
Searching: Uninformed & Informed
Searching adalah mekanisme pemecahan masalah yang paling umum di dalam kecerdasan buatan. Di dalam permasalahan-permasalahan kecerdasan buatan, urutan langkah-langkah yang dibutuhkan untuk memperoleh solusi merupakan suatu isu yang penting untuk diformulasikan. Hal ini harus dilakukan dengan mengidentifikasikan proses try and error secara sistematis pada eksplorasi setiap alternatif jalur yang ada.
Algoritma searching di dalam kecerdasan buatan yang umumnya dikenal adalah
- Uninformed Search Algorithm
Algoritma yang tidak memberikan informasi tentang permasalahan yang ada, hanya sebatas definisi dari algoritma tersebut.
- Informed Search Algorithm
Walaupun dengan menggunakan Uninformed Search Algorithm, banyak permasalahan dapat dipecahkan, namun tidak semuanya dari algoritma tersebut dapat menyelesaikan masalah dengan efisien
Uninformed Search Algorithm
Uninformed Search sering disebut juga dengan Blind Search. Istilah tersebut menggambarkan bahwa teknik pencarian ini tidak memiliki informasi tambahan mengenai kondisi diluar dari yang disediakan oleh definisi masalah. Yang dilakukan oleh algoritma ini adalah melakukan generate dari successor dan membedakan goal state dari non-goal state. Pencarian dilakukan berdasarkan pada urutan mana saja node yang hendak di-expand.
- Breadth First Search (BFS)
Pencarian dengan Breadth First Search menggunakan teknik dimana langkah pertamanya adalah root node diekspansi, setelah itu dilanjutkan semua successor dari root node juga di-expand. Hal ini terus dilakukan berulang-ulang hingga leaf (node pada level paling bawah yang sudah tidak mempunyai successor lagi). 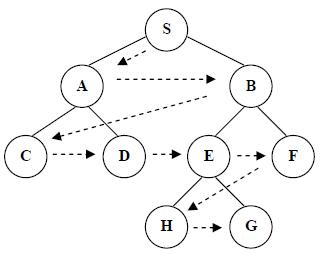
Gambar 1 Penelusuran Ekspansi Node pada Breadth First Search
- Uniform Cost Search (UCS)
Pencarian dengan Breadth First Search akan menjadi optimal ketika nilai pada semua path adalah sama. Dengan sedikit perluasan, dapat ditemukan sebuah algoritma yang optimal dengan melihat kepada nilai tiap path di antara node-node yang ada.
Selain menjalankan fungsi algoritma BFS, Uniform Cost Search melakukan ekspansi node dengan nilai path yang paling kecil. Hal ini bisa dilakukan dengan membuat antrian pada successor yang ada berdasar kepada nilai path-nya (node disimpan dalam bentuk priority queue).
- Depth First Search (DFS)
Teknik pencarian dengan Depth First Search adalah dengan melakukan ekspansi menuju node yang paling dalam pada tree. Node paling dalam dicirikan dengan tidak adanya successor dari node itu. Setelah node itu selesai diekspansi, maka node tersebut akan ditinggalkan, dan dilakukan ke node paling dalam lainnya yang masih memiliki successor yang belum diekspansi. 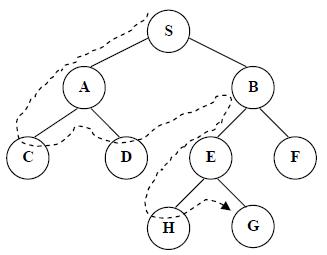
Gambar 2 Penelusuran Ekspansi Node pada Depth First Search
- Depth Limited Search
Pencarian menggunakan DFS akan berlanjut terus sampai kedalaman paling terakhir dari tree. Permasalahan yang muncul pada DFS adalah ketika proses pencarian tersebut menemui infinite state space. Hal ini bisa diatasi dengan menginisiasikan batas depth pada level tertentu semenjak awal pencarian. Sehingga node pada level depth tersebut akan diperlakukan seolah-olah mereka tidak memiliki successor.
- Iterative Deepening Depth First Search
Iterative deepening search merupakan sebuah strategi umum yang biasanya dikombinasikan dengan depth first tree search, yang akan menemukan berapa depth limit terbaik untuk digunakan. Hal ini dilakukan dengan secara menambah limit secara bertahap, mulai dari 0,1, 2, dan seterusnya sampai goal sudah ditemukan.
6. Bidirectional Search
Pencarian dengan metode bidirectional search adalah dengan menjalankan dua pencarian secara simultan, yang satu dikerjakan secara forward dari initial state menuju ke goal, sedangkan yang satu lagi dikerjakan secara backward mulai dari goal ke initial state. Yang kemudian diharapkan bahwa kedua pencarian itu akan bertemu di tengah-tengah.
Informed Search Algorithm
Informed Search sering disebut juga dengan Heuristic Search. Pencarian dengan algoritma ini menggunakan knowledge yang spesifik kepada permasalahan yang dihadapi disamping dari definisi masalahnya itu sendiri. Metode ini mampu menemukan solusi secara lebih efisien daripada yang bisa dilakukan pada metode uninformed strategy.
