
IMAGE SEARCH BY CONTENT USING BAG OF VISUAL WORDS PARADIGM
IMAGE SEARCH PROBLEMS
Content based image retrieval (CBIR) retrieves an image query Q from a large set of image documents D0, D1, D2, ………., DN on the basis of their visual content similarity. The performance of a such CBIR system therefore strongly depends on the process known as document indexing – a process of extracting the visual content of the image and representing them as a high dimensional feature vector. The retrieval process is then performed by mapping the images as a set of points in a high dimensional feature space and use the metric between points on this space as a measure of similarity or dissimilarity between images. Thus, the images close to the image query Q are considered similar to the query and will be orderly retrieved based on their degree of similarity or their retrieval status values.
Well-known low-level visual features such as color, shape and texture have been widely employed for document image indexing and retrieval. Despite of their ease of use, however their similarity measure are very sensitive to noise, scale, translation, rotation, and illumination changes. Moreover, the use of low-level visual features does not overcome the so-called semantic gap – the semantic difference between the search results performed by computer and user’s expectation that typically involves high level concepts such as activities, entities or objects, and events. In most cases, the applications robust to the scale, translation, rotation, and illumination changes and at the same time capable of handling the semantic gap are preferable. This short post will describe a such CBIR system that works under the Bag-of-Visual-Words (BoVW) paradigm (https://arxiv.org/pdf/1101.3354.pdf). Using BoVW approach, the local visual descriptors of an image are first transformed into a vector of “visual words” through clustering and encoding processes. The retrieval process is then carried out similar to document text retrieval systems that apply scalable indexing and fast search on the high dimensional vector space. It is noted that, while being computationally cheaper and conceptually simpler, the BoVW based systems have demonstrated comparable or better results than other approaches for image recognition, classification, and retrieval.
SIFT AS LOCAL VISUAL DESCRIPTORS
The global features descriptors represent the visual content of the entire image whereas the local features describe a patch within an image. The local features in general are more superior compared to the global features due to their capability of identifying important visual characteristics of the image. In consequence, local features techniques provide better retrieval effectiveness and have a great discriminative power in solving most of the vision problems than the global features. David G. Lowe – University of British Colombia (https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf), in 2004 proposed a new local features identification schemes known as SIFT (scale invariant feature transform). Using SIFT, although the image is scaled or rotated and even if it undergo a change in illumination the same local interest points such as corners and edges could still be observed. Similar to other local features techniques, SIFT generally involves two main tasks – detecting local interest points and computing its descriptors based on the region centered on the detected interest points. The computation of SIFT based local descriptors is summarized as follows :
- Keypoints such as corner of various scale are first observed by convolving the image with a scale-space filter such as LOG (Laplacian of Gaussian) filter of different octaves and blur scale k. The observed keypoints are then localized by comparing each pixel with its 8 neighbours as well as 9 pixels in the previous scales and other 9 pixels in the next scales. This process is subsequently followed by constrast and edge thresholding processes in order to get more accurate local keypoints
- A 16×16 neighbourhood around each local keypoint obtained from the previous process is taken and an orientation is assigned to every single pixel in it by computing its gradient magnitude and direction. Next, the 16×16 neighbourhood is divided into 16 sub-blocks of 4×4 size. From each 4×4 window size, a histogram of 8 bins (each bin corresponding to 0-44 degrees, 45-89 degrees, etc) is then generated. The vector representing keypoint descriptors for each image patch is finally obtained by normalizing the 16×8 histogram values. The following two figures, Fig. 1 and 2, show how the orientation of each pixel and keypoint descriptors are created.
