
Recurrent Neural Network (RNN) dan Gated Recurrent Unit (GRU)
Aryo Pradipta Gema (1801399541) , Derwin Suhartono, S.Kom., M.T.I. (D3690)
Beberapa tahun terakhir, perkembangan kualitas yang besar pada teknologi sehari-hari sudah sangat terlihat. Contoh yang paling terlihat adalah speech recognition di dalam smartphone yang performanya sudah jauh lebih bagus. Ketika kita menggunakan voice command untuk mendapatkan direction menuju airport, kita dapat langsung memperolehnya. Interpretasi yang diperoleh tepat sesuai yang kita maksudkan, kemampuan intuitif dari sistem untuk direction menuju airport sudah bisa bekerja dengan baik. Deep learning membuat hal-hal yang demikian menjadi memungkinkan. Namun apa sebenarnya yang dimaksudkan dengan Deep Learning?
Deep learning adalah bagian dari riset di area machine learning yang berbasis pada ekstraksi fitur dari data secara lebih rinci. Cara kerja darideep learning merupakan hasil replikasi dari cara kerja otak manusia dalam hal mengirimkan informasi dari satu neuron menuju neuron lain. Alhasil, Deep learning dapat menghasilkan representasi pengetahuan yang lebih mendetail (high level knowledge representation).
Berbeda dengan algoritma machine learning terdahulu, seperti Naive Bayes. Algoritma tersebut lebih berbasis pada probabilitas. Hal ini terkadang membuat representasi dari informasi yang kita punya tidak dapat dieksploitasi lebih jauh lagi. Sehingga, aplikasi berbasis deep learning yang sehari-hari kita temukan, seperti speech recognition, dapat memberikan hasil yang jauh lebih memuaskan dibandingkan aplikasi dari era yang terdahulu.
Dalam dunia Natural Language Processing (NLP), deep learning juga sedang menjadi perhatian para peneliti. Kehadiran Recurrent Neural Network (RNN) yang menunjukkan performa yang sangat baik dalam memproses data seperti teks telah menjadi aktor perubahan yang besar di dalam dunia Natural Language Processing. Pada artikel ini, kita akan membahas tentang Recurrent Neural Network dan salah satu variasinya yaitu Gated Recurrent Unit (GRU).
Recurrent Neural Networks (RNNs)
Pada umumnya, manusia tidak membuat keputusan secara tunggal setiap saat. Kita akan selalu memperhitungkan masa lalu dalam membuat sebuah keputusan. Cara berpikir seperti ini adalah dasar dari pengembangan Recurrent Neural Network. Sama seperti analogi tersebut, RNN tidak membuang begitu saja informasi dari masa lalu dalam proses pembelajarannya. Hal inilah yang membedakan RNN dari Artificial Neural Networkbiasa.
Secara singkat, RNN adalah salah satu bagian dari keluarga Neural Network untuk memproses data yang bersambung (sequential data). Cara yang dilakukan RNN untuk dapat menyimpan informasi dari masa lalu adalah dengan melakukan looping di dalam arsitekturnya, yang secara otomatis membuat informasi dari masa lalu tetap tersimpan.
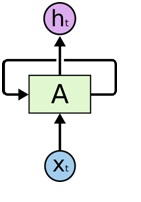
Gambar 1 adalah visualisasi contoh potongan dari sebuah RNN A. RNN tersebut mendapat input xt dan menghasilkan output ht . Dan alur loop tersebut memungkinkan informasi untuk dapat dilempar dari satu step menuju step selanjutnya.
Untuk memudahkan pemahaman, berikut gambaran sederhana dari looping RNN.
