
Pengenalan Natural Language Generation
Hasil menakjubkan dari GPT-2 OpenAI (Radford et al., 2018) telah menghidupkan kembali minat pada Natural Language Generation (NLG), sebuah sub bidang dari Natural Language Processing (NLP). Pada artikel ini kita akan membahas dasar dari NLG, algoritma, serta topik-topik penelitiannya.
Apa itu Natural Language Generation?
Natural Language Generation adalah proses menghasilkan frasa dan kalimat yang bermakna dalam bentuk bahasa alami. Pada intinya, ia secara otomatis menghasilkan narasi yang menggambarkan, meringkas atau menjelaskan input data terstruktur layaknya manusia dengan kecepatan ribuan halaman per detik.
Namun, meskipun software NLG dapat menulis, ia tidak dapat membaca. Bagian dari NLP yang membaca bahasa manusia dan mengubah data tidak terstrukturnya menjadi data terstruktur yang dapat dimengerti oleh komputer disebut Natural Language Understanding (NLU).
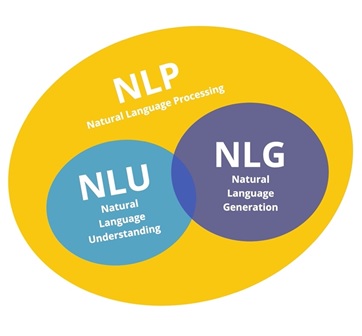
Secara umum, NLG dan NLU adalah bagian dari domain NLP yang lebih umum, yang mencakup semua sistem yang menafsirkan atau menghasilkan bahasa manusia, baik dalam bentuk lisan maupun tulisan. Maka, secara ringkas dapat dikatakan bahwa:
- NLU melibatkan pemecahan bahasa manusia ke dalam format yang dapat dibaca mesin, yaitu dari teks ke makna.
- NLG adalah proses mengkonstruksi output berupa bahasa alami dari input non-linguistik, yaitu menghasilkan teks dari data terstruktur.
- NLP berkaitan dengan interaksi antara komputer dan manusia menggunakan bahasa alami. Tujuan akhir dari NLP adalah untuk membaca, menguraikan, memahami, dan memahami bahasa manusia dengan cara yang berharga.
Awalnya, sistem NLG menggunakan template untuk menghasilkan teks. Berdasarkan beberapa data atau query, sistem NLG akan mengisi kekosongan (fill in the blank). Namun seiring waktu, sistem generasi bahasa alami telah berevolusi dengan penerapan Hidden Markov chain, Recurrent Neural Network (RNN) dan Transformers, memungkinkan generasi teks yang lebih dinamis secara real time.
Algoritma/Model dalam NLG
Bahkan setelah NLG beralih dari penggunaan template ke generasi kalimat yang dinamis, butuh waktu bertahun-tahun untuk bereksperimen dengan teknologi untuk mencapai hasil yang memuaskan. Sebagai bagian dari NLP, NLG bergantung pada sejumlah algoritma yang mengatasi masalah tertentu dalam membuat teks seperti manusia.
Markov Chain
Markov Chain adalah salah satu algoritma pertama yang digunakan untuk generasi bahasa. Model ini memprediksi kata berikutnya dalam kalimat dengan menggunakan kata saat ini dan mempertimbangkan hubungan antara setiap kata unik untuk menghitung probabilitas kata berikutnya. Nyatanya, kalian sudah sering melihat algoritma ini pada versi lawas dari keyboard smartphone, di mana mereka digunakan untuk menghasilkan saran untuk kata berikutnya dalam kalimat.
Recurrent Neural Network
Neural Network adalah model yang mencoba meniru cara kerja otak manusia. Dalam RNN, setiap item dari suatu sequence akan melewati jaringan feedforward dan menggunakan output dari model sebagai input ke item berikutnya dalam sequence, memungkinkan informasi pada langkah sebelumnya untuk disimpan. Dalam setiap iterasi, model menyimpan kata-kata sebelumnya yang ditemui dalam memorinya dan menghitung probabilitas kata berikutnya. Untuk setiap kata dalam kamus, model memberikan probabilitas berdasarkan kata sebelumnya, memilih kata dengan probabilitas tertinggi dan menyimpannya dalam memori. Memori RNN membuat model ini ideal untuk generasi bahasa karena dapat mengingat histori suatu konteks teks setiap saat. Namun, seiring bertambahnya panjang sequence, RNN tidak dapat menyimpan kata-kata yang ditemukan dari jarak jauh dalam kalimat dan membuat prediksi hanya berdasarkan kata terbaru. Karena keterbatasan ini, RNN tidak dapat menghasilkan kalimat panjang yang koheren.