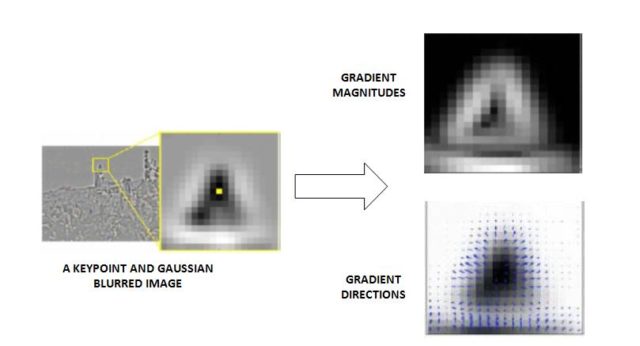
Figure 1. Assigning an orientation to the keypoints (https://aishack.in/tutorials/sift-scale-invariant-feature-transform-introduction/)
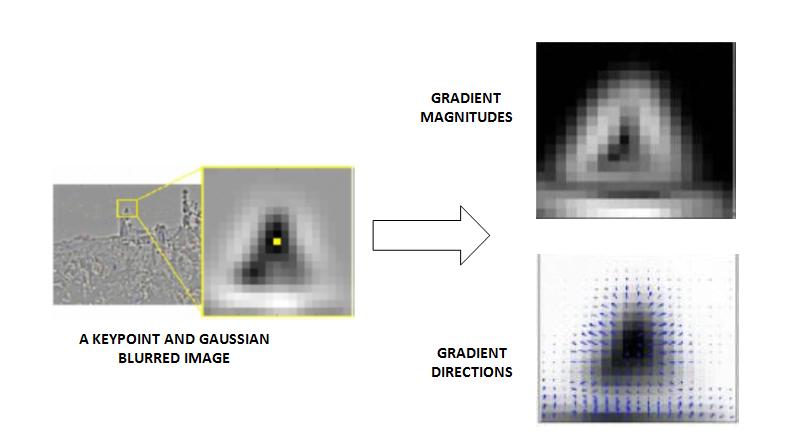
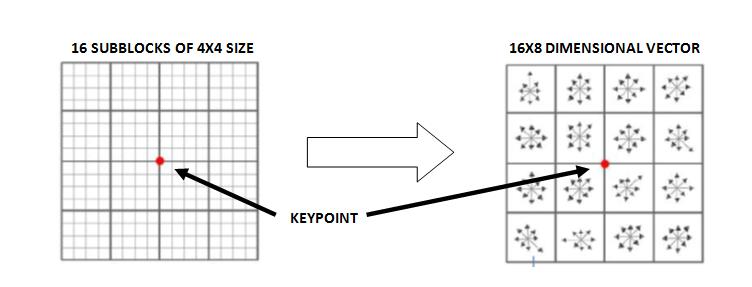
(https://aishack.in/tutorials/sift-scale-invariant-feature-transform-introduction/)
BAG OF VISUAL WORDS
The terminology “Bag of Words” originally comes from text-based document analysis. After dropping stop-words such as articles and prepositions and subsequently followed by applying a certain stemming method, each textual document can then be represented as a normalized histogram of word counts forming a sparse vector known as term vector. The term vector constitutes the Bag-of-Words document representation – called a “bag” because all ordering of the words in the document have been omitted. In analogy to the text-based document analysis, local visual descriptors representing local areas of an image can be regarded just as words are local features in a textual document. An image can therefore be represented as a vector of visual words showing how many time each of the visual words occurs in the image. Fig. 3 shows in a schematic fashion how the visual vocabulary is constructed and the vector of visual words (BoVW) is assigned.
Using a local features algorithm such as SIFT, a huge number of local features descriptors extracted from a large set of training images are mapped (shown as sets of black dots) into a high dimensional feature space as shown in Fig. 3.A. In order to obtain discrete visual vocabulary, the sampled features are then clustered by a certain vector quantization method such as k-means or Gaussian Mixture. As can be seen from Fig. 3.B, center of each cluster denoted by large green circle are assigned to be the visual words W1, W2, W3, and W4 respectively. Using W1, W2, W3, and W4, a dictionary containing visual vocabulary may be constructed. Fig. 3.C shows how the dictionary is then used to obtain a BoVW of a novel image. This is done by identifying the nearest visual words Wi for each of its local features descriptors. As already mentioned, the BoVW is expressed as a histogram of word counts forming a vector of visual words as shown in Fig. 3.D.

(https://www.cs.utexas.edu/~grauman/courses/fall2009/papers/bag_of_visual_words.pdf)
IMPLEMENTATION AND RESULTS
Image search by content using BoVW paradigm (https://arxiv.org/pdf/1101.3354.pdf) has been experimentally implemented using Python based modules such as scipy, cv2, and sklearn and a small-version UKBench dataset (https://github.com/willard-yuan/image-retrieval/tree/master/bag-of-words-python-dev-version). In order to make the application to be somewhat user friendly and works under the web environment, the code was modified and cherrypy module was added to it. Fig. 4 shows a typical user-interface of the application displaying a set of 28 images randomly taken from the UKBench dataset. To start searching, the query image Q can be freely chosen from these of 28 images.
In the BoVW approach, the similarity between a document vector Di and a query vector Q can be determined by computing the cosine of the angle between them (https://stefansavev.com/blog/cosine-similarity/). The computation of cosine similarity between two BoVW vectors would be very efficiently performed because although the document vectors live a very high-dimensional space, the document matrix will generally be sparsely populated. Thus the manipulation of the matrix only require space and time proportional to the average number of different words that appear in a document. Fig. 5 shows search results from different query images which are orderly retrieved based on the similarity scores (score 1 means completely similar and 0 means completely dissimilar). Although the corresponding relevant images in the collection are changed in term of scale, orientation, and illumination, the BoVW based system is still capable of finding the relevant one. For the shake of the experiment, the dataset is designed to contain only three relevant images for each image model. This is the reason why only the first four images are always relevant to the image query chosen.



