
PATCHLM: AUTOMATED PROGRAM REPAIR BERBASIS AI
Pada tahun 2024 National Vulnerability Database (NVD) mencatat lebih dari 38.783 Common Vulnerabilities & Exposures (CVE) baru, angka tertinggi sepanjang sejarah, sementara 75% di antaranya menumpuk tanpa diproses karena backlog struktural dan keterbatasan kapasitas analisis manusia. Ledakan jumlah kerentanan ini menciptakan tekanan besar terhadap tim keamanan yang dituntut menambal sistem lebih cepat dari laju eksploitasi. Di tengah jarak kemampuan manusia dan laju kerentanan tersebut, Automated Program Repair (APR) berbasis AI mulai muncul bukan sekadar sebagai alat bantu, tetapi sebagai sebuah kebutuhan.
Salah satu terobosan terbaru adalah PatchLM, sebuah Code Language Model (CLM) yang secara khusus di-fine-tune untuk memperbaiki kerentanan keamanan pada berbagai bahasa pemrograman. Tidak seperti model generative seperti CodeT5 atau CodeLlama, PatchLM mempelajari pola vulnerable → fixed dari commit asli pada repositori yang terkait dengan CVE. Dengan kata lain, PatchLM mempelajari langsung bagaimana para developers memperbaiki bug keamanan, bukan sekadar menebak sintaks yang “terlihat aman”.
Mengapa PatchLM Penting?
APR telah berkembang pesat, tetapi sebagian besar riset sebelumnya hanya berhasil memperbaiki bug umum, bukan kerentanan keamanan. Ada beberapa alasan mengapa hal ini dapat terjadi, yaitu (Bhandari et al., 2025):
1. Dataset kerentanan yang berkualitas sangat sedikit
Mayoritas dataset hanya untuk klasifikasi (mendeteksi bug), bukan untuk fix generation berbasis pasangan vulnerable fix.
2. Perbaikan keamanan bersifat semantik, bukan sekadar sintaktik
Banyak model APR gagal karena hanya fokus pada kesamaan teks, tidak memahami intention perbaikan.
3. Variasi bahasa pemrograman
Sebagian besar model hanya berjalan pada satu bahasa (C/C++, Java). PatchLM justru dilatih pada berbagai bahasa popular, seperti C, C++, Python, Java, PHP, JavaScript, Ruby, Go, C#.
4. APR sebelumnya tidak memanfaatkan CLM modern sepenuhnya
Penelitian PatchLM menegaskan bahwa kemampuan CLM seperti CodeT5 dan CodeLlama belum dimaksimalkan secara domain-specific, padahal mereka sudah sangat distingtif dalam memahami struktur dan semantik kode.
Cara Kerja PatchLM
PatchLM dibangun berdasarkan prinsip sederhana. Jika model bahasa kode dilatih langsung pada pasangan kerentanan dan perbaikannya dari dunia nyata, maka model tersebut akan belajar bukan hanya struktur sintaksis, tetapi juga pola logis dan semantik yang digunakan pengembang untuk memperbaiki celah keamanan. Proses ini dimulai dengan mengumpulkan referensi perbaikan kerentanan dari NVD. Setiap entri CVE biasanya menyertakan tautan yang merujuk pada commit di GitHub, GitLab, atau Bitbucket, yang berisi perubahan kode yang memperbaiki kerentanan tersebut. PatchLM mengekstraksi commit tersebut untuk membentuk dataset berisi pasangan kode rentan (vulnerable snippet) dan kode perbaikan (patched snippet), lengkap dengan konteks bahasa pemrograman dan metadata CVE terkait. Dataset berbasis bukti nyata inilah yang menjadi fondasi utama performa PatchLM karena model tidak dilatih pada data sintetis, melainkan pada patch keamanan yang benar-benar dibuat oleh pengembang profesional ketika menutup kerentanan di produk atau pustaka mereka. Gambar berikut mengilustrasikan alur kerja PatchLM secara keseluruhan, mulai dari pengambilan referensi CVE hingga generasi patch oleh model.
