
Memahami LoRA: Teknik Efisien untuk Fine-Tuning Model AI Modern
https://www.ibm.com/think/topics/lora
Dalam beberapa tahun terakhir, perkembangan model kecerdasan buatan (AI) skala besar seperti GPT, Stable Diffusion, dan LLaMA telah mengubah cara kita membangun dan menerapkan sistem berbasis AI. Namun, ukuran model yang semakin besar membawa tantangan baru: bagaimana melakukan fine-tuning tanpa harus melatih ulang seluruh parameter yang berjumlah miliaran. Di sinilah muncul sebuah teknik revolusioner bernama LoRA (Low-Rank Adaptation), yang menawarkan solusi efisien untuk menyesuaikan model besar dengan sumber daya yang jauh lebih kecil.
LoRA memungkinkan peneliti atau praktisi AI melakukan penyesuaian model tanpa harus memodifikasi semua bobot model aslinya. Pendekatan ini akan membuat pekerjaan menjadi lebih efisien, baik dari segi waktu maupun sumber daya yang digunakan.
Mengapa Fine-Tuning Menjadi Tantangan
Model AI besar seperti GPT-3 memiliki ratusan miliar parameter. Melatih ulang seluruh parameter tersebut untuk tugas tertentu (misalnya membuat versi GPT untuk bidang medis atau hukum) akan membutuhkan sumber daya komputasi yang sangat besar. Proses fine-tuning tradisional memerlukan:
- GPU dengan spesifikasi yang besar.
- Waktu pelatihan yang panjang.
- Risiko catastrophic forgetting, di mana model kehilangan kemampuan aslinya saat belajar hal baru.
Untuk mengatasi keterbatasan ini, berbagai pendekatan efisiensi dikembangkan, seperti adapter tuning, prefix tuning, dan yang paling populer saat ini, yaitu LoRA.
Apa itu LoRA?
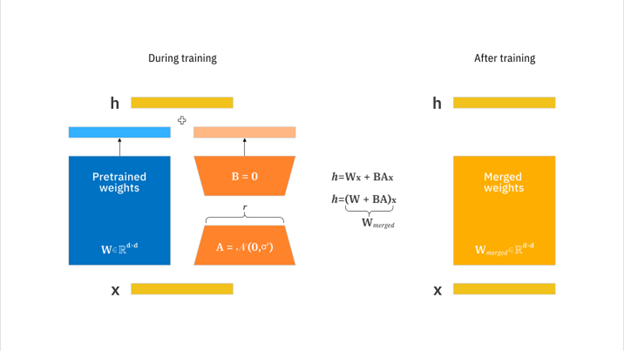
LoRA (Low-Rank Adaptation) pertama kali diperkenalkan oleh Hu et al. (2021) dalam paper berjudul “LoRA: Low-Rank Adaptation of Large Language Models” [1]. Latar belakang ide yang mendasari LoRA ini adalah pemikiran bahwa daripada memperbarui semua bobot model, kita cukup hanya menambahkan lapisan kecil dengan jumlah parameter rendah yang mempelajari hal baru yang dibutuhkan.
Secara matematis, LoRA memanfaatkan prinsip dekomposisi matriks berperingkat rendah. Jika kita memiliki bobot model utama , LoRA menambahkan dua matriks kecil dan sehingga:
Di sini:
- A dan B dan adalah matriks kecil dengan peringkat rendah (rank << dimensi asli).
- Hanya A dan B yang dilatih, sedangkan W dibekukan (freeze).
Pendekatan ini membuat proses fine-tuning menjadi jauh lebih ringan dan cepat, karena jumlah parameter yang diperbarui berkurang drastis.
Mengapa LoRA Efisien?
- Hemat Parameter
LoRA biasanya hanya menambah 0.1%–1% parameter dari model aslinya. Misalnya, jika model memiliki 7 miliar parameter, LoRA mungkin hanya menambahkan beberapa juta parameter saja. - Hemat Memori dan Komputasi
Karena hanya melatih sebagian kecil lapisan, konsumsi GPU dan waktu pelatihan berkurang drastis. - Modular dan Reusable
Hasil fine-tuning dapat disimpan dalam bentuk adaptor LoRA terpisah. Artinya, kita bisa mengganti atau menambahkan kemampuan baru ke model dasar tanpa harus melatih ulang semuanya. - Kinerja yang Kompetitif
Banyak eksperimen menunjukkan bahwa LoRA dapat mencapai performa yang hampir setara dengan fine-tuning penuh. Misalnya, eksperimen pada GPT-3 dan Stable Diffusion menunjukkan hanya sedikit penurunan akurasi atau kualitas hasil [2].
Penerapan LoRA di Dunia Nyata
Seiring populernya pendekatan ini, LoRA mulai diintegrasikan ke berbagai platform dan framework. Beberapa contohnya:
- Hugging Face Transformers telah menyediakan integrasi LoRA dengan PEFT (Parameter Efficient Fine-Tuning) library, memungkinkan pengguna melakukan fine-tuning dengan hanya beberapa baris kode.
- Stable Diffusion LoRA digunakan untuk menyesuaikan gaya atau karakter visual tertentu tanpa melatih ulang seluruh model gambar.
- ChatGPT dan LLaMA LoRA: komunitas open-source banyak membangun LoRA adapters untuk menambah pengetahuan domain tertentu, seperti chatbot medis, hukum, atau akademik.
LoRA vs Metode Fine-Tuning Lainnya
| Metode | Parameter yang Dilatih | Kelebihan | Kekurangan |
| Full Fine-Tuning | Semua | Akurasi tinggi, fleksibel | Mahal secara komputasi |
| Adapter Tuning | Tambahan modul kecil | Modular | Kadang kurang efisien |
| Prefix Tuning | Menambah token konteks | Efisien untuk LLM | Tidak cocok untuk semua arsitektur |
| LoRA | Matriks berperingkat rendah | Efisien, fleksibel, kinerja tinggi | Perlu konfigurasi rank optimal |
Dengan efisiensi dan fleksibilitasnya, LoRA menjadi sweet spot antara performa tinggi dan efisiensi sumber daya.
Kesimpulan
LoRA adalah salah satu inovasi paling berpengaruh dalam ekosistem AI modern. Dengan prinsip sederhana namun efektif, LoRA memungkinkan adaptasi model besar secara cepat, murah, dan efisien. Dengan keuntungan ini, LoRA dapat menjadi opsi menarik untuk penelitian atau proyek yang berkaitan dengan AI.
Penulis
Muhammad Alfhi Saputra, S.Kom., M.Kom.
Referensi
[1] Hu, Edward J., et al. “LoRA: Low-Rank Adaptation of Large Language Models.” arXiv preprint arXiv:2106.09685 (2021).
[2] Dettmers, Tim, et al. “QLoRA: Efficient Finetuning of Quantized LLMs.” arXiv preprint arXiv:2305.14314 (2023).
[3] Hugging Face. “PEFT: Parameter-Efficient Fine-Tuning Library.” https://huggingface.co/docs/peft