
Regular Expression
Text dapat diartikan sebagai rentetan dari karaker-karakter yang memiliki arti. Salah satu proses dalam memahami/mengolah isi text dalam sebuah dokumen adalah dengan memproses karakter-karakter tersebut. Contohnya adalah fitur spell-checker yang tersedia pada Microsoft Word dimana dapat membantu memberikan penanda untuk kata-kata yang salah ketik, atau tidak sesuai format, seperti tanda titik atau koma yang jika diberikan spasi maka pembenaran yang dilakukan adalah dengan menghapus spasi tersebut. Pengecekan tersebut berada pada level karakter.
Demikian juga untuk pencarian sebuah kata/pola tertentu pada sebuah dokumen text dapat dilakukan dengan menggunakan Regular Expression. Regular Expression (RE) adalah sebuah notasi yang dapat digunakan untuk mendeskripsikan pola dari kata yang ingin dicari. Sebagai contoh jika RE yang dibuat adalah ‹‹ nlp ›› maka kata yang akan cocok dengan pola ini hanya kata nlp (sama persis dengan yang ada pada RE). Namun demikian regular expression juga menyediakan beberapa special karakter yang dapat digunakan untuk mencocokan karakter dengan pola-pola tertentu. Perlu diingat bahwa RE adalah case sensitive.
- Wildcard
Simbol titik “.” Disebut dengan wildcard dimana tanda ini dapat cocok dengan satu karakter apapun. Contohnya jika RE ‹‹ n.p ››maka kata yang akan cocok dengan RE tersebut bisa berupa nlp, nap, nup, n3p, n0p, dst.
- Optionality
Dengan menggunakan symbol tanda tanya “?” untuk menandakan bahwa regular expression yang diberikan sebelum symbol tersebut bersifat optional. Contohnya adalah RE ‹‹ colou?r ›› maka kata yang dapat cocok dengan pola tersebut adalah colour dan color (dimana u bersifat opsional). Sama juga dengan RE ‹‹ e-?mail ›› dimana kata yang dapat cocok adalah e-mail dan email.
- Repeatability
Ada dua jenis perulangan yang dapat digunakan, yaitu dengan menggunakan tanda “+” dan “*”. Tanda “+” menandakan bahwa RE yang diberikan sebelum symbol tersebut dapat diulang. Sebagai contoh ‹‹ coo+l ›› dapat cocok dengan kata cool, coool, coool, dst. Contoh lainnya adalah dalam RE ‹‹ .+ed ›› sama dengan mencari kata yang berakhiran dengan kata “ed”. Sedangkan tanda “*” menandakan bahwa RE yang diberikan sebelum symbol tersebut bersifat opsional atau dapat berulang. Jika menggunakan contoh RE diatas yaitu ‹‹ coo*l ›› maka kata yang dapat cocok adalah kata col, cool, coool, dst. Contoh lainnya adalah kata ‹‹ .* oo .* ›› berarti mencari semua kata yang terdiri dari minimal 2 karakter o.
- Choice
Dengan menggunakan symbol kurung siku buka dan tutup “[ ]” maka pola kata yang akan cocok akan terbatas pada RE yang akan diberikan didalam symbol tersebut. Contohnya adalah ‹‹n[a,l,o]p›› dimana berarti kata yang dapat cocok adalah nap, nlp, dan nop saja. - Range
Tanda “-“ digunakan untuk menunjukkan suatu range, misalnya kata yang dapat cocok dari RE ‹‹n[a-z]p›› adalah semua kombinasi dari huruf a-z (nap, nbp, ncp, dst.). Contoh RE untuk mencari kata dimana kata tersebut dimulai dengan huruf capital adalah: ‹‹ [A-Z][a-z]*›› - Complementation
Tanda “^” digunakan untuk membuat makna kebalikannya (negasi). Contohnya RE ‹‹ [aiueo] ›› adalah RE untuk menghasilkan karakter vocal, tetapi jika kita menggunakan tanda tersebut menjadi ‹‹ ^[aiueo] ›› maka karakter yang dihasilkan adalah karakter lain selain a, i, u, e, o, atau dengan kata lain yaitu karakter konsonan saja. - Common special symbol
Tanda “^” dan “$” digunakan untuk mencocokan awalan dan akhiran dari sebuah baris di dalam file. Tanda “^” memiliki dua arti. Bila tanda tersebut digunakan menjadi sebuah awalan pada class character seperti pada nomor 6 maka tanda tersebut berarti negasi, selain itu tanda tersebut berarti menandakan awal dari sebuah baris.
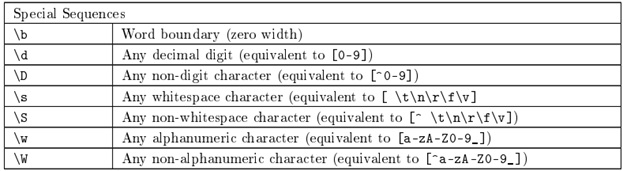
Contohnya jika RE ‹‹ ^ [A-Za-z]+ ›› berarti mencari disetiap awal baris kata yang terdiri dari satu atau lebih karakter A-Z (baik huruf besar ataupun huruf kecil). - Other Special character
Referensi :
1. Bird, S., & Klein, E. (2006). Regular expressions for natural language processing. University of Pennsylvania.