
Penetration Testing pada Model AI: Mengungkap Celah Keamanan Model Artificial Intelligence

Source: Midjourney
Seiring meningkatnya adopsi artificial intelligence (AI) dalam berbagai sektor seperti keuangan, kesehatan, militer, dan layanan publik, ancaman terhadap sistem AI pun ikut berkembang. Model AI kini tak hanya digunakan untuk memprediksi atau merekomendasikan, tetapi juga menjalankan proses pengambilan keputusan penting. Pada konteks ini, aspek keamanan menjadi sangat krusial. Sayangnya, banyak sistem AI yang dibangun tanpa pertimbangan keamanan mendalam, terutama terhadap serangan seperti adversarial input, data poisoning, atau eksploitasi inferensi.
Untuk memastikan sistem AI cukup tangguh, pendekatan penetration testing (pentesting) mulai diterapkan secara khusus pada model dan arsitektur AI. Namun, AI pentesting bukan sekadar memperlakukan AI sebagai aplikasi web biasa, ia memerlukan pemahaman mendalam tentang arsitektur model, proses pelatihan, serta bagaimana AI merespons input. Pengujian ini menjadi alat penting untuk mengidentifikasi celah, memahami risiko nyata, dan memperkuat sistem sebelum disalahgunakan.
What is AI Penetration Testing?
AI Penetration Testing adalah praktik menguji sistem AI untuk menemukan celah keamanan, baik dari sisi model, data, maupun sistem pendukungnya. Tidak seperti penetration testing tradisional yang menargetkan sistem IT seperti server, jaringan, atau aplikasi, AI pentesting harus memperhitungkan karakteristik unik dari sistem AI, mulai dari proses pelatihan, distribusi data, hingga kemampuan adaptif model terhadap input yang kompleks dan kontekstual (Tjoa et al., 2020). Dalam konteks ini, vektor serangan bisa muncul tidak hanya dari arsitektur sistem, tetapi juga dari logika internal model dan perilaku output-nya yang sulit diprediksi.
AI penetration testing merupakan cabang khusus dalam cybersecurity di mana para ethical hacker mengadaptasi teknik eksploitasi untuk menghadapi tantangan unik AI. Berbeda dengan alat keamanan konvensional yang cenderung kesulitan dalam mendeteksi bias model, manipulasi data, atau eksploitasi berbasis prompt, AI pentesting dirancang untuk menyasar kerentanan seperti unauthorized inference, jailbreak LLM, atau model hallucination (OffSec Team, 2025). Teknik ini semakin penting karena AI kini digunakan dalam berbagai sektor kritikal, dari keuangan hingga kesehatan yang menuntut sistem pengambilan keputusan berbasis AI tetap dapat diandalkan, tidak dapat dimanipulasi, dan aman dari ancaman cyber yang semakin canggih. Melalui pentest yang menyeluruh, tim keamanan dapat melindungi data sensitif, mencegah penyalahgunaan model, dan memastikan integritas sistem AI tetap terjaga secara holistik.
A Hacker’s Perspective
Dari sudut pandang penyerang, model AI merupakan target yang sangat menarik karena dua alasan utama, yaitu kompleksitas algoritmik dan keterbukaan akses. Banyak sistem AI modern dapat diakses publik melalui API, chatbot, layanan rekomendasi, atau interface lain yang memungkinkan interaksi terbuka. Hal ini membuka peluang bagi penyerang untuk mengeksplorasi dan mengeksploitasi perilaku prediksi model, memanipulasi input untuk menghasilkan output yang diinginkan, atau mengakses informasi yang semestinya bersifat internal. Teknik-teknik seperti prompt injection, adversarial input, dan fuzzing menjadi senjata utama untuk menguji batas sistem, misalnya, meminta model memberikan informasi rahasia, salah klasifikasi, atau bahkan menjalankan instruksi berbahaya dalam konteks agent-based AI Ilhan, 2023).