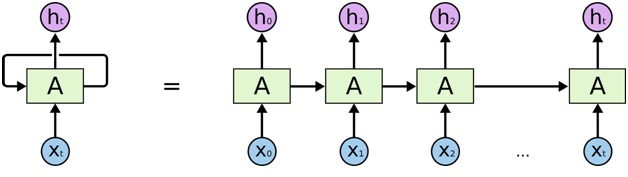
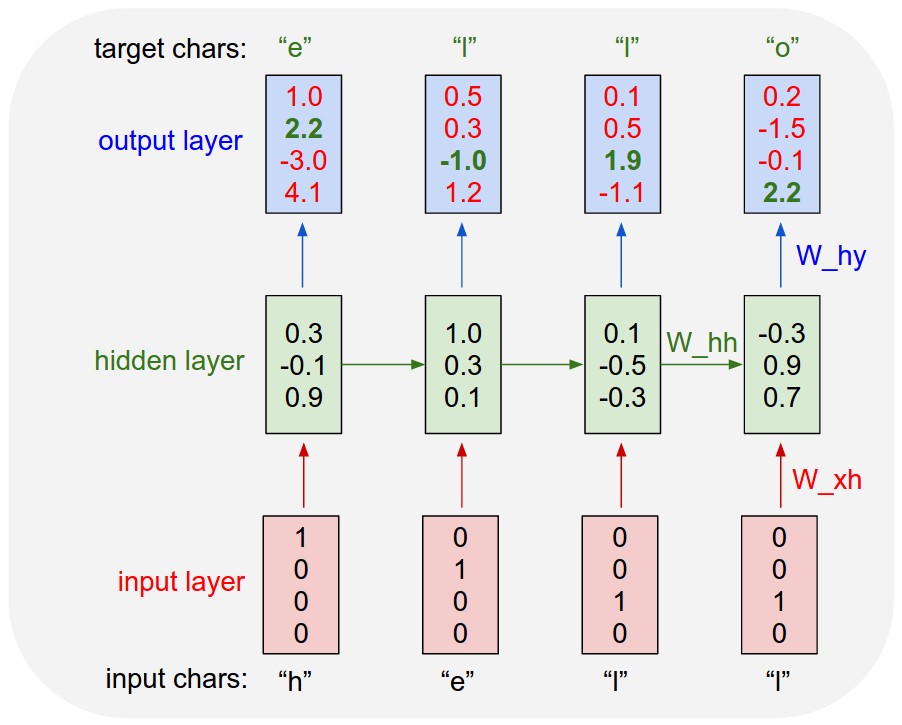
Dapat dilihat bahwa looping dari RNN sebenarnya akan memproses input dari skala waktu 0 sampai t. Berikut adalah contoh dari cara RNN memprediksi character selanjutnya.
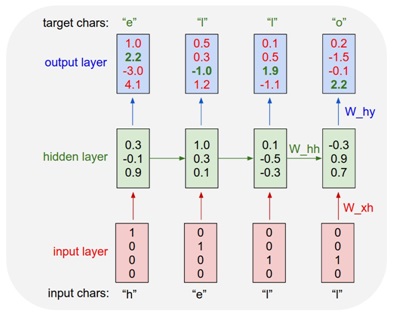
Seperti gambar diatas, RNN akan memproses data input satu per satu secara sekuensial dari huruf “h” sampai “l”, hidden layer pun akan melempar data menuju ke hidden layer pada skala waktu selanjutnya. Begitu seterusnya secara sekuensial.
Sifat dasar yang sekuensial ini menunjukkan bahwa RNN memang memiliki arsitektur yang didedikasikan untuk data berbentuk sequence dan list. Di beberapa tahun terakhir, RNN sudah cukup terbukti dalam menyelesaikan permasalahan seperti speech recognition, machine translation, sentiment analysis, image captioning dan masih banyak lagi. Arsitektur dari RNN pun terus berkembang, salah satunya adalah Gated Recurrent Unit(GRU).
