
Vision Language Models: Menyatukan Gambar dan Teks dengan Clip dan Blip
 Source: AI Generated Image | Midjourney
Source: AI Generated Image | Midjourney
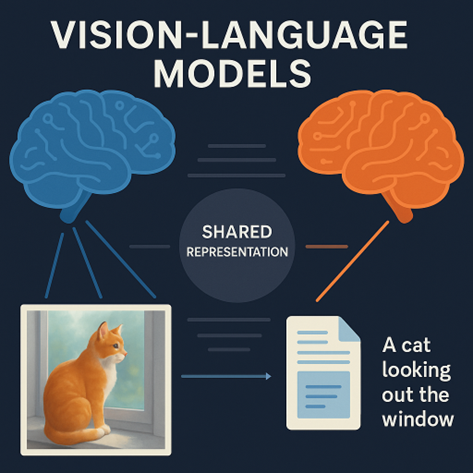
Bayangkan Anda melihat sebuah gambar seekor kucing duduk di atas meja sambil memandangi jendela. Secara naluri, otak kita langsung bisa menyimpulkan bahwa “Kucing itu sedang melihat keluar jendela.” Kalimat ini terdengar sederhana, tetapi bagi sistem artificial intelligence (AI), menghubungkan gambar dan teks seperti itu adalah sebuah tantangan besar.
Selama bertahun-tahun, dunia AI terbagi menjadi dua kelompok besar, yaitu Natural Language Processing (NLP) dan Computer Vision (CV). Masing-masing berkembang pesat, tetapi berjalan sendiri-sendiri tanpa kemampuan untuk saling memahami. Padahal dalam kehidupan nyata, teks dan gambar selalu saling melengkapi. Iklan, media sosial, laporan medis, hingga e-commerce, semuanya mengandalkan makna dari gabungan visual dan kata-kata. GeeksforGeeks (2024), menjelaskan bahwa kemampuan utama dari Vision-Language Models (VLMs) adalah mentransformasikan informasi dari dua domain berbeda, yaitu visual dan linguistic ke dalam satu ruang representasi yang sama. Hal ini memungkinkan sistem untuk menyamakan pemahaman antara teks dan gambar tanpa memerlukan pelabelan manual untuk setiap tugas. Dengan pendekatan ini, model bisa membandingkan, menghubungkan, dan menggeneralisasi makna dari keduanya secara efisien.
Hal Inilah yang melahirkan VLMs, model AI modern yang dirancang untuk memahami dan mengolah gambar dan teks secara bersamaan. Dua model paling ikonik dalam bidang ini adalah CLIP dari OpenAI dan BLIP dari Salesforce Research. Keduanya telah mengubah arah perkembangan AI ke arah yang lebih “multimodal”, di mana visual dan bahasa tidak lagi berdiri terpisah, melainkan menyatu dalam satu pemahaman terpadu.
CLIP: Belajar dari Internet, Tanpa Label Manual
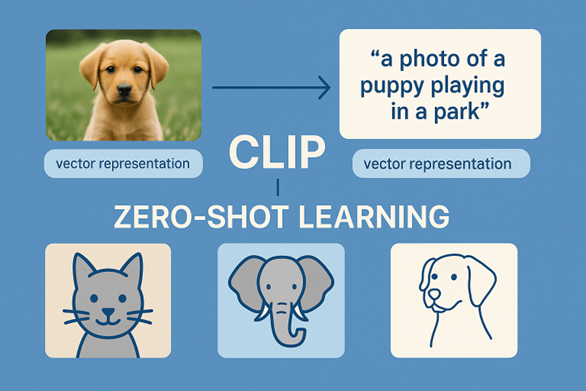
Contrastive Language-Image Pretraining (CLIP) yang diperkenalkan oleh OpenAI pada tahun 2021 adalah sebuah terobosan besar. Model ini dilatih menggunakan lebih dari 400 juta pasangan gambar dan deskripsi teks yang dikumpulkan dari internet (Radford et al., 2021). Tidak seperti model klasifikasi gambar biasa yang membutuhkan label manual seperti “anjing”, “meja”, atau “apel”, CLIP belajar langsung dari bahasa alami, seperti kalimat “sebuah foto anak anjing bermain di taman”. Cara kerja CLIP mirip seperti otak manusia, di mana model ini membuat representasi vektor dari gambar dan teks, lalu mencocokkannya. Jika gambar dan teks memiliki makna yang sama, representasinya akan dekat. Jika berbeda, maka sebaliknya. Hal tersebut adalah prinsip contrastive learning, yaitu belajar dengan cara membedakan mana pasangan yang cocok dan mana yang tidak.
