
Kuantisasi dalam AI: Cara Membuat Model Pintar Menjadi Lebih Ringan dan Cepat

Perkembangan kecerdasan buatan (AI) semakin pesat, ditandai dengan munculnya model-model besar seperti Large Language Model (LLM) yang memiliki miliaran parameter. Model seperti ini digunakan dalam chatbot modern seperti ChatGPT atau Gemini. Model-model tersebut mampu melakukan tugas kompleks seperti memahami teks, menerjemahkan bahasa, dan menganalisis sentimen. Namun, ukuran dan kompleksitasnya membuat mereka membutuhkan sumber daya komputasi dan memori yang sangat besar.
Model AI modern biasanya menggunakan representasi angka presisi tinggi, seperti 32-bit floating point (FP32), untuk menyimpan bobot dan melakukan perhitungan. Representasi ini memang akurat, tetapi mahal dari sisi memori, kecepatan, dan energi. Sederhananya, komputer menyimpan angka dengan detail yang sangat tinggi, tetapi konsekuensinya ukuran model menjadi besar dan prosesnya lebih berat. Karena itu, menjalankan model besar di perangkat dengan sumber daya terbatas seperti ponsel, perangkat IoT (Internet of Things), atau server kecil menjadi sulit.
Di sinilah kuantisasi (quantization) memainkan peran penting. Kuantisasi adalah teknik yang membuat model AI menjadi lebih ringan dan lebih cepat. Dalam banyak kasus, ukuran model bisa turun drastis, sementara akurasinya tetap hampir sama. Banyak penelitian menunjukkan bahwa kuantisasi merupakan salah satu metode utama untuk mengurangi ukuran model dan biaya komputasi tanpa menurunkan performa secara drastis.
Kuantisasi bukan hanya sekadar trik teknis, melainkan salah satu komponen utama agar AI bisa digunakan secara luas di dunia nyata.
Apa Itu Kuantisasi?
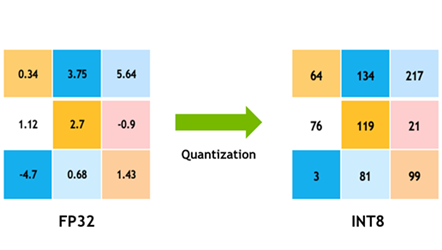
Figure 1. Precision comparison chart for FP32 to INT8 (source: NVIDIA Developer Blog).
Kuantisasi adalah proses mengubah nilai numerik yang memiliki presisi tinggi menjadi bentuk yang memiliki presisi lebih rendah.
Dalam konteks AI dan deep learning, ini berarti mengonversi bobot (weights, yaitu parameter yang menentukan perilaku model) dan nilai aktivasi (activations, yaitu nilai perantara saat model memproses input) dari representasi floating point presisi tinggi misalnya 32-bit floating point (FP32) ke representasi rendah seperti 16-bit floating point (FP16) atau 8-bit integer (INT8). Pada beberapa pendekatan lanjutan, bahkan digunakan presisi yang lebih rendah lagi, meskipun biasanya memerlukan teknik tambahan agar akurasi tetap terjaga.
Secara sederhana, jika sebelumnya sebuah angka disimpan dengan 32 bit, setelah kuantisasi angka tersebut hanya membutuhkan 8 bit. Akibatnya, ukuran data menjadi jauh lebih kecil.
Tujuan utama dari kuantisasi adalah mengurangi ukuran model, mempercepat proses prediksi (inference), dan menurunkan konsumsi energi tanpa mengorbankan akurasi secara signifikan.
Mengapa Kuantisasi Dibutuhkan?
Sebagian besar model AI modern menyimpan parameternya dalam format floating point dengan presisi tinggi. Representasi ini memberikan akurasi yang baik, tetapi membutuhkan sumber daya berikut:
- Memori yang lebih besar untuk menyimpan bobot dan aktivasi
- Komputasi yang lebih berat saat melakukan prediksi
- Konsumsi energi yang lebih tinggi
Dengan kuantisasi:
- Ukuran model bisa menjadi sekitar empat kali lebih kecil (misalnya dari FP32 ke INT8)
- Proses prediksi menjadi lebih cepat
- Konsumsi daya berkurang secara signifikan
Karena itu, kuantisasi sangat penting untuk menjalankan AI di ponsel, perangkat IoT, dan sistem real-time dengan sumber daya terbatas.
Cara Kerja Kuantisasi di Model AI
Proses kuantisasi bisa dilakukan dalam beberapa cara tergantung pada kebutuhan model dan konteks penggunaannya. Dua pendekatan utama adalah:
1. Post-Training Quantization (PTQ)
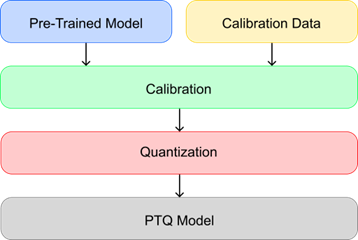
Figure 2. PTQ Diagram.
