
CLUSTERING
Clustering atau klasterisasi adalah metode pengelompokan data. Menurut Tan, 2006 clustering adalah sebuah proses untuk mengelompokan data ke dalam beberapa cluster atau kelompok sehingga data dalam satu cluster memiliki tingkat kemiripan yang maksimum dan data antar cluster memiliki kemiripan yang minimum.
Clustering merupakan proses partisi satu set objek data ke dalam himpunan bagian yang disebut dengan cluster. Objek yang di dalam cluster memiliki kemiripan karakteristik antar satu sama lainnya dan berbeda dengan cluster yang lain. Partisi tidak dilakukan secara manual melainkan dengan suatu algoritma clustering. Oleh karena itu, clustering sangat berguna dan bisa menemukan group atau kelompokyang tidak dikenal dalam data. Clustering banyak digunakan dalam berbagai aplikasi seperti misalnya pada business inteligence, pengenalan pola citra, web search, bidang ilmu biologi, dan untuk keamanan (security). Di dalam business inteligence, clustering bisa mengatur banyak customer ke dalam banyaknya kelompok. Contohnya mengelompokan customer ke dalam beberapa cluster dengan kesamaan karakteristik yang kuat. Clustering juga dikenal sebagai data segmentasi karena clustering mempartisi banyak data set ke dalam banyak group berdasarkan kesamaannya. Selain itu clustering juga bisa sebagai outlier detection.
1.2 Manfaat Clustering
- Clustering merupakan metode segmentasi data yang sangat berguna dalam prediksi dan analisa masalah bisnis tertentu. Misalnya Segmentasi pasar, marketing dan pemetaan zonasi wilayah.
- Identifikasi obyek dalam bidang berbagai bidang seperti computer vision dan image processing.
1.3. Konsep dasar Clustering
Hasil clustering yang baik akan menghasilkan tingkat kesamaan yang tinggi dalam satu kelas dan tingkat kesamaan yang rendah antar kelas. Kesamaan yang dimaksud merupakan pengukuran secaranumeric terhadap dua buah objek. Nilai kesamaan antar kedua objek akan semakin tinggi jika kedua objek yang dibandingkan memiliki kemiripan yang tinggi. Begitu juga dengan sebaliknya. Kualitas hasil clustering sangat bergantung pada metode yang dipakai. Dalam clustering dikenal empat tipe data. Keempat tipe data pada tersebut ialah:
- Variabel berskala interval
- Variabel biner
- Variabel nominal, ordinal, dan rasio
- Variabel dengan tipe lainnya.
Metode clustering juga harus dapat mengukur kemampuannya sendiri dalam usaha untuk menemukan suatu pola tersembunyi pada data yang sedang diteliti. Terdapat berbagai metode yang dapat digunakan untuk mengukur nilai kesamaan antar objek-objek yang dibandingkan. Salah satunya ialah dengan weighted Euclidean Distance. Euclidean distance menghitung jarak dua buah point dengan mengetahui nilai dari masing-masing atribut pada kedua poin tersebut. Berikut formula yang digunakan untuk menghitung jarak dengan Euclidean distance:
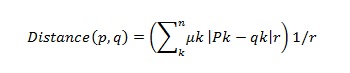
Keterangan:
N = Jumlah record data
K= Urutan field data
r= 2
µk= Bobot field yang diberikan user
Jarak adalah pendekatan yang umum dipakai untuk menentukan kesamaan atau ketidaksamaan dua vektor fitur yang dinyatakan dengan ranking. Apabila nilai ranking yang dihasilkan semakin kecil nilainya maka semakin dekat/tinggi kesamaan antara kedua vektor tersebut. Teknik pengukuran jarak dengan metode Euclidean menjadi salah satu metode yang paling umum digunakan. Pengukuran jarak dengan metode euclidean dapat dituliskan dengan persamaan berikut:
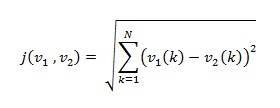 dimana v1 dan v2 adalah dua vektor yang jaraknya akan dihitung dan N menyatakan panjang vektor.
dimana v1 dan v2 adalah dua vektor yang jaraknya akan dihitung dan N menyatakan panjang vektor.
