
Cross-Validation 101: Mengenal Ragam Teknik Cross-Validation untuk Evaluasi Model Machine Learning
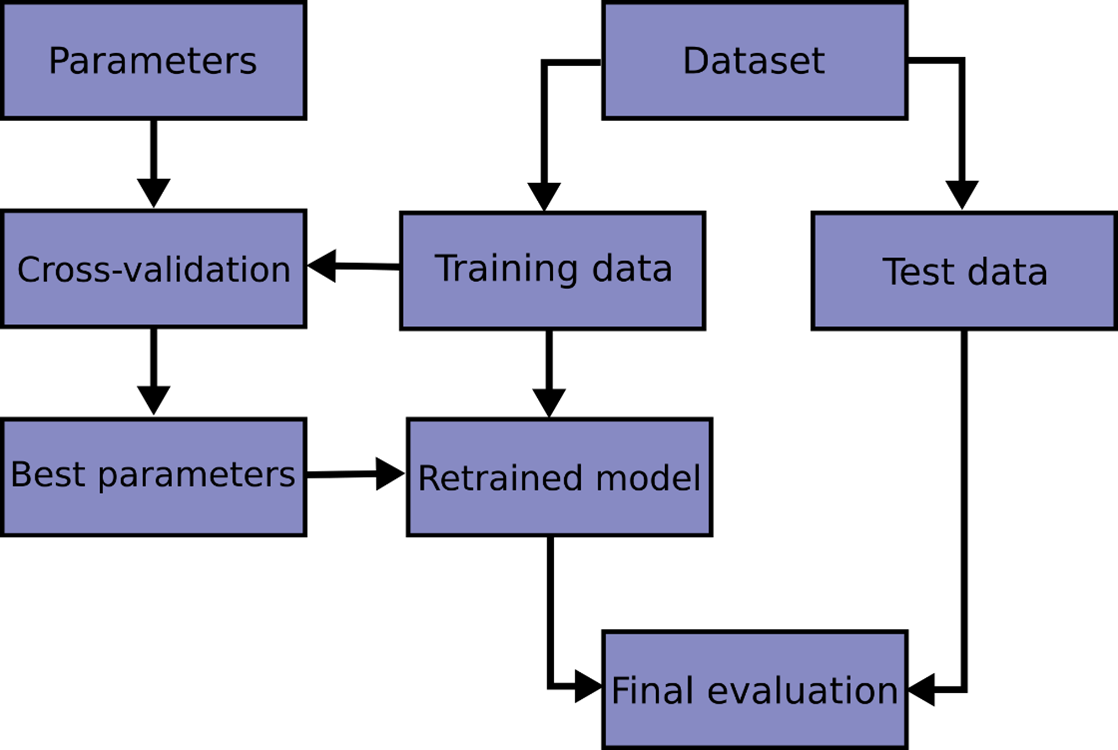
Pipeline illustration of where cross validation should be used (sumber: https://scikit-learn.org/stable/modules/cross_validation.html)
Kalian pasti tau lah ya, terutama buat yang sering eksplor dan main-main di bidang machine learning, seberapa susahnya bikin model yang nggak cuma cakep pas latihan doang tapi juga tetep pinter kalau dikasih data baru. Makanya ada nih teknik penting yang bisa ngebantu kita ngecek seberapa bagus model bisa untuk ‘ngeh’ beneran sama pola, bukan cuma hafalan. Caranya? Data bakal dibagi-bagi jadi beberapa subset buat dilatih dan diuji secara sistematis. Namanya adalah cross validation, Menariknya, cross-validation ini punya banyak jenis, dan masing-masing punya gaya sendiri tergantung karakter data dan kebutuhan evaluasinya. Yuk kita bahas!
Konsep dasar
Secara umum, cross validation bekerja dengan memecah dataset menjadi beberapa bagian, melatih model pada sebagian data, lalu mengujinya pada bagian yang tidak digunakan untuk pelatihan. Proses ini diulang beberapa kali dengan kombinasi subset yang berbeda, lalu metrik performa dirata-ratakan untuk mendapatkan estimasi yang lebih stabil dan mengurangi risiko overfitting.
Hold-out validation
Hold-out adalah bentuk paling sederhana. Di metode ini, dataset dibagi sekali menjadi train dan test (misalnya 70% untuk pelatihan dan 30% untuk pengujian). Metode ini cepat dan mudah serta cocok untuk dataset besar, tetapi hasilnya sensitif terhadap pembagian dataset karena hanya menggunakan satu pembagian acak sehingga estimasi performa bisa memiliki performa yang tidak stabil.
K-fold cross validation
Ini adalah metode cross-validation yang paling populer. Pada k-fold cross validation, data dibagi menjadi k lipatan (k-fold) berukuran hampir sama/sama besar, lalu proses pelatihan dan pengujian diulang k kali, setiap kali satu fold menjadi test dan sisanya train. Nilai k=5 atau k=10 sering direkomendasikan karena memberi titik temu yang baik antara bias dan varians estimasi performa tanpa beban komputasi berlebihan. Estimasi performanya lebih stabil dan tidak terlalu bergantung pada pembagian data.
