
Vector Database: Jantung Aplikasi AI Generatif dan Tools Implementasinya
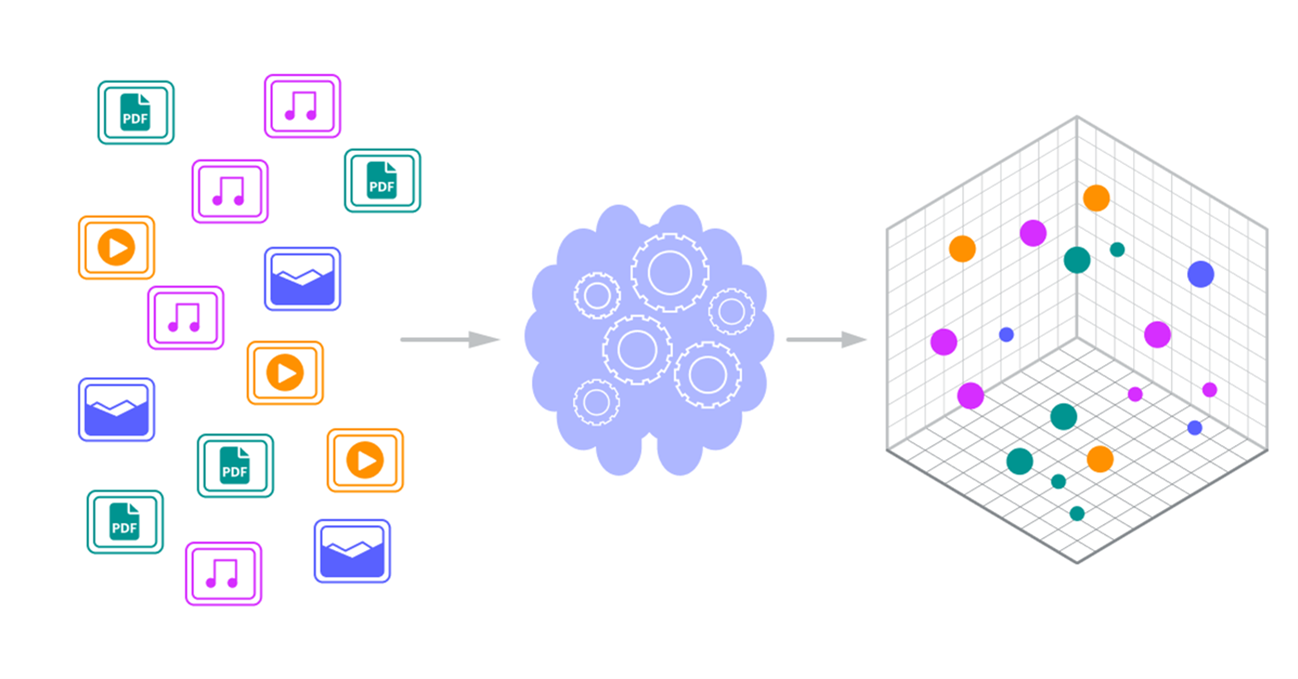
Vector Database adalah jenis sistem manajemen basis data khusus yang dirancang untuk menyimpan, mengindeks, dan mencari vektor data dimensional tinggi (embeddings). Vektor-vektor ini adalah representasi numerik dari data kompleks—seperti teks, gambar, audio, atau video—yang menangkap makna dan hubungan semantik data tersebut.
Teknologi ini menjadi fondasi bagi aplikasi modern yang mengandalkan pemahaman konteks, seperti chatbot canggih dan arsitektur Retrieval-Augmented Generation (RAG).
