
Artificial Intelligence Dalam Mengenali Lagu
Di abad ke 21 ini, Artificial Intelligence bukanlah lagi hal yang asing. Semua perusahaan khususnya yang bisnis utamanya di bidang Teknologi Informasi berlomba-lomba dalam menghadirkan produk yang mengimplementasikan Artificial Intelligence untuk meningkatkan kemudahan customernya.
Artificial Intelligence pun tidak lepas dari seni, salah satunya seni musik. Dimulai dari penerapannya untuk recognize musik/lagu yang sedang diputar sampai dengan kemampuannya dalam music composing.
Untuk music recognition, telah banyak aplikasi yang beredar untuk smartphone, diantaranya adalah Shazam, SoundHound, TrackID milik Sony, Musixmatch, dan lain-lain. Bahkan, pada peluncuran smartphone Google Pixel 2, Google juga meluncurkan fitur “Now Playing” yang dapat me-recognize musik yang sedang terputar walaupun tanpa adanya koneksi internet.
Kemampuan aplikasi-aplikasi tersebut pun cukup impresif. Hanya dengan potongan lagu yang sedang terputar, aplikasi tersebut dapat mengetahui judul lagu dengan mencari kecocokannya dengan jutaan lagu yang ada di database mereka. Mencari kecocokan sebuah lagu dengan cepat dari database yang sebesar itu tentu saja merupakan hal yang terdengar rumit. Jika metode pencariannya menggunakan cara konvensional, yaitu dengan mencocokan lagu yang terputar dengan satu per satu lagu di database tentu saja merupakan task yang sangat kompleks dan tidak efisien, baik secara time complexity maupun space complexity.
Cara kerja aplikasi-aplikasi tersebut berbeda, terinpirasi dari cara kerja otak manusia dalam mengenali suara. Terdapat sebuah studi yang dilakukan oleh Manchester Museum of Science of Industry di mana mereka mengetes kemampuan 12.000 partisipan dalam mengenali lagu-lagu melalui game online bernama Hooked On Music[1]. Hasilnya lagu Wannabe oleh Space Girls menduduki peringkat pertama sebagai lagu yang paling cepat dikenali dengan rata-rata kecepatan 2,3 detik.
Penelitian tersebut membuktikan bahwa otak manusia telah berevolusi untuk terlatih dalam mengenali suara yang pernah didengarkan. Otak kita tidak mencocokan suara yang didengarkan dengan setiap suara yang pernah didengarkan seperti cara biasa pada komputer. Kombinasi dari nada dan perubahannya mengaktivasi bagian spesifik dari neuron di otak yang menyimpan suara yang pernah didengarkan tersebut.
Agar sebuah lagu dapat dipelajari oleh komputer, tentu lagu tersebut perlu dikonversi menjadi digital terlebih dahulu, salah satu caranya adalah dengan dikonversi menjadi spektogram yang merupakan representasi visual dari suara.
Sayangnya, data yang disimpan di spektogram terlalu besar sehingga jumlah komputasi yang diperlukan pun cukup besar dan tentu memakan waktu yang lama. Sehingga, untuk memiliki komputasi yang lebih sedikit, maka data yang harus diproses perlu dikurangi. Contohnya, Shazam membuat versi representasi datanya sendiri yang mereka namakan fingerprint. Fingerprint lagu Shazam menyimpan frekuensi terkuat pada waktu tertentu sehingga data dari setiap lagu pada database jutaan lagu yang mereka simpan menjadi sangat minim. Untuk dapat mengenali lagu yang diputar, Shazam mengkonversi suara yang masuk melalui microphone menjadi fingerprint yang kemudian dicocokkan dengan database yang mereka miliki.
Di sinilah hal tersebut menjadi menarik, Shazam menggunakan teknik tiering di mana mereka akan mencocokkan fingerprint yang dikirim dari smartphone ke tier kecil yang berisi lagu-lagu paling populer terlebih dahulu baru kemudian ke group yang lebih besar. Dengan cara ini, Shazam berhasil mengurangi waktu yang diperlukan untuk mencocokkannya dengan lagu yang kurang populer namun tetap dapat mencari lagu yang kurang populer.
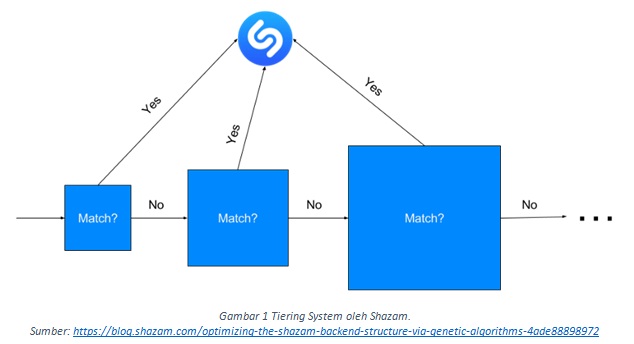
Sistem tiering ini memunculkan pertanyaan-pertanyaan baru untuk mencapai hasil yang lebih optimal, berapakah banyakkan tier yang harus ada? Berapa lagu yang perlu disimpan setiap tier? Dan pada saat apa perlu dilakukan query ke tier apa?
Untuk mencapai hasil yang optimal, Shazam menggunakan Genetic Algorithms yang merupakan salah satu metode di dalam Artificial Intelligence. Di mana GA akan mulai dengan individu yang random yang kemudian dipilih untuk “dikawinkan” untuk membuat individu pada generasi baru. Pada setiap generasi, dipilih individu yang paling baik untuk “dikawinkan” lagi.
Generasi awal GA tersebut tidak menghasilkan hasil yang bagus. Shazam melakukan “mutating and mating” tersebut terus-menerus sampai ditemukan individu yang dapat menghasilkan performa terbaik. Hasilnya, didapatkan individu yang dapat menghasilkan performa yang superior dan dapat men-recognize lagu dengan kecepatan yang minimal.
Author: Reynaldi Hartono – 2101666466
Advisor: Williem, S.Kom., Ph.D. – D5963