Gated Recurrent Unit (GRU)
GRU pertama kali diperkenalkan oleh Chung et al. pada tahun 2014. Tujuan utama dari pembuatan GRU adalah untuk membuat setiap recurrent unit untuk dapat menangkap dependencies dalam skala waktu yang berbeda-beda secara adaptif. Sebagai analogi, manusia tidak perlu (terkadang tidak boleh) menggunakan semua informasi pada masa lalu untuk dapat membuat keputusan sekarang. Misalnya, kita ingin membeli makanan sekarang, informasi dari masa lalu mengenai jadwal ujian tengah semester tidak akan memberi kontribusi yang besar terhadap pembuatan keputusan untuk makan tersebut.
Di dalam GRU, komponen pengatur alur informasi tersebut disebut sebagai gate dan GRU mempunyai 2 gate, yaitu reset gate dan update gate. Bila kita ingin membuat keputusan untuk makan seperti analogi diatas, reset gate pada GRU akan menentukan bagaimana untuk menggabungkan input baru dengan informasi masa lalu, dan update gate, akan menentukan berapa banyak informasi masa lalu yang harus tetap disimpan.
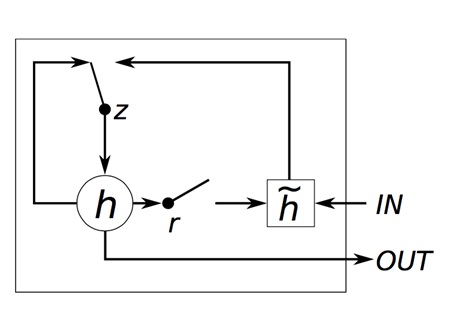
Pada gambar diatas, r melambangkan reset gates, dan z melambangkan update gates. Sedangkan, h dan ĥ adalah activation dan candidate activation. Activation dan candidate activation adalah fungsi aktivasi. Sekarang, GRU masih belum terlalu di eksplorasi cukup mendalam, karena umurnya yang masih cukup muda. Masih banyak kemungkinan yang dapat dikembangkan dari GRU untuk dapat menjadi RNN yang efisien dan mempunyai akurasi tinggi.
Summary
RNN sudah terbukti cocok untuk digunakan dalam menyelesaikan problem yang mempunyai data berbentuk sekuensial. Pengembangan RNN pun terus berkembang pesat, dan banyak penelitian yang sudah menghasilkan Artificial Intelligence (AI) berakurasi tinggi dengan menggunakan RNN, mulai dari sentiment analysis, speech recognition, hingga video captioning.
Perkembangan RNN pun disertai dengan modifikasi dari RNN tradisional menjadi RNN yang lebih adaptif, seperti GRU. Masih banyak variasi dari RNN selain GRU yang patut dipelajari dan dicoba. Sebagai rekomendasi, Anda dapat membaca lebih lanjut materi mengenai LSTM (akan dijelaskan pada blog post selanjutnya). LSTM juga merupakan rival dari GRU secara akurasi.
Keep in touch dengan perkembangan RNN!
Referensi:
Cho, Kyunghyun; Bougares, Fethi; Schwenk, Holger; Bahdanau, Dzmitry; Bengio, Yoshua. “Learning phrase representations using RNN encoder-decoder for statistical machine translation”. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724-1734, Doha, Qatar. (2014)
Chung, Junyoung; Gulcehre, Caglar; Cho, Kyunghyun; Bengio, Yoshua. “Empirical evaluation of gated recurrent neural networks on sequence modeling”. NIPS Deep Learning and Representation Learning Workshop. (2014)
Olah, Christopher. “Understanding LSTM Networks”. https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (2015)
Gambar 1 : https://colah.github.io/posts/2015-08-Understanding-LSTMs/img/RNN-rolled.png
Gambar 2 : https://colah.github.io/posts/2015-08-Understanding-LSTMs/img/RNN-unrolled.png
Gambar 3 : https://karpathy.github.io/assets/rnn/charseq.jpeg
Gambar 4 : Chung, Junyoung, et al. “Empirical evaluation of gated recurrent neural networks on sequence modeling.” (2014)
{kind=link}
{kind=link}
{kind=link}