Efeknya sangat luar biasa. Melalui teknik ini, CLIP bisa langsung mengklasifikasikan gambar-gambar baru tanpa harus dilatih khusus, yang dikenal sebagai kemampuan zero-shot learning. Anda cukup memberi daftar deskripsi seperti “gambar kucing”, “gambar anjing”, atau “gambar gajah”, dan CLIP akan tahu gambar mana yang cocok dengan deskripsinya tanpa memerlukan fine tuning tambahan. Lebih menarik lagi, CLIP sangat tangguh di dunia nyata. Model ini bisa memahami meme, logo, ilustrasi, bahkan sketsa tangan. Kemampuan ini menjadikannya cocok digunakan dalam pencarian visual, sistem rekomendasi berbasis gambar, hingga sebagai otak di balik sistem seperti DALL-E atau Google Lens.
Source: AI Generated Image | Midjourney
BLIP: Memberi Makna, Bukan Sekadar Mencocokkan
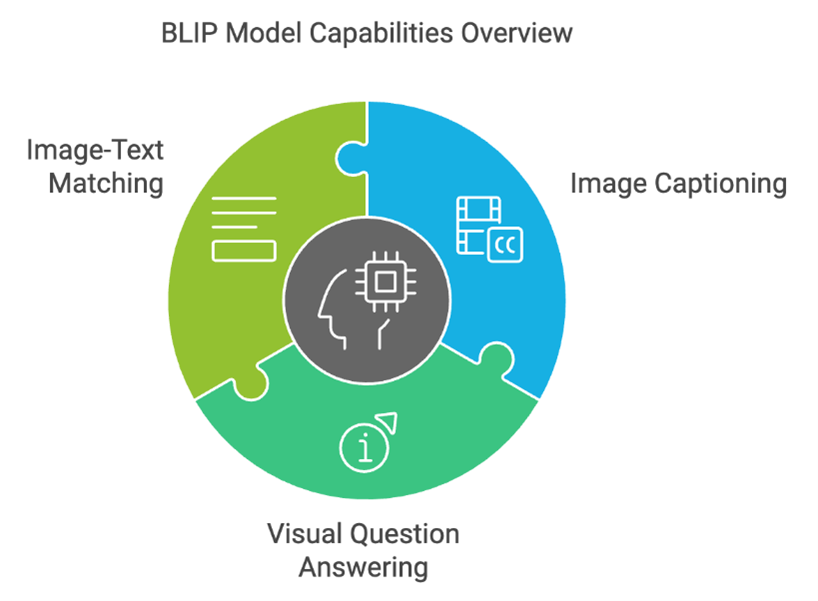
Meski CLIP hebat dalam mencocokkan gambar dan teks, model tersebut tidak dirancang untuk menghasilkan bahasa. CLIP bisa tahu bahwa gambar ini cocok dengan kalimat tersebut, tetapi tidak bisa membuat deskripsi dari gambar tersebut. Di sinilah Bootstrapped Language Image Pretraining (BLIP) mengambil peran. BLIP dikembangkan untuk tugas-tugas seperti image-text matching (mencocokan gambar dengan teks), image captioning (membuat teks deskripsi dari gambar), dan visual question answering (menjawab pertanyaan berdasarkan gambar). Model ini memadukan kekuatan vision encoder dan language decoder agar bisa memahami gambar lalu mengekspresikannya dalam bahasa (Li et al., 2023).
Source: punyakeerthi BL via medium.com (2024)
Strategi unik BLIP adalah bootstrapping, yaitu memulai dari data besar dan “kotor” seperti CLIP, lalu secara bertahap menyempurnakan dirinya melalui pelatihan ulang dengan data yang lebih terstruktur. Versi lanjutan yaitu BLIP-2, bahkan menggunakan Large Language Models (LLM) seperti T5 atau OPT untuk menerjemahkan informasi visual menjadi kalimat. Hasilnya sangat impresif, BLIP-2 bisa menghasilkan deskripsi yang kaya konteks dan menjawab pertanyaan dengan nuansa bahasa yang alami.
Penerapan di Dunia Nyata
Kemampuan untuk memahami gambar dan teks secara bersamaan membuka begitu banyak peluang di dunia nyata. Di bidang medis, sistem seperti CLIP dan BLIP bisa membaca gambar X-ray atau MRI, lalu memberi diagnosis awal berdasarkan laporan radiologi (Zhou et al., 2022). Hal ini tidak menggantikan dokter, tetapi membantu mereka memproses data dengan lebih cepat dan akurat. Pada dunia e-commerce, VLMs memungkinkan pengguna mencari produk tidak hanya dengan teks, tetapi juga dengan gambar. Anda bisa memotret sepatu yang Anda lihat di jalan dan mengetik, “sepatu hitam model ini” dan sistem akan mencari produk yang sesuai. Pinterest, Shopee, dan Amazon sudah mulai mengintegrasikan teknologi ini. Di bidang keamanan, sistem pengawasan pintar bisa mendeteksi situasi tertentu berdasarkan kombinasi gambar CCTV dan deskripsi aktivitas mencurigakan. Misalnya: “seseorang meninggalkan tas tanpa pengawasan”, sebuah kalimat yang dulu hanya bisa dimengerti oleh manusia, kini bisa dimengerti oleh mesin juga.
Meski potensinya besar, Vision-Language Models juga menghadapi tantangan. Salah satu masalah utama adalah bias dalam data karena CLIP dan BLIP belajar dari internet. Kedua model tersebut bisa menyerap bias sosial, stereotip, atau informasi yang tidak akurat. Selain itu, seperti yang dijelaskan oleh Kerem (2023), tantangan lainnya terletak pada bagaimana menyelaraskan representasi dari dua jenis informasi yang secara alami sangat berbeda. Tidak semua gambar memiliki padanan teks yang sepadan secara semantik sehingga dibutuhkan teknik pelatihan khusus seperti alignment loss, augmentasi pasangan negatif, dan pretraining multimodal untuk mengurangi kesalahan pemahaman. Namun tren ke depan sudah cukup jelas, yaitu model multimodal akan menjadi fondasi sistem AI yang lebih “cerdas” dan “alami.” OpenAI sendiri telah memperkenalkan GPT-4-Vision, Google meluncurkan Gemini, dan Meta mengembangkan ImageBind. Semua model tersebut berbasis pada prinsip menggabungkan berbagai jenis data untuk memberikan pemahaman yang lebih mendalam. Dengan kata lain, masa depan AI bukan hanya bisa membaca atau melihat, tetapi juga bisa memahami keduanya secara sekaligus. Bagaimana menurut mu?
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
GeeksforGeeks. (2024). Vision Language Models (VLMs) Explained. Retrieved from https://www.geeksforgeeks.org/vision-language-models-vlms-explained/. Di akses 25 Mei 2025.
Kerem, A. (2023). What Are Visual Language Models and How Do They Work? Medium. https://medium.com/@aydinKerem/what-are-visual-language-models-and-how-do-they-work-41fad9139d07. Di akses 25 Mei 2025.
Li, J., Li, D., Xiong, C., & Hoi, S. C. (2023). BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv preprint arXiv:2301.12597. https://arxiv.org/abs/2301.12597.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. Proceedings of the International Conference on Machine Learning (ICML). https://arxiv.org/abs/2103.00020.
Zhou, H. Y., Yang, J., Zhang, P., Wu, Q., & Zhou, J. T. (2022). Generalized Radiograph Representation Learning via Cross-supervision between Images and Free-text Radiology Reports. Nature Machine Intelligence, 4, 32–40. https://www.nature.com/articles/s42256-021-00429-1.