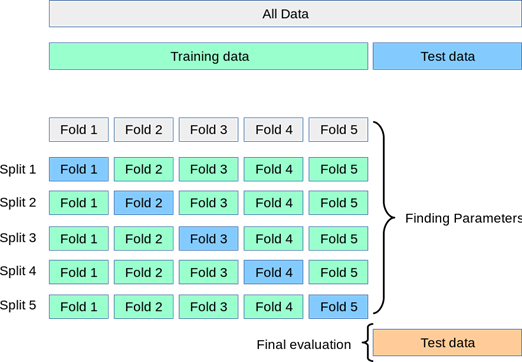
Ilustrasi k-fold cross validation (sumber: https://scikit-learn.org/stable/modules/cross_validation.html)
Stratified k-fold cross validation
Versi khusus dari k-fold untuk data klasifikasi. Stratified k-fold memastikan bahwa proporsi kelas di setiap fold sama dengan proporsi kelas di dataset asli, sehingga sangat penting untuk dataset yang imbalanced. Dengan menjaga keseimbangan ini, model dievaluasi secara lebih adil, terutama untuk kelas minoritas yang rentan terabaikan jika pembagian dilakukan secara acak biasa.
Leave-one-out cross validation (LOOCV)
Leave-one-out adalah kasus khusus k-fold dengan k=N (jumlah sampel), artinya pada setiap iterasi menggunakan satu sampel untuk testing dan sisanya digunakan untuk training. Misal jika dataset punya 100 sampel, maka model akan dilatih sebanyak 100 kali. LOOCV memanfaatkan hampir semua data secara maksimal untuk pelatihan sehingga bias rendah, tetapi sangat mahal secara komputasi dan tidak cocok pada dataset besar atau yang mengandung outlier.
Leave-p-out cross validation (LPOCV)
Leave-p-out mirip dengan LOOCV, tetapi yang ditinggalkan bukan satu data, melainkan
sampel sebagai test di setiap iterasi. Meskipun fleksibel dan secara teoretis sangat kuat, namun jumlah kombinasi yang sangat besar (bisa menyebabkan combinatorial explosion) membuatnya jarang digunakan pada data dengan ukuran moderat hingga besar.
Repeated k-folds cross validation
Seperti k-fold biasa, tetapi proses pembagian (shuffling) dan pelatihan diulang beberapa kali dengan random seed berbeda, lalu skor dari semua run dirata-ratakan. Misalnya jika 10-Fold diulang 5 kali maka akan terbentuk total 50 evaluasi model. Metode ini dapat mengurangi varians estimasi performa lebih jauh dibanding satu kali k-fold, sayangnya biaya komputasi berlipat sesuai jumlah pengulangan.
Shuffle-split aka Monte Carlo cross validation
Shuffle-split (Monte Carlo cross validation) melakukan random train–test split berulang kali, misalnya berkali-kali dengan rasio 80:20, lalu merata-ratakan performanya. Disebut ‘Monte Carlo’ karena pendekatannya berbasis sampling acak berulang (random sampling), mirip dengan metode Monte Carlo di statistik dan fisika numerik. Dalam shuffle split, sebuah sampel bisa jadi beberapa kali ikut test, beberapa kali hanya di train, atau kadang tidak ikut test sama sekali, karena tiap split dibuat dari pengacakan baru yang independent, tidak seperti k-fold klasik yang membagi data menjadi k-fold yang saling eksklusif. Keunggulannya adalah fleksibilitas dalam mengatur proporsi train–test dan jumlah pengulangan, sehingga cocok untuk dataset besar atau skenario ketika k-fold kurang praktis.
Time series cross validation
Dirancang untuk data runtun waktu, pembagian fold harus mempertahankan urutan waktu.Skema yang sering dipakai adalah rolling atau expanding window, yaitu model dilatih pada data masa lalu dan diuji pada data masa depan. Cara ini menghindari ‘kebocoran masa depan’ dan lebih realistis karena mencerminkan cara model digunakan dalam aplikasi dunia nyata seperti forecasting.
Nested cross validation
Nested cross validation digunakan terutama untuk tuning hyperparameter agar menghindari data leakage dan mengukur performa generalisasi tanpa optimisme berlebih. Strukturnya terdiri atas:
- Inner loop untuk pemilihan hyperparameter (misalnya grid search)
- Outer loop untuk evaluasi performa secara independent terhadap tuning tadi
Kelebihan nested crossval adalah sangat ideal untuk unbiased performance estimation. Namun setiap kelebihan pasti memiliki kekurangan, dan kekurangan nested crossval adalah mahalnya biaya komputasi (akibar dari k × k training)
Penulis
Felicia Natania Lingga, S.Kom. — FDP Scholar
Referensi
Cross-Validation: Types and Limitations. BotPenguin. Retrieved from: https://botpenguin.com/glossary/cross-validation on 5 December 2025
June 11, 2025. Understanding Cross-Validation in Machine Vision Systems. Unitx. Retrieved from: https://www.unitxlabs.com/cross-validation-machine-vision-systems/ on 5 December 2025
3.1. Cross-validation: evaluating estimator performance. Scikit Learn. Retrieved from: https://scikit-learn.org/stable/modules/cross_validation.html on 5 December 2025
Brownlee, J. October 4, 2023. A Gentle Introduction to k-fold Cross-Validation. Machine Learning Mastery. Retrieved from: https://machinelearningmastery.com/k-fold-cross-validation/ on 5 December 2025
April 10, 2025. Cross-Validation and Its Types: A Comprehensive Guide. SAI Data Science. Retrieved from: https://saidatascience.com/cross-validation-and-its-types-a-comprehensive-guide/ on 5 December 2025
October 29, 2025. Cross Validation in Machine Learning. Geeks for Geeks. Retrieved from: https://www.geeksforgeeks.org/machine-learning/cross-validation-machine-learning/ on 5 December 2025
Mar 11, 2022. Different Types of Cross-Validations in Machine Learning and Their Explanations. Turing. Retrieved from: https://www.turing.com/kb/different-types-of-cross-validations-in-machine-learning-and-their-explanations on 5 December 2025
Kakujo, R. March 4, 2023. Validasi Silang (Cross Validation). Traffine I/O. Retrieved from: https://io.traffine.com/id/articles/cross-validation on 5 December 2025