Source : https://cdn.sanity.io/images/sy1jschh/production/55d6a8baff534e58acd9db3d3fec3514a4354163-1200×628.png?w=3840&q=80&fit=clip&auto=format
Konsep Dasar dan Fungsi Inti
Vektor dan Embeddings
Dalam Kecerdasan Buatan (AI), embedding adalah vektor (larik angka) yang dihasilkan oleh Model Bahasa Besar (LLM) atau model AI lainnya. Vektor ini memetakan item data ke ruang multidimensi, di mana objek dengan makna atau fitur yang serupa akan ditempatkan berdekatan secara geometris.
Pencarian Kesamaan (Similarity Search)
Fungsi utama Vector Database adalah memfasilitasi Pencarian Kesamaan (Similarity Search). Proses ini mengandalkan algoritma Approximate Nearest Neighbor (ANN) untuk mencari vektor terdekat secara cepat, sehingga memungkinkan sistem menemukan data yang bermakna serupa, bukan hanya teks yang sama.
Tools dan Produk Implementasi Vector Database
Implementasi Vector Database dibagi menjadi solusi yang dibangun khusus (dedicated) dan basis data tradisional dengan kemampuan vektor.
Dedicated Vector Databases (Solusi Khusus)
Solusi ini dirancang dari awal untuk mengoptimalkan penyimpanan dan pencarian vektor berdimensi tinggi, seringkali sebagai layanan managed atau open-source:
- Pinecone: Pemimpin pasar, berfokus pada skala dan kinerja sebagai layanan serverless terkelola sepenuhnya.
- Weaviate: Vector database open-source yang unggul dalam pencarian semantik dan mendukung Hybrid Search.
- Milvus / Zilliz: Milvus adalah vector database open-source yang populer dengan kinerja tinggi; Zilliz adalah versi managed service-nya.
- Qdrant: Open-source search engine yang berfokus pada efisiensi dan payload filtering (pemfilteran metadata).
Databases dengan Vector Capabilities (Ekstensi)
Basis data relasional atau NoSQL yang telah menambahkan plugin untuk mendukung fungsionalitas vektor, memungkinkan pengguna memanfaatkan infrastruktur yang sudah ada:
- PostgreSQL (pgvector): Ekstensi yang memungkinkan penyimpanan dan pencarian vektor langsung di RDBMS.
- Redis (Redis Stack): Menggunakan modul RediSearch untuk pencarian vektor yang sangat cepat karena sifatnya in-memory.
- Elasticsearch / OpenSearch: Menambahkan dukungan dense vector untuk kasus penggunaan relevance search dan RAG.
- MongoDB: Menambahkan fitur Vector Search ke platform MongoDB Atlas mereka.
Aplikasi Utama dalam Ekosistem AI
Vector Database sangat penting karena memungkinkan aplikasi AI untuk bergerak melampaui pencocokan kata kunci:
- Retrieval-Augmented Generation (RAG): Mengambil informasi faktual yang relevan dari knowledge base eksternal melalui pencarian vektor, yang kemudian digunakan oleh LLM untuk meningkatkan akurasi respons.
- Pencarian Semantik: Memungkinkan pengguna mencari konten berdasarkan makna yang dimaksud, bukan hanya kata kunci yang eksak.
- Sistem Rekomendasi: Menemukan item yang secara semantik serupa dengan apa yang disukai pengguna.
Penulis
Fiqri Ramadhan Tambunan, S.Kom., M.Kom FDP Scholar
Referensi
| Deskripsi | Judul / Sumber | Tautan |
| Konsep Dasar Embeddings | Efficient Estimation of Word Representations in Vector Space (Paper Word2Vec) | https://arxiv.org/abs/1301.3781 |
| Dokumentasi Pinecone | Pinecone: Vector Database Explained | https://www.pinecone.io/learn/vector-database/ |
| Dokumentasi Weaviate | Weaviate: Vector Index Concepts | https://weaviate.io/developers/weaviate/concepts/vector-index |
| Dokumentasi Milvus | Milvus Documentation: Overview | https://milvus.io/docs/overview.md |
| Dokumentasi pgvector | GitHub: pgvector | https://github.com/pgvector/pgvector |