
Mengenal Automatic Speech Recognition: Cara Komputer Memahami Ucapan Manusia

Source: Midjourney
Automatic Speech Recognition (ASR) atau pengenalan ucapan otomatis adalah teknologi yang memungkinkan komputer mengubah suara manusia menjadi teks. Dari Siri, Alexa, hingga sistem navigasi mobil, ASR menjadi fondasi utama interaksi manusia–mesin berbasis suara. Dengan kemajuan Deep Learning dan Neural Networks, ASR kini jauh lebih akurat dan adaptif terhadap berbagai bahasa, dialek, dan lingkungan bising.
Menurut Ahlawat et al. (2025), ASR telah berevolusi dari pendekatan berbasis statistik seperti Hidden Markov Model (HMM) menuju arsitektur end-to-end (E2E) dengan Transformer dan Conformer, yang dapat belajar langsung dari data suara tanpa memerlukan fitur linguistik manual.
Konsep Dasar dan Cara Kerja ASR
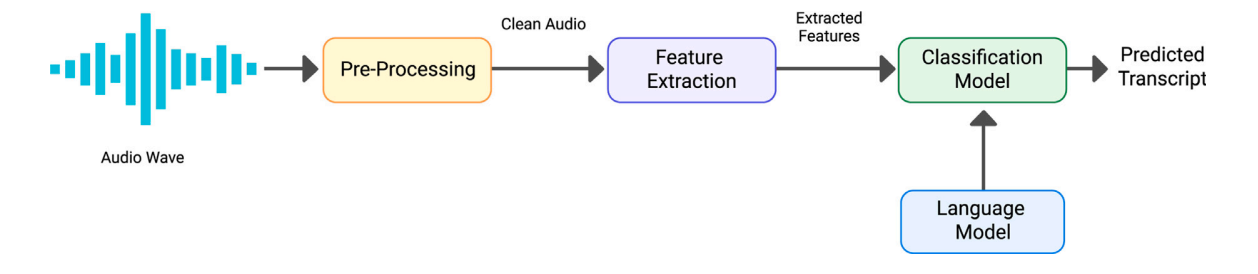
Sumber: Arsitektur ASR Tradisional (Papastratis, 2021)
Secara sederhana, ASR berfungsi untuk “mendengar” suara manusia, mengenali pola akustiknya, lalu menuliskannya menjadi kata. Namun proses di baliknya melibatkan beberapa tahap penting:
- Pre-Processing
Pada tahap awal, sinyal suara dibersihkan dari kebisingan, gema, atau gangguan lainnya. Sistem akan menyesuaikan volume dan panjang rekaman agar semua data suara memiliki format yang seragam.
- Feature Extraction
ASR tidak membaca suara secara langsung, tetapi mengubahnya menjadi representasi numerik yang disebut speech features. Teknik yang paling umum digunakan adalah Mel Frequency Cepstral Coefficients (MFCC) dan Mel Spectrogram, yang merepresentasikan frekuensi suara dalam bentuk visual seperti “sidik jari” suara.
- Acoustic & Language Modeling
- Acoustic model menganalisis hubungan antara sinyal suara dan fonem (bunyi dasar dalm bahasa).
- Language model memprediksi susunan kata yang paling mungkin berdasarkan konteks linguistik. Kedua model ini bekerja sama untuk meminimalkan kesalahan dalam mengenali kata yang mirip bunyinya.
- Decoding & Output
Setelah sistem memperkirakan hasil terdekat dari sinyal suara, hasil akhir ditransformasikan menjadi teks. Pada tahap ini, algoritma seperti beam search digunakan untuk memilih urutan kata yang paling logis.
Evolusi Teknologi ASR
- Generasi Awal: Model Statistik
ASR awal menggunakan pendekatan matematis berbasis Hidden Markov Model (HMM) dan Gaussian Mixture Model (GMM). Metode ini bekerja dengan mencocokkan pola suara terhadap database fonetik, namun kurang fleksibel terhadap variasi aksen, intonasi, dan lingkungan bising.
- Era Deep Learning
Perkembangan Deep Neural Networks (DNN) dan Recurrent Neural Networks (RNN) merevolusi ASR. Model ini mampu “mengingat” urutan waktu dalam ucapan, memungkinkan sistem mengenali kalimat panjang atau intonasi alami. Arsitektur seperti Long Short-Term Memory (LSTM) dan Gated Recurrent Unit (GRU) membantu sistem memahami konteks percakapan.
