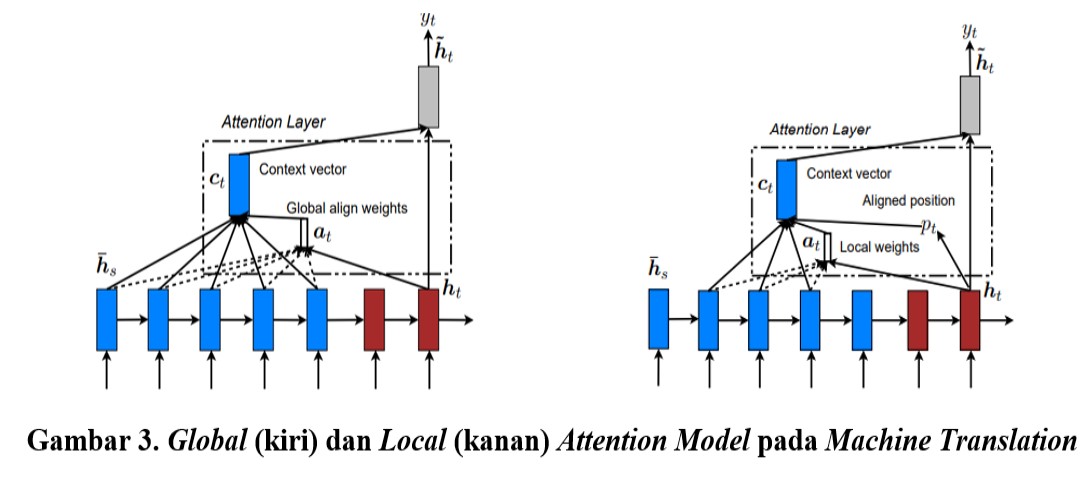
Mekanisme atensi sudah pernah digunakan untuk sistem tanya jawab otomatis menggunakan kombinasi antara local dan global view. Disebutkan bahwa hasilnya lebih baik dari state-of-the-art pada InsuranceQA. Penggabungan beberapa arsitektur deep learning yang menarik karena memberikan hasil yang lebih baik pada banyak task, ditambah lagi dengan adanya eksperimen klasifikasi teks menggunakan Attention-based RNN yang menurut dugaan penulisnya berhasil melebihi semua traditional baseline system. Arsitektur attention-based RNN yang diusulkan terlihat pada gambar 4.
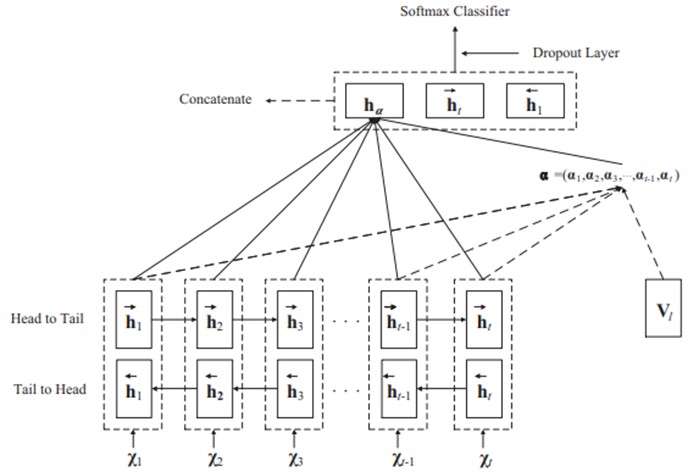
Gambar 4. Attention-based Recurrent Neural Network
Referensi:
- Bahdanau, D., Cho, K., dan Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Desimone, R. dan Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual review of neuroscience, 18(1):193–222.
- Britz, D. (2016). Attention and Memory in Deep Learning and NLP. https://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/
- Ng, A. (2018). Sequence to sequence https://cs230.stanford.edu/wp-content/uploads/C5M3.pdf
- Luong, M.-T., Pham, H., dan Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
- Bachrach, Y., Zukov-Gregoric, A., Coope, S., Tovell, E., Maksak, B., dan McMurtie, C. (2017). An attention mechanism for answer selection using a combined global and local view. arXiv preprint arXiv:1707.01378.
- Du, C. dan Huang, L. (2018). Text classification research with attention-based recurrent neural networks. International Journal of Computers Communications & Control, 13(1):50-61.