Menurut Joseph Thacker, masih banyak developer yang belum sepenuhnya memahami kerentanan pada model AI, seperti prompt injection atau bias output (Davies, 2025). Pada praktiknya, banyak aplikasi AI, terutama yang dikembangkan oleh startup atau tim kecil, masih mengandung kerentanan karena kurangnya praktik keamanan yang matang. Bahkan perusahaan besar sekalipun yang terburu-buru meluncurkan fitur AI ke pasar berpotensi melewatkan uji ketahanan karena ekosistem pengembangan AI bergerak lebih cepat dibanding proses audit keamanannya. Mengingat bahwa aplikasi generatif biasanya memproses data sensitif seperti identitas pengguna atau riwayat percakapan, pentesting menjadi elemen penting dalam menjaga kepercayaan pengguna dan memastikan bahwa sistem AI tidak menjadi vektor risiko baru yang tak terdeteksi. Joseph Thacker menekankan bahwa karena AI security masih dalam tahap awal, pentesting berkala bukan hanya penting, tetapi krusial untuk tetap berada di depan munculnya ancaman-ancaman baru yang belum sepenuhnya terpetakan (Davies, 2025).
AI Penetration Testing Methodologies
AI pentesting membutuhkan pendekatan yang tidak dapat sepenuhnya disamakan dengan uji penetrasi pada umumnya. Hal ini karena sistem AI terdiri dari beberapa lapisan yang saling berinteraksi, mulai dari data, algoritma, hingga proses inferensi yang masing-masing menyimpan potensi kerentanan. Pada praktiknya, pendekatan multidisipliner diperlukan untuk menggali potensi serangan dari berbagai sudut. Tjoa et al. (2020) mengusulkan bahwa AI pentesting idealnya menggabungkan tiga dimensi utama, yaitu pendekatan berbasis manajemen risiko, eksplorasi dari perspektif adversarial machine learning, dan integrasi dengan teknik pentest sistem konvensional. Ketiganya membentuk kerangka kerja yang komprehensif untuk menguji trustworthiness, ketahanan, dan integritas sistem AI dalam skenario dunia nyata.
- Risk Management Oriented Testing
Pendekatan ini berfokus pada pemetaan aset digital yang menjadi bagian dari sistem AI dan menilai nilai serta kerentanannya terhadap berbagai tipe ancaman. Tujuan utama adalah mengidentifikasi attack surface, bagian mana dari sistem yang paling mungkin menjadi titik masuk serangan dan menilai potensi dampak jika titik tersebut berhasil dieksploitasi. Contohnya adalah endpoint API yang terbuka ke publik tanpa rate limiting, model AI yang dapat diakses tanpa moderasi input-output, atau sistem rekomendasi yang memiliki bias signifikan. Metodologi ini mirip dengan asset valuation dalam manajemen risiko cyber, dan membantu tim keamanan menentukan prioritas pengujian serta mitigasi.
- Adversarial Machine Learning
Dimensi ini mencakup teknik eksploitasi berbasis manipulasi input terhadap model machine learning untuk mengungkap kelemahan logika atau generalization. Contoh serangannya antara lain adversarial examples, di mana input dimodifikasi sedikit namun cukup untuk menyebabkan kesalahan klasifikasi. Kemudian, model inversion, teknik yang memungkinkan penyerang merekonstruksi data pelatihan dengan memanfaatkan output model. Di sinilah tantangan AI security benar-benar berbeda dengan sistem konvensional karena kerentanannya tidak bersifat statis, melainkan bergantung pada distribusi data dan cara model memproses informasi. Pada banyak kasus, serangan adversarial ini bisa dilakukan tanpa harus memahami struktur internal model (black-box attack), membuatnya sangat relevan untuk pentest praktis.
- Traditional System Pentesting
Pendekatan ini mencakup semua pengujian standar pada infrastruktur pendukung AI, yaitu jaringan, sistem cloud, API, deployment pipeline, dan user interface. Meski terdengar konvensional, aspek ini sangat krusial karena sebagian besar model AI modern dijalankan dalam ekosistem terintegrasi, seperti layanan microservice atau cloud-native environments. Serangan dapat berasal dari kelemahan otentikasi API, insecure data storage, hingga misconfiguration dalam container yang men-deploy model. Di sinilah teknik seperti API fuzzing, injection testing, dan access control validation tetap relevan dan diperlukan dalam pentesting AI yang komprehensif.