Long Short-Term Memory
Untuk mengatasi masalah dependensi jarak jauh, varian RNN yang disebut Long short-term memory (LSTM) diperkenalkan. Meskipun mirip dengan RNN, model LSTM menyertakan neural network empat lapis. LSTM terdiri dari empat bagian: unit, input gate, output gate, dan forgot gate. Ini memungkinkan RNN untuk mengingat atau melupakan kata-kata pada interval waktu manapun dengan menyesuaikan aliran informasi dari unit. Ketika suatu titik ditemukan, Forgot Gate mengenali bahwa konteks kalimat dapat berubah dan dapat mengabaikan informasi status unit saat ini. Hal ini memungkinkan network untuk secara selektif melacak informasi yang relevan sementara juga meminimalkan masalah vanishing gradient, yang memungkinkan model untuk mengingat informasi dalam jangka waktu yang lebih lama.
Namun, kapasitas memori LSTM terbatas pada beberapa ratus kata karena jalur sekuensial yang kompleks dari unit sebelumnya ke unit saat ini. Kompleksitas ini menyebabkan dibutuhkannya daya komputasi yang tinggi, yang membuat LSTM sulit untuk dilatih secara paralel.
Transformer
Model relatif baru yang pertama kali diperkenalkan di Google Paper 2017 “Attention is all you need”, yang mengusulkan metode baru yang disebut “self-attention”. Transformer merupakan model berdasarkan encoder-decoder yang terdiri dari tumpukan encoder untuk memproses input dengan panjang berapa pun dan tumpukan decoder untuk mengoutput kalimat yang dihasilkan. Berbeda dengan LSTM, Transformer hanya melakukan sejumlah kecil step yang konstan, sambil menerapkan mekanisme self-attention yang secara langsung mensimulasikan hubungan antara semua kata dalam sebuah kalimat. Tidak seperti model sebelumnya, Transformer menggunakan representasi semua kata dalam konteks tanpa harus mengompres semua informasi menjadi representasi tunggal dengan panjang tetap yang memungkinkan sistem menangani kalimat yang lebih panjang tanpa meroketnya daya komputasi yang diperlukan.

Salah satu contoh paling terkenal dari Transformer untuk NLG adalah GPT-2 OpenAI yang merupakan tumpukan decoder Transformer. Model ini dilatih untuk memprediksi kata berikutnya dalam sebuah kalimat dengan berfokus pada kata-kata yang sebelumnya terlihat dalam model.
Topik Penelitian NLG dalam Bahasa Indonesia
Dalam penelitian Cahyawijaya et al. (2021) mengenai benchmark NLG dalam Bahasa Indonesia, downstream task/topik pada NLG dapat dibagi menjadi empat, yaitu Machine Translation, Text Summarization, Question Answering, dan Chit-chat. Penelitian ini menggunakan model bahasa state-of-the-art dalam NLG, BART, yang berdasarkan model Transformer.

Machine Translation
Machine translation dapat memahami bahasa alami dan menerjemahkannya ke dalam bahasa alami lainnya. Seiring perkembangan jaman, pendekatan terhadap machine translation sudah berkembang dari pendekatan statistical dan rule-based menjadi pendekatan neural yang menggunakan neural network (Neural Machine Translation). Machine translation juga melahirkan model encoder-decoder dengan atensi (Bahdanau et al., 2014) yang mana merupakan dasar dari model-model state-of-the-art dalam bidang NLG. Untuk datasetnya sendiri, sudah terdapat banyak sumber yang dapat digunakan. Sementara di Indonesia, Cahyawijaya et al. (2021) menambahkan dataset multilingual lokal antara bahasa Jawa-Indonesia dan Sunda-Indonesia yang menarik untuk diteliti. Contoh produk dari machine translation yaitu Google Translate yang apabila dicermati semakin membaik dalam penerjemahan bahasa.
Text Summarization
Text summarization bertujuan untuk meringkas teks, menghasilkan teks dengan informasi penting yang lebih singkat dan padat. Pendekatan dalam text summarization terbagi menjadi 2 bagian, yaitu ekstraktif dan abstraktif. Pendekatan ekstraktif cenderung mengambil kata atau kalimat langsung dari teks input yang diberikan, sementara pendekatan abstraktif menghasilkan kata atau kalimat yang baru dengan konteks dari teks input. Dengan perkembangan dalam NLG, pendekatan ekstraktif cenderung masuk dalam bagian NLU karena hanya mengambil kata atau kalimat dari teks input, sementara pendekatan abstraktif termasuk NLG karena benar-benar menghasilkan kata yang baru. Selain itu, meskipun memiliki input dan output yang mirip dengan machine translation, namun machine translation yang dapat dilatih untuk menyesuaikan alignment karena panjang input dan outputnya relatif sama, sementara text summarization menghasilkan output dengan panjang sequence yang jauh lebih pendek. Maka dari itu, tidak semua algoritma/metode yang memiliki hasil yang baik dalam machine translation dapat bekerja dalam text summarization.