Pada metode ini, kuantisasi dilakukan setelah model selesai dilatih. Bobot model langsung dikonversi ke presisi rendah tanpa pelatihan ulang. Metode ini cepat dan mudah diterapkan, tetapi terkadang dapat menurunkan akurasi karena model tidak pernah “belajar” menghadapi penurunan presisi ini selama pelatihan.
2. Quantization-Aware Training (QAT)
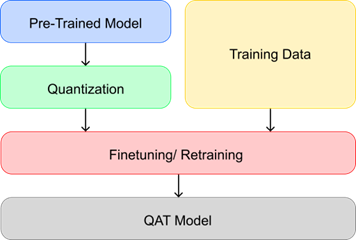
Figure 3. QAT Diagram.
Dalam pendekatan ini, penurunan presisi disimulasikan selama proses pelatihan model. Model beradaptasi dengan angka presisi rendah sejak awal. Pendekatan ini membutuhkan akses ke data asli dan prosesnya lebih kompleks, tetapi membantu menjaga performa model dengan hasil yang lebih stabil.
Manfaat Kuantisasi
Ada beberapa keuntungan signifikan dari penggunaan kuantisasi dalam model AI:
- Ukuran Model Lebih Ringan
Dengan bit yang lebih sedikit, ukuran model berkurang drastis. - Performa Lebih Cepat
Operasi dengan angka sederhana (integer) umumnya lebih cepat daripada operasi floating point yang lebih kompleks. Hal ini membuat proses prediksi berjalan lebih cepat. - Konsumsi Energi Lebih Efisien
Komputasi yang lebih ringan berarti konsumsi daya lebih rendah, yang sangat penting untuk perangkat dengan sumber daya terbatas seperti ponsel, perangkat IoT, maupun server.
Tantangan dan Risiko Kuantisasi
Walaupun kuantisasi menawarkan berbagai keuntungan, kuantisasi juga memiliki tantangan:
- Penurunan Akurasi
Karena representasi data menjadi lebih sederhana berarti ada kemungkinan model kehilangan sedikit akurasi. Efek ini disebut quantization error, yaitu kesalahan kecil akibat pembulatan angka ke presisi yang lebih rendah. - Dukungan Perangkat Keras dan Perangkat Lunak
Tidak semua perangkat keras atau framework AI mendukung semua jenis kuantisasi secara optimal, sehingga hasilnya dapat berbeda antar platform. - Kebutuhan Pengaturan dan Validasi
Metode seperti QAT membutuhkan penyesuaian pelatihan yang lebih teliti dan proses validasi tambahan untuk memastikan akurasi tetap dapat diterima setelah kuantisasi.
Contoh Penerapan Kuantisasi
Kuantisasi banyak digunakan ketika model yang kompleks harus dijalankan di lingkungan terbatas, misalnya:
- Aplikasi ponsel untuk prediksi gambar atau teks secara lokal tanpa server cloud
- Perangkat IoT yang tidak memiliki GPU besar
- Layanan real-time yang membutuhkan respons cepat
Dengan kuantisasi, model besar dapat “diperkecil” menjadi format yang sesuai untuk perangkat semacam ini, memperluas penggunaan AI di banyak bidang.
Kesimpulan
Kuantisasi merupakan teknik optimasi yang sangat penting dalam pengembangan dan penerapan AI modern. Dengan menurunkan presisi bobot dan aktivasi, ukuran model dan kebutuhan komputasi dapat dikurangi secara signifikan, sering kali tanpa penurunan performa yang berarti.
Teknik ini memungkinkan AI digunakan pada perangkat dengan sumber daya terbatas, sekaligus membantu menekan biaya dan konsumsi energi. Karena itu, kuantisasi bukan hanya alat optimasi tetapi juga kunci utama dalam membawa AI dari laboratorium ke dunia nyata.
Referensi
- Bhandare, A., Sripathi, V., Karkada, D., Menon, V. V., Choi, S., Datta, K., & Saletore, V. A. (2019). Efficient 8-bit quantization of transformer neural machine language translation model. arXiv. https://arxiv.org/abs/1906.00532
- Gholami, A., Kim, S., Dong, Z., Yao, Z., Mahoney, M. W., & Keutzer, K. (2021). A survey of quantization methods for efficient neural network inference. arXiv. https://arxiv.org/abs/2103.13630
- Li, Z., Li, H., & Meng, L. (2023). Model compression for deep neural networks: A survey. Computers, 12(3), Article 60. https://doi.org/10.3390/computers12030060
- Nagel, M., Fournarakis, M., Amjad, R. A., Bondarenko, Y., van Baalen, M., & Blankevoort, T. (2021). A white paper on neural network quantization. arXiv. https://arxiv.org/abs/2106.08295
- Wu, H., Judd, P., Zhang, X., Isaev, M., & Micikevicius, P. (2020). Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv. https://arxiv.org/abs/2004.09602
- (2025). Quantization in deep learning. https://www.geeksforgeeks.org/deep-learning/quantization-in-deep-learning/
Penulis
- 2702368223 – Helena Aurelia Sanjaya (Computer Science)
- 2702229932 – Bertrand Geraldo Tjahyadi (Computer Science)
- 2702280352 – Marvel Collin (Computer Science)
- D3690 – Prof. Derwin Suhartono