1.4 Syarat Clustering
Menurut Han dan Kamber, 2012, syarat sekaligus tantangan yang harus dipenuhi oleh suatu algoritma clustering adalah:
- Skalabilitas
Suatu metode clustering harus mampu menangani data dalam jumlah yang besar. Saat ini data dalam jumlah besar sudah sangat umum digunakan dalam berbagai bidang misalnya saja suatu database. Tidak hanya berisi ratusan objek, suatu database dengan ukuran besar bahkan berisi lebih dari jutaan objek.
- Kemampuan analisa beragam bentukdata
Algortima klasteriasi harus mampu dimplementasikan pada berbagai macam bentuk data seperti data nominal, ordinal maupun gabungannya.
- Menemukan cluster dengan bentuk yang tidak terduga
Banyak algoritma clustering yang menggunakan metode Euclidean atau Manhattan yang hasilnya berbentuk bulat. Padahal hasil clustering dapat berbentuk aneh dan tidak sama antara satu dengan yang lain. Karenanya dibutuhkan kemampuan untuk menganalisa cluster dengan bentuk apapun pada suatu algoritma clustering.
- Kemampuan untuk dapat menangani noise
Data tidak selalu dalam keadaan baik. Ada kalanya terdapat data yang rusak, tidak dimengerti atau hilang. Karena system inilah, suatu algortima clustering dituntut untuk mampu menangani data yang rusak.
- Sensitifitas terhadap perubahan input
Perubahan atau penambahan data pada input dapat menyebabkan terjadi perubahan pada cluster yang telah ada bahkan bisa menyebabkan perubahan yang mencolok apabila menggunakan algoritma clustering yang memiliki tingkat sensitifitas rendah.
- Mampu melakukan clustering untuk data dimensi tinggi
Suatu kelompok data dapat berisi banyak dimensi ataupun atribut. Untuk itu diperlukan algoritma clustering yang mampu menangani data dengan dimensi yang jumlahnya tidak sedikit.
- Interpresasi dan kegunaan
Hasil dari clustering harus dapat diinterpretasikan dan berguna.
1.5 Metode Clustering
Metode clustering secara umum dapat dibagi menjadi dua yaitu hierarchical clusteringdan partitional clustering(Tan, 2011). Sebagai tambahan, terdapat pula metode Density-Based dan Grid–Based yang juga sering diterapkan dalam implementasi clustering. Berikut penjelasannya:
1.5.1 Hierarchical clustering
Pada hierarchical clusteringdata dikelompokkan melalui suatu bagan yang berupa hirarki, dimana terdapat penggabungan dua grup yang terdekat disetiap iterasinya ataupun pembagian dari seluruh set data kedalam cluster.
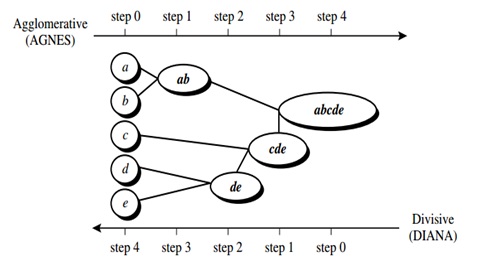
(Sumber:Han dkk, 2012)
Langkah melakukan Hierarchical clustering:
- Identifikasi item dengan jarak terdekat
- Gabungkan item itu kedalam satu cluster
- Hitung jarak antar cluster
- Ulangi dari awal sampai semua terhubung
Contoh metode hierarchy clustering: Single Linkage, Complete Linkage, Average Linkage, Average Group Linkage.
1.5.2 Partitional Clustering
Partitional clusteringyaitu data dikelompokkan ke dalam sejumlah cluster tanpa adanya struktur hirarki antara satu dengan yang lainnya. Pada metode partitional clusteringsetiap cluster memiliki titik pusat cluster (centroid) dan secara umum metode ini memiliki fungsi tujuan yaitu meminimumkan jarak (dissimilarity) dari seluruh data ke pusat cluster masing-masing. Contoh metode partitional clustering: K-Means, Fuzzy K-means dan Mixture Modelling.