Diagram tersebut menunjukkan bagaimana PatchLM pertama-tama mengumpulkan CVE dari NVD, lalu menelusuri repositori versi kontrol untuk menemukan commit yang memuat perbaikan terhadap CVE terkait. Setelah pasangan vulnerable fix terkumpul, data tersebut diproses menjadi format pelatihan yang konsisten, kemudian digunakan untuk melakukan fine-tuning pada berbagai Code Language Models seperti CodeT5 dan CodeLlama. Fine-tuning inilah yang membedakan PatchLM dari model umum, alih-alih belajar
menghasilkan kode secara generik, model dilatih untuk mengenali pola kerentanan dan menghasilkan patch yang mencerminkan praktik perbaikan yang dilakukan developers. Ketika model telah di-finetune, ia diuji dengan memberikan kode rentan baru dan diminta menghasilkan patch yang semantik dan sintaksisnya sejajar dengan perbaikan yang benar-benar telah terbukti mengatasi kerentanan. Keseluruhan pipeline ini menekankan dua konsep penting (Bhandari et al., 2025).
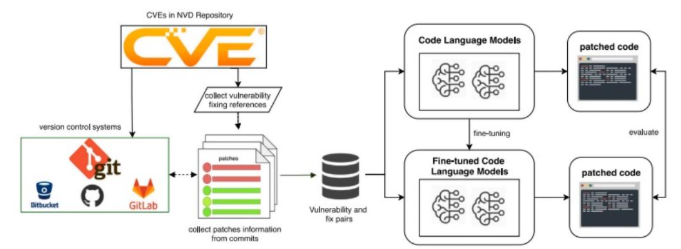
Image Source : https://github.com/SmartSecLab/PatchLM/tree/main
1. Data Realism
Model belajar dari perbaikan keamanan yang faktual, bukan rekayasa
2. Security Intention Alignment
Model memahami tujuan patch, bukan hanya bentuk patch
Dengan desain ini, PatchLM tidak sekadar memproduksi variasi kode yang “terlihat benar”, tetapi berusaha menangkap struktur logis yang menghilangkan jalur eksploitasi seperti input sanitization, boundary checks, atau privilege misconfigurations. Hal inilah yang membuat PatchLM bergerak lebih dekat menuju sistem AI yang mampu berperan sebagai asisten keamanan yang benar-benar fungsional, bukan sekadar generator kode.
Kelebihan dan Kekurangan PatchLM
Meskipun PatchLM menawarkan pendekatan yang inovatif dalam proses perbaikan kerentanan secara otomatis, model ini tetap memiliki sejumlah kekuatan dan keterbatasan yang perlu dipahami untuk menilai kelayakan penerapannya dalam lingkungan nyata. Pendekatan berbasis fine-tuning pada pasangan vulnerable–fixed dari commit memberikan dasar yang kuat untuk menghasilkan patch yang menyerupai praktik pengembang profesional. Namun, seperti sebagian besar CLM, PatchLM masih menghadapi tantangan dalam memahami konteks lintas-file, perilaku runtime, serta keterbatasan dataset yang tersedia. Tabel berikut merangkum kelebihan dan kekurangan utama PatchLM sebagaimana dijelaskan dalam penelitian mereka, sekaligus memberikan gambaran seimbang tentang sejauh mana model ini dapat membantu proses secure software development di masa depan (Bhandari et al., 2025).
Kesimpulan
PatchLM menandai evolusi penting dalam keamanan software karena untuk pertama kalinya, model bahasa kode modern dapat memperbaiki kerentanan secara otomatis dengan akurasi yang mendekati praktik manusia. Melalui fine-tuning pada commit CVE nyata, prompt-engineering yang tepat, dan evaluasi komprehensif, PatchLM menunjukkan bahwa AI dapat membantu menutup gap besar antara jumlah kerentanan dan kapasitas manusia untuk menanganinya. Meskipun masih memiliki keterbatasan dalam memahami konteks semantik penuh dan ketergantungan lintas file, PatchLM memberikan landasan serius bagi masa depan AI-driven secure software development. Ketika organisasi menghadapi backlog CVE dan kekurangan tenaga ahli keamanan, pendekatan seperti PatchLM bukan lagi sekadar inovasi, tetapi kebutuhan strategis.
Penulis :
FDP Scholar – Satriadi Putra Santika, S.Stat., M.Kom.
Referensi :
[1] Bhandari, G., Gavric, N., & Shalaginov, A. (2025). Generating vulnerability security fixes with code language models. Retrieved from https://doi.org/10.1016/j.infsof.2025.107786
[2] Bhandari, G. (2025). PatchLM: Generating vulnerability security fixes with code language models. Retrieved from https://github.com/SmartSecLab/PatchLM/tree/main [3] NIST. (2024). National Vulnerability Database. Retrieved from https://nvd.nist.gov/