
4 Kesalahan Umum dalam Mengintepretasikan Confusion Matrix
Akurasi tinggi (di atas 90%) seringkali menjadi tolok ukur keberhasilan pelatihan model, mengesankan bahwa model telah selesai dengan baik. Saat model ini diimplentasikan dan dijadikan landasan untuk membuat keputusan, modelnya tidak sesuai ekspektasi, mengecewakan, bahkan tidak berguna. Mungkin ada kesalahan yang terlewatkan oleh Anda. Berikut 4 kesalahan dalam mengintepretasikan Confusion Matrix dan matriks turunannya:
1. Terlalu Mengandalkan Akurasi (The Accuracy Trap)
Dalam konteks pengukuran, alat tes darah (misalnya tes GCU), timbangan digital, termometer, atau GPS, fokus pertanyaannya mengarah pada akurasi alat tersebut tapi tidak dengan presisi-nya. Kecenderungan mementingkan akurasi telah membentuk pemikiran banyak orang. Namun dalam konteks data science khususnya dalam mengevaluasi model machine learning, prioritisasi akurasi dapat menyesatkan.
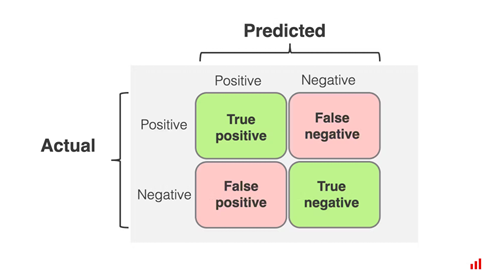

Rumus dari akurasi adalah rasio benar banding total keseluruhan data. Rumus ini tidak memberikan informasi mengenai “jenis” prediksi yang salah. Jenis kesalahan prediksi dapat dibedakan menjadi 2: False Positive dan False Negative.
False Positive: hal yang salah diprediksi sebagai benar
False Negative: hal yang benar diprediksi sebagai salah
Akurasi hanya bisa diAndalkan ketika konsekuensi risikonya sama, false positive tidak lebih berbahaya daripada false negative, dan sebaliknya.
2. “False ≠ False”: False Positives (FP) dan False Negatives (FN)
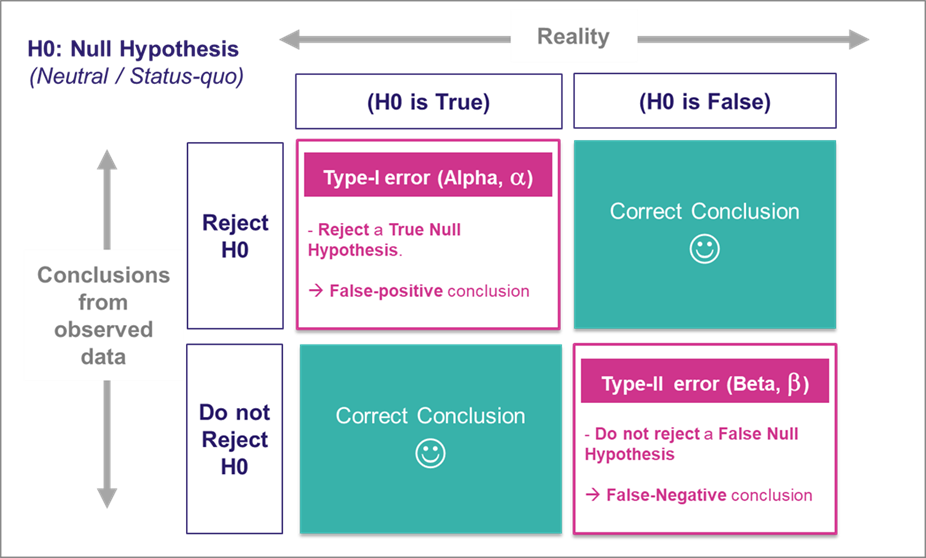
Kesalahan berikutnya yang paling sering adalah secara interinsik menganggap False Positive dan False Negative adalah hal yang sama. Padahal, dalam dunia finansial, atau medis kedua jenis kesalahan tersebut tidak sama nilainya. Keduanya memiliki kata “false” (salah), tapi sudut pAndang yang digunakan berbeda, yang satu menilai dari data aktual/kenyataan, yang satu menilai dari hasil prediksi. Gagal membedakan false positive dan false negative secara intuitif akan membuat kebingungan antara precision dan recall.