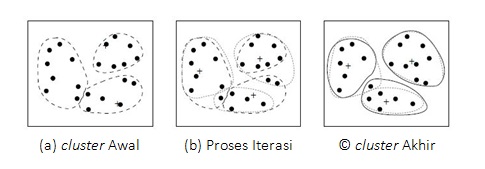
(Sumber:Han dkk, 2012)
Metode K-means merupakan metode clustering yang paling sederhana dan umum. Hal ini dikarenakan K-means mempunyai kemampuan mengelompokkan data dalam jumlah yang cukup besar dengan waktu komputasi yang cepat dan efisien. K-Means merupakan salah satu algoritma klastering dengan metode partisi (partitioning method) yang berbasis titik pusat (centroid) selain algoritma k-Medoids yang berbasis obyek. Algoritma ini pertama kali diusulkan oleh MacQueen (1967) dan dikembangkan oleh Hartigan dan Wong tahun 1975 dengan tujuan untuk dapat membagi M data point dalam N dimensi kedalam sejumlah k cluster dimana proses klastering dilakukan dengan meminimalkan jarak sum squares antara data dengan masing masing pusat cluster (centroid-based). Algoritma k-Means dalam penerapannya memerlukan tiga parameter yang seluruhnya ditentukan pengguna yaitu jumlah cluster k, inisialisasi klaster, dan jarak system, Biasanya, k-Means dijalankan secara independen dengan inisialisasi yang berbeda menghasilkan cluster akhir yang berbeda karena algoritma ini secara prinsip hanya mengelompokan data menuju local minimal. Salah satu cara untuk mengatasi local minima adalah dengan mengimplementasikan algoritma k-Means, untuk K yang diberikan, dengan beberapa nilai initial partisi yang berbeda dan selanjutnya dipilih partisi dengan kesalahan kuadrat terkecil (Jain, 2009).
K-Means adalah teknik yang cukup sederhana dan cepat dalam proses clustering obyek (clustering). Algoritma K-mean mendefinisikan centroid atau pusat cluster dari cluster menjadi rata-rata point dari cluster tersebut.Dalam penerapan algoritma k-Means, jika diberikan sekumpulan data X = {x1, x2, …,xn} dimana xi = (xi1, xi2, …, xin) adalah ystem dalam ruang real Rn, maka algoritma k-Means akan menyusun partisi X dalam sejumlah k cluster (a priori). Setiap cluster memiliki titik tengah (centroid) yang merupakan nilai rata rata (mean) dari data-data dalam cluster tersebut. Tahapan awal, algoritma k-Means adalah memilih secara acak k buah obyek sebagai centroid dalam data. Kemudian, jarak antara obyek dan centroid dihitung menggunakan Euclidian distance. Algoritma k-Means secara iterative meningkatkan variasi nilai dalam dalam tiap tiap cluster dimana obyek selanjutnya ditempatkan dalam kelompok yang terdekat, dihitung dari titik tengah klaster. Titik tengah baru ditentukan bila semua data telah ditempatkan dalam cluster terdekat. Proses penentuan titik tengah dan penempatan data dalam cluster diulangi sampai nilai titik tengah dari semua cluster yang terbentuk tidak berubah lagi (Han dkk, 2012).
Algoritma k-means:
Langkah 1: Tentukan berapa banyak cluster k dari dataset yang akan dibagi.
Langkah 2: Tetapkan secara acak data k menjadi pusat awal lokasi klaster.
Langkah 3: Untuk masing-masing data, temukan pusat cluster terdekat. Dengan demikian berarti masing-masing pusat cluster memiliki sebuah subset dari dataset, sehingga mewakili bagian dari dataset. Oleh karena itu, telah terbentuk cluster k: C1, C2, C3, …, Ck .
Langkah 4: Untuk masing-masing cluster k, temukan pusat luasan klaster, dan perbarui lokasi dari masing-masing pusat cluster ke nilai baru dari pusat luasan.
Langkah 5: Ulangi langkah ke-3 dan ke-5 hingga data-data pada tiap cluster menjadi terpusat atau selesai.
Pustaka
Han, J., Kamber, M., Pei, J.: Data Mining Concept and Techniques, 3rd ed. Morgan Kaufmann-Elsevier, Amsterdam (2012)
Jain. A.K (2009). Data Clustering: 50 Years Beyond K-Means. Pattern Recognition Letters, 2009.
Tan, P.N., Steinbach, M., Kumar, V. (2006) Introduction to Data Mining. Boston:Pearson Education.