- Transformer dan End-to-End Models
Model modern seperti Transformer menggunakan mekanisme self-attention yang dapat memahami hubungan antar kata dalam konteks global, bukan hanya urutan waktu. Pendekatan ini membuat proses pelatihan lebih cepat dan akurat. Arsitektur Conformer bahkan lebih maju menggabungkan keunggulan CNN (untuk pola lokal) dan Transformer (untuk konteks global). Hasilnya, model ini mencapai Word Error Rate (WER) di bawah 3% dalam pengujian dataset besar seperti LibriSpeech dan Common Voice.
- Era Self-Supervised dan Multilingual
Model-model mutakhir seperti Wav2Vec 2.0, HuBERT, dan Whisper memperkenalkan konsep self-supervised learning yaitu model belajar langsung dari data suara tanpa memerlukan transkripsi manual. Whisper, misalnya, dilatih menggunakan lebih dari 680.000 jam audio multibahasa, sehingga mampu mengenali aksen, bahasa, bahkan kebisingan lingkungan secara alami.
Dataset yang Digunakan dalam Pengembangan ASR
Akurasisistem pengenalan suara sangat bergantung pada jumlah dan variasi data yang digunakan untuk melatih model. Beberapa dataset besar yang sering digunakan antara lain:
- LibriSpeech: 1000 jam bacaan buku berbahasa Inggris.
- Common Voice: Proyek Mozilla dengan lebih dari 18.000 jam data dari 112 bahasa.
- TED-LIUM: 452 jam rekaman pidato TED Talks dengan transkrip lengkap.
- VoxPopuli: 400.000 jam audio dari 23 bahasa Eropa.
- Dhwani dan Shrutilipi: Kumpulan data besar untuk bahasa-bahasa India.
Dataset ini memungkinkan peneliti melatih model multibahasa yang dapat memahami konteks lintas budaya dan logat.
Tantangan yang Masih Dihadapi
Meski canggih, ASR masih menghadapi tantangan besar:
- Aksen dan dialek lokal: Bahasa dengan banyak variasi fonetik sering sulit dikenali.
- Kebisingan lingkungan: Sistem kadang salah menafsirkan kata dalam kondisi ramai.
- Keterbatasan data bahasa minoritas: Banyak bahasa dunia belum memiliki cukup data pelatihan.
- Privasi dan etika: Pengumpulan data suara menimbulkan pertanyaan tentang keamanan dan persetujuan pengguna.
Untuk mengatasi hal ini, penelitian kini berfokus pada model multilingual end-to-end dan transfer learning yang memungkinkan pelatihan lintas bahasa dan domain dengan data terbatas.
Kesimpulan
Automatic Speech Recognition bukan lagi sekadar fitur tambahan ia telah menjadi inti komunikasi antara manusia dan mesin. Dari telepon genggam hingga mobil pintar, ASR mengubah cara kita berinteraksi dengan teknologi. Melalui kombinasi Deep Learning, Transformer, dan Self-Supervised Learning, teknologi ini kini mampu memahami bahasa manusia dengan presisi yang menakjubkan. Masa depan ASR akan membawa kita lebih dekat pada komunikasi yang benar-benar alami tanpa layar, tanpa tombol, hanya dengan suara.
Penulis:
Samson Ndruru, S.Kom., M.Kom.
Daftar Pustaka:
- Ahmad, Z. (2022, May 16). Introduction to Automatic Speech Recognition. https://syrian.medium.com/introduction-to-automatic-speech-recognition-14f1a10704e6
- Doshi, K. (2021, March 25). Audio Deep Learning Made Simple: Automatic Speech Recognition (ASR), How it Works. Towards Data Science. https://towardsdatascience.com/audio-deep-learning-made-simple-automatic-speech-recognition-asr-how-it-works-716cfce4c706
- “What is ASR & how do speech recognition models work?” (2024, March 21). Gladia. https://www.gladia.io/blog/how-do-speech-recognition-models-work
- Zajechowski, M. (2020, June 6). Automatic Speech Recognition (ASR) Software — An Introduction. Medium (UsabilityGeek). https://medium.com/usabilitygeek/automatic-speech-recognition-asr-software-an-introduction-824390b9282d
- Kincaid, J. (2018, July 12). A Brief History of ASR: Automatic Speech Recognition. Medium (Descript Blog). https://medium.com/descript/a-brief-history-of-asr-automatic-speech-recognition-b8f338d4c0e5