
Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) adalah model probabilistik generatif dari koleksi data diskrit seperti korpus teks. Ide dasarnya adalah bahwa dokumen direpresentasikan sebagai campuran acak atas topik laten (tidak terlihat).
LDA merupakan model Bayesian hirarki tiga tingkat, di mana setiap item koleksi dimodelkan sebagai campuran terbatas atas serangkaian set topik. Setiap topik dimodelkan sebagai campuran tak terbatas melalui set yang mendasari probabilitas topik. Dalam konteks pembuatan model teks, probabilitas topik memberikan representasi eksplisit dari sebuah dokumen
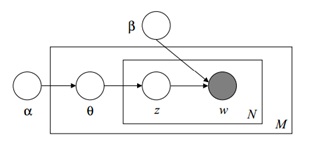
LDA mengasumsikan proses generatif berikut untuk setiap w dokumen korpus D:

Ide dasar dari LDA yaitu bahwa dokumen terdiri dari beberapa topik. LDA adalah model statistik dari kumpulan dokumen yang berusaha untuk merepresentasikan ide tersebut. Proses LDA bersifat generatif melalui imaginary random process pada model yang mengasumsikan bahwa dokumen berasal dari topik tertentu. Setiap topik terdiri dari distribusi kata-kata.
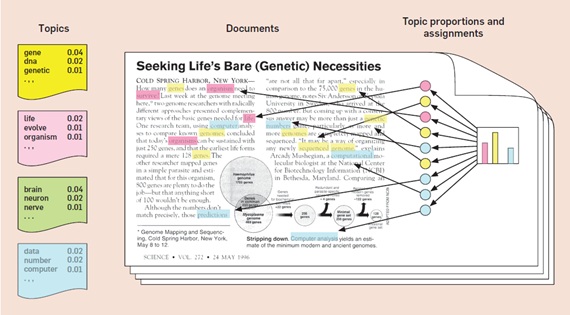
Blei menentukan topik untuk menjadi distribusi melalui kosakata tetap. Misalnya, topik genetika memiliki kata-kata tentang genetika dengan probabilitas yang tinggi dan topik biologi evolusioner memiliki kata-kata tentang biologi evolusioner dengan probabilitas yang tinggi. Blei berasumsi bahwa topik yang ditentukan sebelum data telah digenerasi.
Setiap dokumen di dalam koleksi, dihasilkan kata-kata dalam suatu proses dengan 2 tahap:
- Secara acak memilih sebuah distribusi topik
- Untuk setiap kata dalam dokumen:
-
-
- Secara acak memilih sebuah topik dari distribusi topik pada langkah pertama.
- Secara acak memilih sebuah kata dari distribusi kosakata yang sesuai.
-
Tujuan topic modeling yaitu menentukan topik secara otomatis dari sekumpulan dokumen. Dokumen yang diteliti memiliki struktur tersembunyi (hidden structure) berupa topik, distribusi topik per dokumen, dan penentuan topik per kata dalam setiap dokumen. Topic modeling menggunakan kumpulan dokumen tersebut untuk inference struktur topik tersembunyi. Jumlah topik yang akan dihasilkan telah ditentukan sebelum proses topic modeling dilaksanakan. Penentuan jumlah topik sangat berpengaruh pada kualitas model topik LDA dan biasanya dilakukan berdasarkan eksperimen antara 30-300 topik untuk menentukan model yang baik.

Setelah model topik LDA dibuat, sebuah dokumen atau artikel dapat ditentukan distribusi topiknya yang mendeskripsikan kumpulan kata dalam dokumen. Sisi kanan dari Gambar 4 menunjukkan daftar topik dan lima belas kata dengan distribusi tertinggi untuk masing-masing topik.
LDA menggunakan asumsi bag of words, yaitu urutan kemunculan kata dalam dokumen diabaikan. Asumsi ini diakui tidak realistis, akan tetapi beralasan karena tujuan LDA hanya untuk menemukan struktur semantik teks.
Referensi:
- David M. Blei, Andrew Y. Ng,, & Michael I. Jordan (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research 3 (2003) 993-1022.
- David M. Blei (2012). Probabilistic Topic Models. Communications of the ACM, April 2012, Vol. 55 No. 4, Pages 77-84.