
Apache Spark Untuk Pemrosesan Big Data.
Apa itu Apache Spark? Pada dasarnya Apache Spark merupakan sebuah framework atau environtment yang dapat digunakan untuk mengakses data dari berbagai sumber berbeda, kemudian mengolah data tersebut, kemudian menyimpannya kedalam penyimpanan data untuk dianalisis. Fitur yang dimiliki oleh Apache Spark memungkinkan para data engineer untuk membangun sebuah aplikasi pipa pemrosesan Big Data. Terdapat beberapa definisi mengenai apa itu Apache Spark sebagai berikut,
- Menurut Wikipedia:
Apache Spark adalah framework komputasi cluster terdistribusi yang open source. Spark menyediakan antarmuka untuk memprogram seluruh cluster dengan paralelisme data implisit dan toleransi kesalahan.
- Menurut website resmi Apache:
Apache Spark adalah framework yang digunakan untuk memproses, menanyakan, dan menganalisis Big Data. Apache Spark melakukan pemrosesan data melalui in-memory, sehingga waktu pemrosesan lebih cepat daripada framework sejenis seperti MapReduce dan lainnya. Perkembangan data dalam tingkat terabyte data diproduksi setiap hari, menjadikan kebutuhan akan solusi yang dapat memberikan real time analysis dengan kecepatan tinggi.
Fitur yang ada pada Apache Spark,
- Performa lebih cepat dibandingkan framework pemrosesan data tradisional.
- Mudah digunakan, aplikasi pengolahan data yang dibangun dengan Spark dapat dituliskan dalam bahasa pemrograman Python, R, Java, dan Scala.
- Dilengkapi dengan SQL Library, Streaming, dan Graph Analysis yang memudahkan proses pengolahan dan alnalisis data.
Apache Spark memiliki beberapa komponen dan dukungan dari berbagai bahasa pemrograman, ilustrasi mengenai komponen yang ada pada Apache Spark tedapat pada Gambar 1.
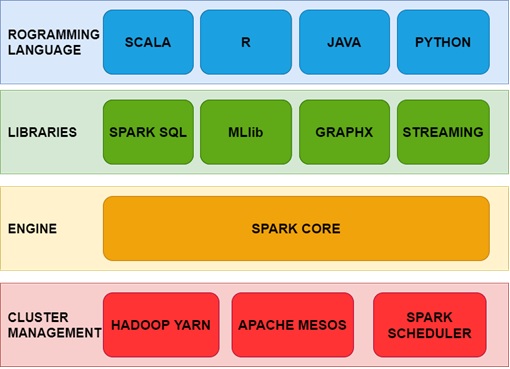
Gambar 1. Komponen Apache Spark.
- Spark Core
Spark Core adalah mesin dasar untuk pemrosesan data paralel dan terdistribusi skala besar. Library tambahan dapat dibangun di atas Spark Core sehingga memungkinkan beragam pemrosesan seperti untuk streaming, SQL, dan Macine Learning untuk mendukung berbagai aktivitas pemrosesan data. Komponen ini berisi fungsionalitas dasar Spark seperti penjadwalan tugas, manajemen memori, interaksi dengan sitem penyimpanan, dll. Tanpa Spark Core berbagai library Spark lainnya tidak dapat dijalankan pada suatu mesin atau server.
- Spark SQL
Spark SQL adalah library yang mengintegrasikan pemrosesan data relasional dengan Spark functional programming API. Library ini mendukung pengolahan data menggunakan kueri, baik melalui SQL atau melalui Bahasa Kueri Hive. Spark SQL menggunakan antarmuka seperti SQL untuk berinteraksi dengan data dari berbagai format seperti CSV, JSON, Parket, hingga ke berbagai database engine seperti MySQL dan SQL Server.
- MLlib
MLlib adalah library yang berisi berbagai macam Algoritma Machine Learning yang ditawarkan oleh Spark. MLib menyediakan berbagai function yang dapat dipanggil untuk melakukan pembelajaran Supervised maupun Un-supervised, Regression maupun Classification. Library ini dapat memenuhi kebutuhan analisis untuk melihat pola tersembunyi dari data yang ada, setelah data dari berbagai sumber didapatkan dan diolah.
- GraphX
Library ini adalah API Apache Spark untuk menjalankan komputasi grafik secara paralel. Library ini dapat mengolah data yang tersimpan dalam format RDD (Resilient Distributed Dataset), kemudian membuat grafik yang memiliki arah pada setiap vertex dan edge. Setiap vertex dan edge dapat memiliki properties seperti nama, cost atau jarak, arah, dan menyimpan informasi lainnya yang dibutuhkan.
- Spark Steaming
Komponen ini merupakan komponen dari Spark yang dapat digunakan untuk memproses data secara real time streaming. Streaming memungkinkan data yang masuk, dapat diolah dan disimpan secara real time. Spark Streaming memberikan fasilitas untuk aplikasi pemrosesan data yang dibangun menggunakan Spark, dapat berjalan secara real time. Spark Streaming akan berkomunikasi dengan sumber data dan tempat penyimpanan data. Sumber data dapat terdiri dari satu atau beberapa server/aplikasi berbeda, kemudian Spark menerima data dari sumber tersebut, lalu mengolahnya dan mengirim data hasil olahan menuju tempat penyimpanan data secara terus menerus (tidak terputus).
- Spark Cluster Managers
Spark Cluster Managers merupakan komponen Spark yang mendukung pengelolaan sumber daya/cluster berikut:
- Spark Standalone – Cluster Manager sederhana yang didalamnya hanya memuat
- Apache Mesos – Cluster Manager yang lebih umum yang dapat menjalankan environment lainnya seperti Hadoop
- Apache Hadoop YARN – Resource manager untuk mengelola environment Hadoop
- Kubernetes – sistem opensource yang memanajemen berbagai macam aplikasi dalam bentuk kontainer.
Apache Spark merupakan tools Big Data yang sangat berguna untuk membangun jalur pemrosesan data dengan mudah, didukung oleh beberapa jenis bahasa pemrograman dan menyediakan berbagai library yang dapat memenuhi kebutuhan pemrosesan data. Kita dapat mengakses hingga petabyte data dari berbagai sumber pengimpanan berbeda dan memprosesnya secara cepat dengan menyiapkan beberapa node server yang terinsall framework Apache Spark. Apache Spark juga dilengkapi dengan library untuk memenuhi kebutuhan analisis data seperti GraphX untuk komputasi grafik, dan MLlib untuk memenuhi kebutuhan pengolahan data menggunakan machine learning. Eksekusi dari aplikasi yang dibangun menggunakan Spark dapat mendukung pemrosesan data secara real time, sehingga dapat digunakan untuk membangun pipa pemrosesan Big Data dari berbagai sumber data, menuju penyimpanan data secara terus menerus.
Sumber :
- https://en.wikipedia.org/wiki/Apache_Spark
- https://spark.apache.org/
- https://towardsdatascience.com/create-your-first-etl-pipeline-in-apache-spark-and-python-ec3d12e2c169
- https://phoenixnap.com/kb/install-spark-on-windows-10
- https://towardsdatascience.com/a-beginners-guide-to-apache-spark-ff301cb4cd92