Pada pencarian dengan menggunakan metode Uniform Cost Search (salah satu bagian dari Uninformed Search Algorithm), kita membandingkan nilai pada path yang ada, dan kemudian akan melakukan ekspansi pertama kali pada path dengan nilai yang terkecil. Nilai path ini biasanya dilambangkan dengan g(n). Lebih lanjut lagi dari metode pencarian tersebut, pada Informed Search Algorithm, kita akan mengenal nilai estimasi (prediksi) dari satu node ke node yang lainnya. Nilai estimasi ini biasanya dilambangkan dengan h(n). Jika n adalah goal node, maka nilai h(n) adalah nol.
- Greedy Best First Search
Metode pencarian ini melakukan ekspansi node yang memiliki jarak terdekat dengan goal. Namun, ekspansi yang dilakukan pada metode ini menggunakan evaluasi node hanya dengan melihat kepada fungsi heuristiknya. Dengan kata lain, yang dibandingkan untuk penentuan ekspansi node adalah nilai estimasi/prediksinya saja.
f(n) = h(n)
- A* Search
Bentuk dari Best First Search yang paling dikenal adalah algoritma pencarian A* (dibaca dengan “A-star”). Sedikit berbeda dengan Greedy yang hanya melihat kepada nilai h(n), pencarian dengan A* melihat kepada kombinasi nilai dari pathnya yaitu g(n) dengan nilai estimasi yaitu h(n).
f(n) = g(n) + h(n)
Uninformed and Informed Search Exercise
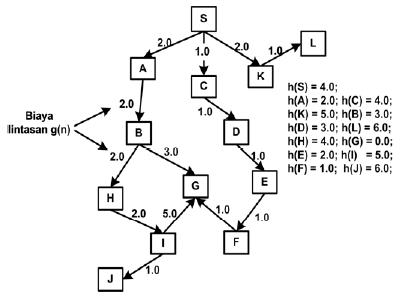
Gambar 3 Uninformed dan Informed Search Problem
Apabila diberikan kondisi tree seperti gambar di atas, dimana biaya lintasan (path), dan nilai prediksi/estimasi diberikan, maka kita dapat melakukan simulasi proses ekspansi node untuk algoritma Uniform Cost Search, Greedy Best First Search, dan A* Search.
- Uniform Cost Search
Proses ekspansi pada Uniform Cost Search dihitung berdasarkan nilai lintasan g(n) sehingga proses akan berjalan sebagai berikut:
f = {S};
f = {C, A, K}; // 1, 2, 2
f = {A, K, D}; // 2, 2, 2
f = {K, D, B}; // 2, 2, 4
f = {D, L, B}; // 2, 3, 4
f = {L, E, B}; // 3, 3, 4
f = {E, B}; // 3, 4
f = {B, F}; // 4, 4
f = {F, H, G}; // 4, 6, 7
f = {G, H, G}; // 5, 6, 7
f = {H, G}; // 6, 7
Proses eksplorasi node dimulai dari S sebagai initial state. Eksplorasi node dari S akan menuju ke A, C, K sebagai successornya. Pada simulasi eksplorasi di atas, untuk mempermudah proses eksplorasi maka dituliskan dengan C, A, K karena urutannya dituliskan secara ascending dari nilai g(n) terkecil sehingga akan dihasilkan urutan node yang akan dieksplorasi selanjutnya. Pada eksplorasi node selanjutnya, nilai g(n) diakumulasikan dari node awal sampai pada node current yang baru dieksplorasikan.
Dari proses di atas, maka dihasilkan jumlah ekspansi node sebanyak 10 kali, dan path yang dilalui dengan menggunakan algoritma Uniform Cost Search adalah S-C-D-E-F-G.
- Greedy Best First Search
Proses ekspansi dengan menggunakan algoritma Greedy Best First Search adalah dengan merujuk pada nilai estimasinya yaitu h(n). Berbeda halnya dengan nilai g(n) yang diakumulasikan, nilai h(n) tidak diakumulasikan. Proses eksplorasi akan berjalan seperti berikut ini:
f = {S};
f = {A, C, K}; // 2, 4, 5
f = {B, C, K}; // 3, 4, 5
f = {G, C, H, K}; // 0, 4, 4, 5
f = {C, H, K}; // 4, 4, 5
Proses yang dilakukan pada Greedy Best First Search sama seperti Uniform Cost Search, namun parameter yang digunakan hanya nilai estimasinya.
Dari proses di atas, maka dihasilkan jumlah ekspansi node sebanyak 4 kali, dan path yang dilalui dengan menggunakan algoritma Greedy Best First Search adalah S-A-B-G.
- A* Search
Eksplorasi node dari metode A* dilakukan dengan cara menjumlahkan kombinasi nilai path g(n) dan nilai estimasi h(n). Penjumlahan dari nilai tersebut akan dibandingkan untuk menentukan node mana dulu yang akan dieksplorasikan. Prosesnya akan berjalan sebagai berikut ini:
f = {S};
f = {A, C, K}; // 4, 5, 7
f = {C, K, B}; // 5, 7, 7
f = {D, K, B}; // 5, 7, 7
f = {E, K, B}; // 5, 7, 7
f = {F, K, B}; // 5, 7, 7
f = {G, K, B}; // 5, 7, 7
f = {K, B}; // 7, 7
Dari proses di atas, maka dihasilkan jumlah ekspansi node sebanyak 7 kali, dan path yang dilalui dengan menggunakan algoritma A* Search adalah S-C-D-E-F-G.