
Part of Speech Tagging
Part-of-speech (POS) tagging atau secara singkat dapat ditulis sebagai tagging merupakan proses pemberian penanda POS atau kelas sintaktik pada tiap kata di dalam corpus. Dikarenakan tag secara umum juga diaplikasikan pada tanda baca, maka dalam proses tagging, tanda baca seperti tanda titik, tanda koma, dll perlu dipisahkan dari kata-kata. Oleh sebab itu, proses tokenisasi biasanya dilakukan sebelum POS tagging. Selain itu beberapa preprocessing juga dilakukan seperti pemisahan koma, tanda petik, dll dari kata serta dilakukan juga disambiguitas pada tanda baca penanda akhir kalimat seperti tanda titik dan tanda tanya agar dapat dibedakan dari tanda yang digunakan untuk singkatan (seperti contohnya: e.g. dan etc.).
Seperti pernah disebutkan sebelumnya, masalah utama dalam melakukan tagging adalah ambiguitas terutama ketika kita meminta sistem untuk melakukannya secara otomatis. Contoh dari beberapa kata yang seringkali menimbullkan ambiguitas diantaranya adalah book dikarenakan memiliki 2 buah makna, yakni book sebagai kata benda yang berarti buku dan sebagai kata kerja yang berarti memesan. Oleh karena itu POS-tagging bertujuan untuk menyelesaikan masalah ini dengan memilih tag yang tepat untuk konteks kata di dalam kalimat.
Dalam konteks tagging di Bahasa Inggris, yang paling sering digunakan adalah Penn Treebank. Rinciannya terdapat pada gambar 1 di bawah ini.
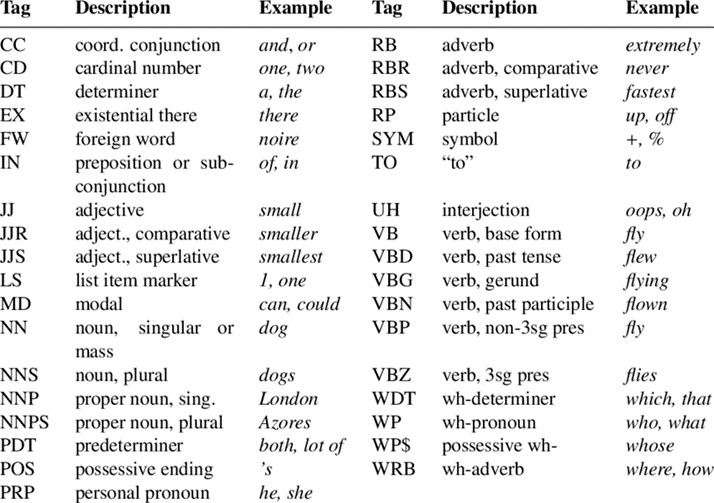
Gambar 1. Penn Treebank Tagset
Kebanyakan algoritma untuk tagging termasuk salah satu kelas dari rule-based taggers dan stochastic taggers. Rule-based tagger secara umum melibatkan database dalam ukuran yang besar mengenai aturan-aturan disambiguasi dari tulisan tangan yang menspesifikasikan diantaranya, sebuah kata yang ambigu adalah kata benda dan bukan kata kerja jika diikuti oleh determiner. Salah satu contoh rule-based tagger adalah EngCG, yang berdasarkan arsitektur Constraint Grammar dari Karlsson et al (1995).
Stochastic taggers secara umum menyelesaikan masalah ambiguitas pada tagging dengan menggunakan korpus yang dilatih untuk menghitung probabilitas dari sebuah kata yang dengan tag yang diberikan dalam sebuah konteks.
Beberapa pendekatan yang dapat digunakan untuk tagging diantaranya adalah HMM tagger dan transformation based tagger atau sering disebut sebagai Brill tagger dengan mengkombinasikan kedua ke-2 jenis tagger sebagaimana sudah dijelaskan di atas.