How to Perform AI Penetration Testing
Melakukan penetration testing terhadap model AI membutuhkan pendekatan yang sistematis namun fleksibel karena karakter sistem AI tidak selalu deterministik. Berdasarkan tahapan standar seperti yang ditunjukkan dalam ilustrasi, proses pengujian dapat dibagi menjadi empat langkah utama yang berkesinambungan, yaitu sebagai berikut (Ilhan, 2023):
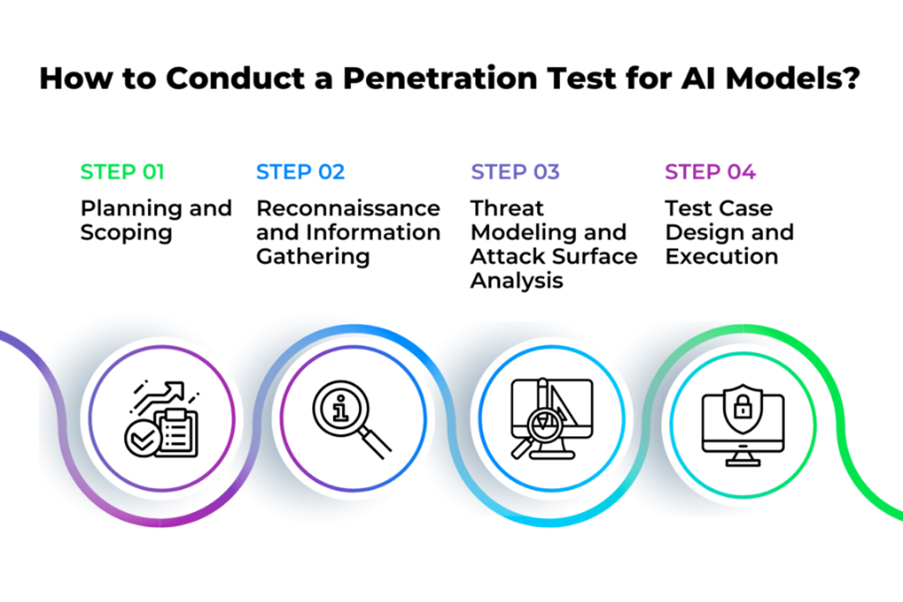
Source: Ilhan (2023) via Zigrin Security
- Step 1: Planning and Scoping
Langkah awal ini menentukan ruang lingkup, tujuan pengujian, dan jenis model AI yang akan diuji. Penetapan parameter ini mencakup identifikasi target (API, agent, dataset), batasan etis dan legal, serta definisi keberhasilan misalnya, pembocoran data, output tidak valid, atau keberhasilan adversarial input.
- Step 2: Reconnaissance and Information Gathering
Fase ini melibatkan pengumpulan informasi tentang arsitektur model, API endpoint, jenis data pelatihan, serta vektor serangan potensial. Teknik seperti fingerprinting model, passive observation, atau bahkan social engineering digunakan untuk membangun pemahaman terhadap permukaan serangan.
- Step 3: Threat Modelling and Attack Surface Analysis
Setelah informasi terkumpul, dilakukan pemetaan risiko berdasarkan arsitektur sistem. Hal ini termasuk eksplorasi terhadap adversarial attack vectors, data leakage paths, dan celah dalam proses input-output. Model threat seperti STRIDE atau DREAD dapat diadaptasi untuk skenario AI.
- Step 4: Test Case Design and Execution
Pengujian dilakukan dengan menyusun skenario eksploitasi, yaitu adversarial perturbation, prompt injection, over-querying, atau fuzzing terhadap model. Hasil dari tiap serangan dievaluasi berdasarkan dampaknya terhadap akurasi, privasi, atau kontrol sistem.
Tools for AI Penetration Testing
Pada pengujian keamanan terhadap sistem AI, pemilihan tools yang tepat sangat penting untuk mengidentifikasi kelemahan secara efektif di berbagai tahap. Tidak seperti pentest tradisional yang umumnya mengandalkan eksploitasi sistem atau jaringan, pentest AI membutuhkan kombinasi alat dari berbagai domain, mulai dari analisis trafik API, rekayasa input adversarial, hingga stress testing terhadap endpoint layanan model. Kumar (2024) menyarankan pendekatan modular dalam memilih tools, di mana tiap fase pengujian ditangani oleh tools yang paling sesuai. Berikut adalah tools yang umum digunakan dalam AI penetration testing, beserta fungsinya:
- Reconnaissance
- Burp Suite: Digunakan untuk mencegat dan menganalisis lalu lintas HTTP/S, termasuk request-response ke endpoint AI. Pentester dapat melihat parameter input, cookies, dan pola autentikasi yang mungkin disalahgunakan.
