
FastVLM: Revolusi Vision-Language Apple yang 85x Lebih Cepat dari Model Serupa
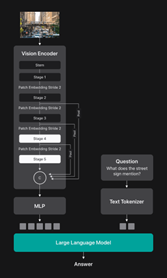
Fig 1. Overview of the FastVLM architecture. (Apple Machine Learning Research, 2025).
Ketika dunia kecerdasan buatan (AI) terus bergerak menuju pengalaman multimodal di mana gambar, teks, dan suara dapat diproses sekaligus. Diawal bulan september 2025 ini, Apple kembali menghadirkan gebrakan dengan merilis FastVLM (Fast Vision-Language Model). Inovasi ini bukan hanya soal kecepatan, melainkan juga tentang bagaimana Apple mengubah cara kita melihat integrasi vision-language models (VLM) di perangkat sehari-hari. Klaim paling mencolok: FastVLM mampu memberikan time-to-first-token (TTFT) hingga 85 kali lebih cepat dibandingkan model serupa.
Apa Itu FastVLM?
FastVLM merupakan vision-language model terbaru dari Apple yang dirancang untuk memahami hubungan antara gambar dan bahasa secara simultan. Dengan kata lain, model ini memungkinkan perangkat untuk “melihat” sebuah gambar atau video, lalu menjelaskan atau menjawab pertanyaan tentangnya dalam bentuk bahasa alami. Contoh sederhana penerapan FastVLM adalah ketika pengguna mengambil gambar dengan iPhone lalu meminta asisten AI menjelaskan isi foto, membuat caption otomatis, atau bahkan melakukan terjemahan visual secara real-time. Teknologi ini membuka jalan bagi interaksi manusia–mesin yang lebih natural, cepat, dan kontekstual. Keunggulan FastVLM bukan hanya pada pemahaman multimodal, tetapi juga pada efisiensi kecepatan inferensi yang belum pernah dicapai sebelumnya.
Salah satu terobosan utama dalam FastVLM adalah hadirnya FastViTHD (Fast Vision Transformer Hybrid Downsampling), sebuah arsitektur encoder vision baru yang dikembangkan Apple. Berdasarkan artikel Apple ML Research yang berjudul Efficient Vision Encoding dikatakan arsitektur ini menggabungkan pendekatan convolution dan transformer untuk mengatasi dua masalah klasik VLM:
- Resolusi tinggi membutuhkan banyak token visual – yang biasanya memperlambat model.
- Trade-off antara akurasi dan efisiensi – model cepat sering kali mengorbankan kualitas pemahaman visual.
FastViTHD hadir sebagai solusi dengan cara mengurangi jumlah token visual secara cerdas tanpa kehilangan detail penting. Hasilnya adalah proses encoding yang lebih ringan, hemat memori, tetapi tetap akurat. Dengan desain ini, FastVLM dapat memproses gambar resolusi tinggi dengan kecepatan luar biasa, membuatnya ideal untuk aplikasi real-time.
Perbandingan dengan Model Lain
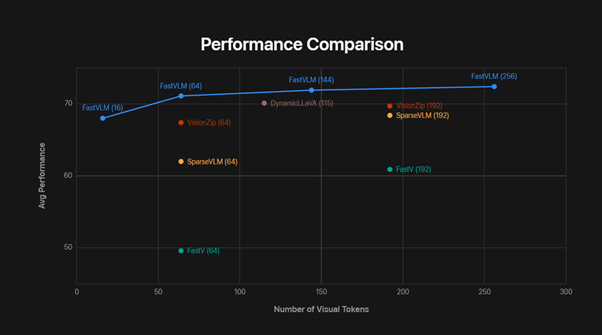
Fig 2. Performance comparison of FastVLM (Apple Machine Learning Research, 2025).
Kehebatan FastVLM terlihat jelas saat dibandingkan dengan model vision-language populer lain:
- 85x lebih cepat dari LLaVA-OneVision dalam hal time-to-first-token.
- Ukuran model lebih kecil (0.5B parameter), namun performa tetap kompetitif dengan model besar.
- Dibandingkan Cambrian-1 dan model open-source lain, FastVLM unggul dalam efisiensi kecepatan + konsumsi memori.
Artinya, Apple berhasil mematahkan paradigma lama bahwa model vision-language harus besar dan berat untuk bisa bekerja optimal. FastVLM menunjukkan bahwa kecil, cepat, dan efisien bisa tetap berarti tajam, presisi, dan relevan. Keunggulan teknis FastVLM bukan hanya sekadar catatan akademis. Apple telah menekankan bahwa model ini dibuat agar benar-benar dapat digunakan dalam ekosistem perangkat mereka. Beberapa contoh penerapan:
Video Captioning Real-Time
FastVLM dapat menghasilkan deskripsi otomatis untuk video dengan kecepatan yang membuatnya terasa seolah-olah pengguna berbicara dengan penerjemah instan.
Assistive Technology untuk Aksesibilitas
Bayangkan seorang pengguna tunanetra yang mengarahkan kamera iPhone ke sebuah objek, lalu perangkat langsung memberikan deskripsi suara secara cepat.
Augmented Reality (AR) & Virtual Reality (VR)
Dalam konteks AR/VR, FastVLM bisa digunakan untuk mengenali objek di sekitar pengguna dan menyajikan informasi tambahan dalam hitungan detik, meningkatkan imersi dan interaksi.
Privasi Terjaga dengan On-Device AI
Seluruh proses dapat dijalankan langsung di perangkat (iPhone, iPad, Mac) tanpa perlu mengirim data ke server eksternal. Hal ini menjaga privasi pengguna sekaligus mempercepat respons.
Kesimpulan
FastVLM adalah lebih dari sekadar inovasi teknis; ia adalah simbol strategi Apple dalam menghadirkan AI yang cepat, hemat, dan aman langsung ke tangan pengguna. Dengan kecepatan 85 kali lipat lebih cepat dibandingkan model vision-language populer, FastVLM menunjukkan bahwa kompromi antara kecepatan, ukuran, dan akurasi kini bisa diatasi.
Ke depan, FastVLM berpotensi menjadi fondasi bagi berbagai aplikasi baru, mulai dari video captioning real-time, AR/VR interaktif, hingga teknologi aksesibilitas yang lebih inklusif. Jika model AI sebelumnya sering kali hanya hidup di pusat data raksasa, FastVLM menghadirkan revolusi dengan membawanya langsung ke perangkat personal—sebuah langkah besar menuju masa depan di mana AI cepat, presisi, dan privat bukan lagi mimpi, melainkan kenyataan sehari-hari.
Penulis:
Samson Ndruru
FDP Scholar
Daftar Pustaka:
- Apple Machine Learning Research. (2025, September). Fast vision-language models. Apple. https://machinelearning.apple.com/research/fast-vision-language-models
- Apple Machine Learning Research. (2025, September). FastVLM: Efficient vision encoding. Apple. https://machinelearning.apple.com/research/fastvlm-efficient-vision-encoding
- Ultralytics. (2025, September 1). FastVLM: Apple introduces its new fast vision-language model. Ultralytics. https://www.ultralytics.com/blog/fastvlm-apple-introduces-its-new-fast-vision-language-model
- Koshurai, A. (2025, September 3). Apple’s FastVLM: Redefining vision-language models with speed, scale, and precision. Medium. https://koshurai.medium.com/apples-fastvlm-redefining-vision-language-models-with-speed-scale-and-precision-8a4ef584b156