
GPT-2 : Model yang Mampu Menulis layaknya Manusia
Dalam ranah kecerdasan buatan, terdapat sebuah bidang yang disebut dengan Natural Language Processing (NLP). Sebuah ranah studi yang fokus pada tujuan menjadikan komputer bisa mengerti bahasa manusia. Studi NLP sudah mengalami banyak kemajuan saat ini, mulai dari mengklasifikasikan jenis teks hingga menulis teks itu sendiri.
Salah satu model yang sudah mampu menyerupai kemampuan manusia dalam berbahasa adalah GPT-2. Dengan memberikan masukan berupa beberapa frase, model ini mampu melanjutkan bercerita layaknya manusia. Model GPT-2 menggunakan mekanisme dalam proses pembelajarannya. Model ini dilatih dengan menggunakan 40GB data teks yang ada di internet. Dalam pembelajarannya, model ini diberi tugas untuk memprediksi kata selanjutnya dari sebuah teks.
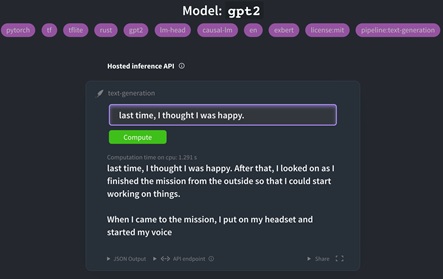
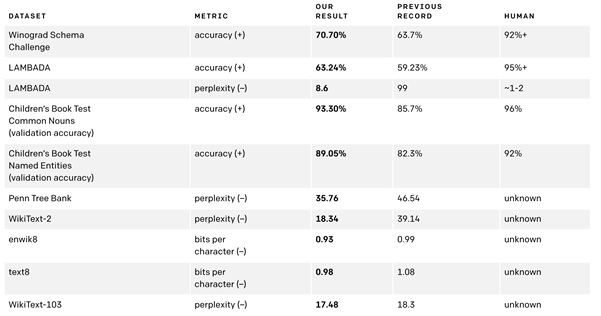
Model GPT-2 merupakan model berbasis transformer sebagai language modelnya. Model ini memiliki 1,5 juta parameter yang dilatih untuk menebak kata berikutnya dari sebuah kalimat yang menjadi output. Model ini sejatinya hanya perbesaran dari model sebelumnya yakni GPT, dengan 10 kali lipat jumlah parameter dan 10 kali lipat jumlah data. Hal menarik lainnya dari model ini adalah, model ini mampu menyelesaikan berbagai NLP tasks lainnya tanpa memerlukan pelatihan ulang untuk domain tersebut, atau bisa disebut zero-shot learning. Berikut adalah beberapa hasil yang pernah diraih oleh model GPT-2 dalam beberapa dataset.
Dikarenakan kemampuan model ini yang begitu baik, maka muncul semacam isu mengenai penyalahgunaan model ini. Oleh sebab itu, open.ai, sebagai lembaga yang mengembangkan model GPT-2, membuat model ini ke dalam beberapa versi. Di antaranya adalah model dengan ukuran kecil, 117 ribu parameter, hingga yang paling besar 1,5 juta parameter. Akan tetapi terkait kekhawatiran penyalahgunaan tersebut, open.ai tidak merilis model dengan 1,5 juta parameter.

Jika kita lihat sekarang, teknologi seperti ini menjadi pisau bermata dua. Di satu sisi, ia dapat menjadi alat guna membantu produktivitas manusia seperti menjadi asisten dalam melakukan penulisan hingga membantu proses pemahaman sebuah teks. Di lain sisi model seperti ini bisa pula menjadi alat untuk tindakan yang kurang baik seperti menulis cerita palsu hingga membuat berita yang misleading. Maka memberikan perhatian khusus dalam merilisnya ke publik adalah salah satu langkah yang cukup bijak yang dilakukan oleh lembaga yang melakukan riset.
Referensi
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2018). Language Models are Unsupervised Multitask Learners.