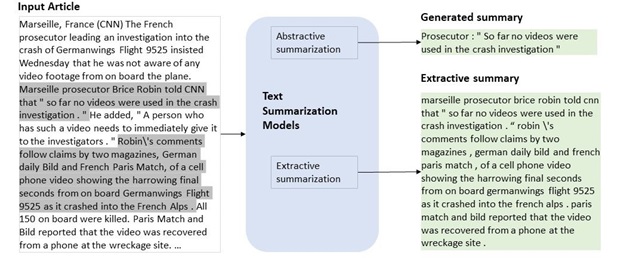
Meskipun terdapat banyak jenis summarization seperti multi document summarization yang meringkas banyak dokumen teks yang mirip menjadi satu ringkasan, dan chat summarization yang meringkas percakapan untuk menemukan topiknya, namun yang lebih sering diteliti adalah single document summarization karena lebih banyak dataset dan benchmarknya. Dataset yang digunakan dalam penelitian text summarization kebanyakan berupa artikel berita dan ringkasannya. Penelitian oleh Cahyawijaya et al. (2021) menggunakan dataset summarization Indonesia yang ada, yaitu Liputan6 dan Indosum. Peluang penelitian ini dalam Bahasa Indonesia masih sangat besar karena penelitiannya masih kurang, khususnya dalam pendekatan abstraktif.
Question Answering
Dalam Question answering, sistem akan menjawab pertanyaan berdasarkan suatu konteks teks, seperti ujian reading dalam Bahasa Indonesia atau TOEFL. Input dalam task ini yaitu berupa suatu narasi dan pertanyaannya, sementara output berupa jawaban dari pertanyaan tersebut. Sama seperti text summarization, terdapat pendekatan ekstraktif yang mengambil jawaban dari narasi dan pendekatan abstraktif yang menghasilkan jawaban yang benar-benar baru. Untuk dataset sendiri, sepertinya belum terdapat dataset Bahasa Indonesia yang cukup untuk digunakan sebagai benchmark sehingga Cahyawijaya et al. (2021) menggunakan dataset multi-lingual yang mengcover Bahasa Indonesia.
Chit-chat
Mirip seperti Question answering, dalam task ini sistem akan menjawab atau membalas chat. Perbedaannya, dalam chit-chat tidak diperlukan suatu konteks untuk sistem membalas chat. Konteks akan didapatkan dari histori percakapan yang ada. Maka, sistem ini dilatih dengan input berupa percakapan (dialogue) dan historinya kemudian output berupa balasan (utterance) dari percakapan tersebut. Meski tidak diperlukan suatu konteks bagi sistem untuk membalas percakapan, terdapat juga penelitian yang menggunakan konteks, salah satunya berupa kepribadian. Maka, inputnya yang berupa dialog akan ditambahkan konteks yang digunakan untuk menghasilkan balasan yang diharapkan. Cahyawijaya et al. (2021) menggunakan dataset multi-lingual dengan konteks berupa kepribadian. Salah satu produk dari penelitian ini yaitu chatbot yang banyak digunakan oleh perusahaan.
Terlepas dari berbagai topik dalam NLG, model-model NLG terkenal dengan kesulitan evaluasinya. Metrik-metrik automatis yang ada tidaklah cukup untuk merepresentasikan performa sebenarnya dari model yang menghasilkan bahasa manusia. Maka dari itu, banyak penelitian yang melibatkan manusia, terutama yang ahli dalam bidangnya, untuk mengevaluasi bahasa yang dihasilkan oleh model.
Kesimpulan
NLG merupakan suatu bidang yang belakangan ini mendapatkan perhatiannya kembali dengan adanya model yang lebih canggih seperti GPT-2. Penelitian dalam bidang ini di Indonesia juga mulai berkembang dengan adanya penelitian benchmark, terlepas dari evaluasinya yang sulit. Tentu saja tidak hanya penelitiannya, aplikasinya dalam berbagai bidang juga banyak digunakan oleh berbagai instansi dan organisasi. Disamping kegunaannya dalam berbagai bidang, model-model ini memuncul isu-isu seperti penyalahgunaan model. Bahasa yang dihasilkan oleh model juga bisa memiliki bias dalam hal agama, ras, etnis, dan gender yang merupakan topik sensitif, dan banyak peneliti yang memperjuangkan kesetaraannya dalam model bahasa.
Referensi
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Cahyawijaya, S., Winata, G. I., Wilie, B., Vincentio, K., Li, X., Kuncoro, A., … & Fung, P. (2021). IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation. arXiv preprint arXiv:2104.08200.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. & Sutskever, I. (2018). Language Models are Unsupervised Multitask Learners.
- https://srinidiveer11.medium.com/introduction-to-natural-language-generation-1a942cc2720
- https://medium.com/sciforce/a-comprehensive-guide-to-natural-language-generation-dd63a4b6e548
- https://www.ibm.com/blogs/watson/2020/11/nlp-vs-nlu-vs-nlg-the-differences-between-three-natural-language-processing-concepts/