Dalam statistik khususnya uji hipotesis, memiliki konsep yang sama yaitu Types of Error: Type I Error dan Type II Error. Type I Error (menolak asumsi awal yang benar) dan Type II Error (menerima asumsi awal yang salah). Type I Error setara dengan False Positive dan Type II Error setara dengan False Negative. Konsepnya mirip dengan confusion matrix, karena adanya sudut pAndang aktual dan asumsi/hipotesis.
3. Tidak Memperhatikan Imbalanced Dataset
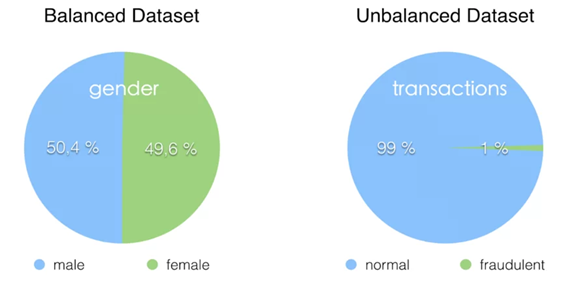
Ilustrasi ini sudah umum dalam kalangan/keilmuan data science, yaitu fraudulent case/kasus penipuan. Bayangkan kasus penipuan hanya ada 1% dari seluruh transaksi, artinya 99% transaksi sah. Bias akurasi terhadap mayoritas bisa terjadi karena data transaksi sah sering muncul.
Model yang tidak tidak melihat datanya pun bisa memprediksi 100% transaksi sebagai transaksi sah, dan tetap memiliki Akurasi 99%.
Tapi jika dilihat dari perspektif 1% transaksi yang menipu, model tersebut gagal memprediksi semua kasus penipuan, padahal tujuan dari model ini adalah memprediksi kasus yang menipu (Fraud).
4. Salah konteks = salah matriks
Setelah menyadari bahwa Akurasi 99% adalah ilusi, kesalahan selanjutnya adalah gagal menerjemahkan risiko bisnis ke dalam metrik yang tepat. Masalahnya bukan lagi apakah model dapat mendeteksi fraud, tetapi konsekuensi mana yang lebih mahal untuk ditanggung—melewatkan fraud atau membuang waktu investigasi.
Masih dengan konteks bisnis perbankan, risiko terbesar adalah terjadinya False Negative (FN), kondisi dimana model memprediksi pemohon sebagai aman yang padahal berisiko gagal bayar. Keputusan ini, terutama model ini diterapkan dalam skala masif, akan merugikan perusahaan perbankan dalam jumlah besar.
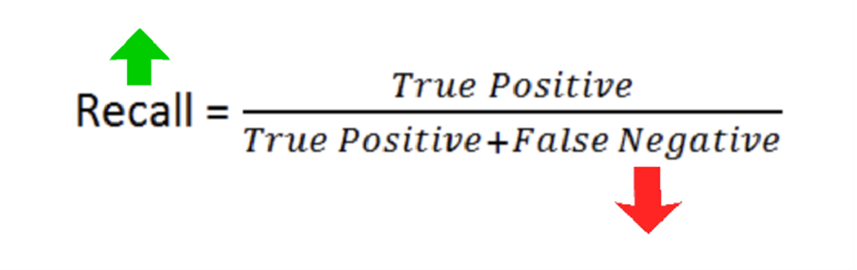
Oleh karena itu, tugas utama dari Data Scientist adalah meminimalkan false negative, dan metrik kunci yang harus dimaksimalkan adalah recall.
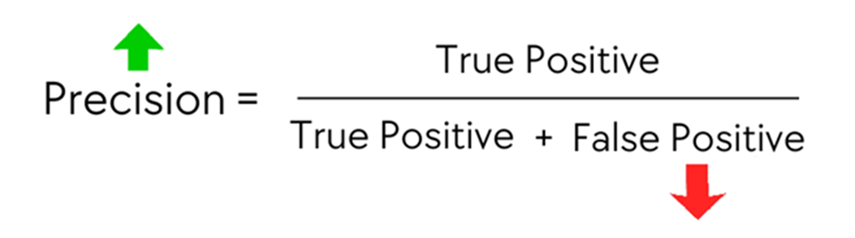
Sebaliknya, jika risiko terbesar dalam bisnis adalah false positive, maka metrik yang dimaksimalkan precision.
Kesimpulan
Pada akhirnya, intepretasi yang tepat atas confusion matrix bukan hanya tentang angka, tetapi juga memahami konsekuensinya jika memilih salah satu matrik. Pemilihan subuah matriks berarti ada hal yang harus dikorbankan, mengorbankan suatu hal setelah mempertimbangkan bahwa konsekuensinya bisa ditanggung adalah Keputusan yang bijak dan efisien dalam bisnis.
Penulis: Tsui Tin Lun
Referensi: