
AI Model Theft is Real and It’s Already Happening

Seiring dengan pesatnya adopsi Artificial Intelligence (AI) dalam layanan publik dan komersial, model machine learning (ML) kini dianggap sebagai aset digital berharga yang menyimpan investasi besar berupa data, algoritma, dan waktu komputasi. Namun, kemajuan ini juga menghadirkan risiko baru, yaitu AI model theft atau pencurian model AI. Pelaku dapat mencuri atau meniru model hanya dengan mengakses API, tanpa harus mengetahui arsitektur atau parameter internalnya. Hal ini menjadi ancaman serius, terutama bagi perusahaan yang menyediakan layanan ML-as-a-Service (MLaaS). Model yang berhasil dicuri tidak hanya mengakibatkan kerugian finansial, tetapi juga potensi penyalahgunaan teknologi.
What is Model Theft?
Model theft atau model extraction attack adalah serangan yang memungkinkan pihak tidak berwenang meniru perilaku model AI dengan cara mengeksploitasi interaksi input–output dari sistem target. Pada banyak kasus, pelaku tidak memiliki akses terhadap struktur internal atau parameter model, tetapi mampu merekonstruksi model baru yang mendekati performa aslinya. Serangan ini sering terjadi pada model yang diakses publik melalui API dan melibatkan teknik black-box maupun white-box.
Pencurian model AI dapat berdampak pada hilangnya hak kekayaan intelektual, penurunan keunggulan kompetitif, dan potensi replikasi model untuk tujuan jahat, seperti deepfake, bypass moderation, atau penyalahgunaan sistem rekomendasi. Selain itu, pencurian ini sering kali dilakukan secara diam-diam dan sulit terdeteksi karena pola akses API dapat menyerupai aktivitas pengguna biasa.
Hal ini dijelaskan secara visual pada Gambar di bawah, di mana proses model extraction dimulai dari pengiriman query oleh penyerang ke model target, diikuti dengan penerimaan prediksi dari model asli dan berlanjut pada pelatihan ulang shadow model menggunakan data penyerang. Shadow model yang dilatih ini pada akhirnya dapat meniru perilaku model asli tanpa pernah mengetahui struktur internalnya, menghasilkan apa yang disebut sebagai stolen model. Proses ini menggambarkan bagaimana model bisa disalin sepenuhnya dari luar, bahkan tanpa akses fisik atau kode sumber.
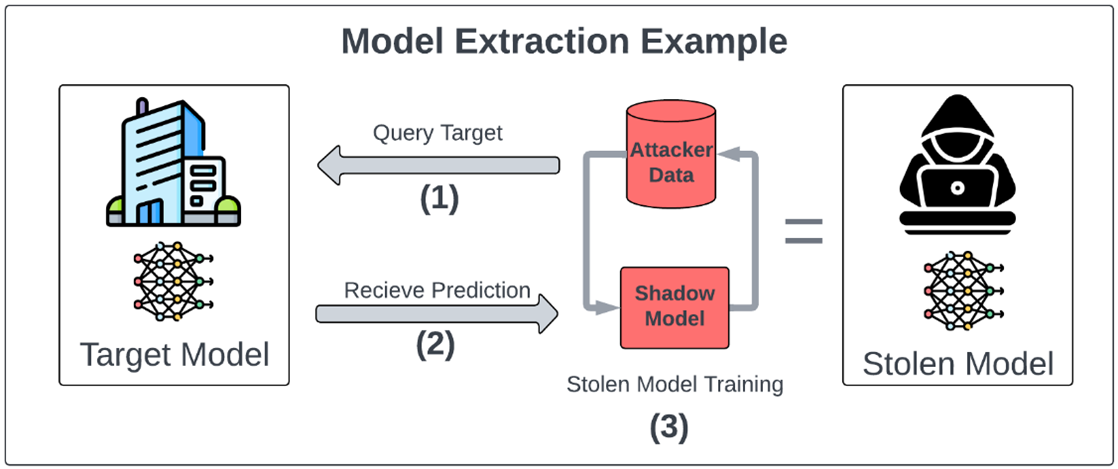
Source: Birch (2025) via MindGard
Type of Attacks
Seiring berkembangnya pemanfaatan AI dalam layanan publik, beragam teknik pencurian model telah diidentifikasi dan dikategorikan berdasarkan pendekatannya. Masing-masing jenis serangan memiliki tujuan dan risiko yang berbeda, mulai dari mereplikasi fungsi model secara utuh hingga mengekspos data pribadi yang digunakan selama pelatihan. Pada konteks ini, penting untuk memahami bagaimana serangan dilakukan agar pertahanan yang dibangun bisa disesuaikan secara efektif. Berikut adalah tiga jenis utama serangan terhadap model AI yang umum ditemukan dalam skenario model theft:
Query-Based Extraction
Jenis serangan ini dilakukan dengan mengirimkan banyak query ke API model dan mencatat responsnya. Penyerang menggunakan data ini untuk melatih ulang model tiruan (knockoff model). Serangan ini sangat umum pada sistem black-box karena hanya membutuhkan akses input-output. Nightfall.AI (2025) menyebut ini sebagai salah satu metode paling praktis dan berbahaya karena sulit dibedakan dari penggunaan normal.
1. Model Inversion
Pada serangan ini, penyerang mencoba membalikkan representasi internal model untuk merekonstruksi data pelatihan asli. Hal ini sangat berisiko ketika model dilatih dengan data sensitif seperti wajah, catatan medis, atau biometrik. OWASP (2024) menyebutkan bahwa model inversion dapat mengungkap informasi pribadi dari output klasifikasi.
2. Membership Inference
Membership inference attack bertujuan untuk menentukan apakah sebuah data spesifik pernah digunakan dalam proses pelatihan model. Jika berhasil, ini dapat melanggar privasi dan digunakan untuk mengekspos bias atau kerentanan dalam model. Menurut Soler (2024) via NeuralTrust, serangan ini menjadi semakin relevan dalam konteks regulasi data seperti GDPR.
3. Defense Against Model Theft
Pada menghadapi ancaman pencurian model AI yang semakin kompleks, strategi pertahanan perlu dirancang secara menyeluruh dan berlapis. Pendekatan ini umumnya terbagi menjadi dua kategori utama: reactive defence, yang merespons setelah aktivitas mencurigakan terdeteksi, dan proactive defence, yang dirancang untuk mencegah serangan sebelum terjadi. Keduanya memiliki peran penting dalam membangun sistem AI yang aman dan tahan terhadap eksploitasi eksternal.
4. Reactive Defence
Reactive defence difokuskan pada kemampuan sistem untuk mendeteksi dan merespons serangan setelah aktivitas mencurigakan atau upaya pencurian model terjadi. Meskipun bersifat pasif, langkah-langkah ini sangat penting untuk memantau ancaman dan menindak pelanggaran secara tepat waktu.
Langkah-langkah reaktif berfokus pada mendeteksi dan merespons upaya pencurian setelah serangan berlangsung adalah sebagai berikut.
- Rate Limiting & Monitoring: Membatasi jumlah query yang dikirim dalam jangka waktu tertentu dan memantau pola interaksi.
- Watermarking: Menyisipkan tanda tersembunyi dalam model atau output yang dapat digunakan untuk membuktikan kepemilikan jika terjadi sengketa.
- Explainability Filtering: Mengurangi informasi interpretatif (seperti attention maps) yang dapat membantu pelaku memahami logika internal model.
5. Proactive Defence
Berbeda dengan langkah reaktif, strategi proactive defence bertujuan untuk mencegah pencurian model sejak awal. Pendekatan ini berfokus pada rekayasa sistem dan keamanan model yang membuat proses ekstraksi menjadi tidak efektif atau bahkan tidak mungkin dilakukan. Pertahanan proaktif bertujuan mencegah serangan sebelum terjadi, yaitu sebagai berikut (Soler, 2024; Benjamin & Thomas, 2025).
- Output Perturbation: Menambahkan noise kecil yang tidak signifikan bagi pengguna sah, tetapi merusak akurasi pelatihan ulang model curian.
- Differential Privacy: Mengurangi kemungkinan pelaku mendapatkan informasi sensitif dengan menyesuaikan sensitivitas model terhadap data individual.
- Secure Environments: Menjalankan model hanya dalam lingkungan yang terenkripsi dan terpercaya seperti Intel SGX.
- DeepDefense: Sebuah pendekatan yang mengubah gradien model agar hasilnya tidak bisa digunakan secara efektif untuk melatih ulang model (Lee et al., 2022).
Real-World Case
Pada studi oleh Lee et al. (2022), diperkenalkan metode DeepDefense yang berhasil menurunkan akurasi model hasil curian tanpa memengaruhi kinerja model asli. Strategi ini melibatkan pembuatan model bayangan (shadow model) dengan gradien orthogonal untuk menyesatkan proses pembelajaran ulang oleh penyerang. Teknik ini terbukti efektif dalam membuat hasil pelatihan ulang tidak konsisten, meskipun output awal dari model asli tampak normal.
Sementara itu, laporan OWASP (2024) menekankan bahwa penyedia layanan LLM seperti chatbot rentan terhadap serangan model theft melalui pencatatan masif input-output. Soler (2024) juga menyarankan kombinasi taktik pertahanan, termasuk pembatasan interpretabilitas dan pemantauan API berbasis machine learning. Pendekatan ini membantu organisasi mendeteksi pola eksploitasi lebih awal sebelum model benar-benar terekspos.
Legal Risk and Challenges
DeCarlo (2025) melalui TechTarget menekankan bahwa salah satu hambatan utama dalam menangani model theft adalah lemahnya perlindungan hukum atas model AI. Dalam banyak yurisdiksi, model AI, terutama representasi seperti bobot neural network atau arsitektur model tidak secara eksplisit dilindungi oleh hukum hak cipta karena sifatnya yang dianggap sebagai proses atau metode, bukan ekspresi kreatif. Hal ini menyulitkan pemilik model untuk mengklaim pelanggaran jika modelnya disalin tanpa izin. Sementara itu, hak paten membutuhkan proses panjang dan tidak semua model layak dipatenkan karena terus berevolusi.
Meskipun trade secret dan kontrak lisensi dapat memberikan perlindungan secara parsial, penerapannya sangat bergantung pada penegakan yang kuat, yang kerap kali sulit diimplementasikan dalam konteks global atau layanan lintas negara. Perusahaan yang tidak memiliki sistem audit dan dokumentasi yang baik bisa kesulitan membuktikan bahwa suatu model telah dicuri. Oleh karena itu, organisasi harus bersikap proaktif dengan menerapkan kombinasi mekanisme teknis, seperti watermarking dan logging, serta memperkuat pengawasan akses API untuk mencegah dan mendeteksi upaya pencurian sebelum eskalasi terjadi.
Kesimpulan
Model theft adalah tantangan nyata dalam dunia AI modern yang tidak hanya berdampak pada kerugian finansial, tetapi juga mengancam integritas dan kepercayaan publik terhadap sistem AI. Serangan ini bisa terjadi secara diam-diam dan tanpa bekas yang jelas, membuat banyak organisasi tidak menyadari bahwa aset intelektual mereka telah direplikasi secara ilegal. Pada ekosistem AI yang semakin terbuka dan terhubung melalui layanan API, risiko semacam ini menjadi sangat signifikan, terutama ketika model yang telah dikembangkan dengan investasi besar diekspos tanpa perlindungan memadai.
Dengan meningkatnya kecanggihan teknik pencurian model, pendekatan pertahanan harus bersifat adaptif dan berlapis. Hal ini mencakup strategi reaktif seperti rate limiting dan watermarking untuk merespons aktivitas mencurigakan, serta strategi proaktif seperti DeepDefense, output pertubation, dan pembatasan interpretasi model untuk mencegah serangan sejak awal. Pemahaman menyeluruh terhadap vektor serangan, serta kesiapan sistem dalam mendeteksi pola eksploitasi yang tidak biasa, menjadi elemen penting dalam merancang pertahanan AI yang efektif. Lebih dari itu, dibutuhkan kolaborasi antara pendekatan teknis, kebijakan keamanan internal, dan regulasi hukum yang progresif untuk memastikan bahwa kemajuan AI tidak dibarengi dengan risiko pencurian intelektual yang dibiarkan terbuka.
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Benjamin, E., & Thomas, S. (2025). Model Theft and Intellectual Property Protection in AI Systems. International Journal of Research and Analytical Reviews.
Birch, L. (2025). AI Under Attack: Six Key Adversarial Attacks and Their Consequences. MindGard. https://mindgard.ai/blog/ai-under-attack-six-key-adversarial-attacks-and-their-consequences. Di akses 28 Juli 2025.
DeCarlo, A. L. (2025). AI model theft: Risk and mitigation in the digital era. TechTarget. https://www.techtarget.com/searchsecurity/tip/AI-model-theft-Risk-and-mitigation-in-the-digital-era. Di akses 28 Juli 2025.
Lee, J., Han, S., & Lee, S. (2022). Model Stealing Defense against Exploiting Information Leak through the Interpretation of Deep Neural Nets. Proceedings of the Thirty-First Joint Conference on Artificial Intelligence (IJCAI-22).
Nightfall.AI. (2025). Model Theft: The Essential Guide. Nightfall.AI. https://www.nightfall.ai/ai-security-101/model-theft. Di akses 28 Juli 2025.
OWASP. (2024). LLM10: Model Theft. OWASP Foundation. https://genai.owasp.org/llmrisk2023-24/llm10-model-theft. Di akses 28 Juli 2025.
Soler, J. (2024). Understanding and Preventing AI Model Theft: Strategies for Enterprise. NeuralTrust. https://neuraltrust.ai/blog/understanding-and-preventing-ai-model-theft-strategies-for-enterprises. Di akses 28 Juli 2025.