- Postman: Berguna untuk menguji API AI secara manual, mencoba variasi prompt, parameter, atau payload yang dapat memicu respons tidak terduga dari model.
- Vulnerability Analysis
- OWASP ZAP: Alat open source dari OWASP untuk pemindaian otomatis terhadap API, mencari kerentanan seperti injection, improper authentication, dan exposure data
- TextAttack: Khusus digunakan untuk menghasilkan input-input NLP yang bersifat adversarial pada model LLMs. Alat ini dapat membantu mengevaluasi seberapa mudah model termanipulasi oleh variasi bahasa.
- Exploit Development
- Python Scripting: Digunakan untuk menulis skrip kustom, baik untuk mengotomasi eksploitasi prompt injection, menyusun serangan chained input, maupun melakukan pemantauan output model.
- Foolbox / IBM Adversarial Robustness Toolbox (ART): Dua framework yang sangat populer untuk membangun dan menjalankan serangan adversarial terhadap model machine learning. Cocok untuk mengevaluasi ketahanan klasifikator visual, NLP, atau tabular model.
- Load Testing
- Locust: Framework open source untuk melakukan load testing. Dengan Locust, pentester bisa mengatur skenario pengguna dan mensimulasikan ribuan permintaan untuk mengecek ketahanan sistem terhadap DDoS, over-querying, atau pengurasan sumber daya model.
Challenge and Ethical Considerations
AI penetration testing membawa tantangan unik yang tidak ditemukan dalam pentest tradisional. Seperti ditunjukkan dalam ilustrasi berikut, banyak hambatan teknis dan konseptual yang harus diperhitungkan (Dzemidovich et al., 2025):

Source: Dzemidovich et al. (2025) via SolutionsHub
- Non-deterministic behavior: Model AI tidak selalu memberikan output yang sama untuk input identik, membuat replikasi hasil eksploitasi sulit.
- Hallucinations: Model AI, khususnya LLMs, bisa menghasilkan informasi palsu, menjadikan interpretasi hasil testing lebih rumit.
- Resource-intensive: Beberapa teknik (adversarial training atau gradient inversion) memerlukan sumber daya komputasi besar.
- Full automation sulit dicapai: Banyak serangan membutuhkan pemahaman kontekstual, sehingga tidak bisa diserahkan ke script
- Cultural and social sensitivity: AI dapat mengeluarkan output offensive jika tidak hati-hati. Oleh karena itu, penting untuk menjaga pengujian sesuai dengan etika yang berlaku.
- Lack of frameworks: Belum ada standar umum untuk AI pentesting seperti halnya OWASP untuk aplikasi web.
- Need for creativity: Dibutuhkan pendekatan eksploratif dan intuisi untuk menemukan edge-case bugs atau pola prompt injection.
- Limited expertise: Jumlah pentester yang menguasai AI secara teknikal masih sedikit, mempersempit kemampuan industri dalam menjamin keamanan AI secara menyeluruh.
Conclusion
Penetration testing pada sistem AI merupakan kebutuhan mendesak dalam dunia keamanan cyber. Dengan meningkatnya adopsi AI di sistem kritikal dan publik, permukaan serangan semakin luas dan kompleksitas sistem membuat pendekatan konvensional tidak lagi cukup. Melalui AI pentesting, kita dapat menemukan dan mengatasi kerentanan dari sudut pandang penyerang, sekaligus membangun kepercayaan terhadap teknologi ini. Akan tetapi seperti keamanan itu sendiri, AI pentesting bukan solusi sekali jalan. Ia membutuhkan pendekatan berulang, audit berkala, serta kerjasama antara developer, pentester, dan pembuat kebijakan. Melalui hal tersebut, kita dapat memastikan bahwa sistem AI bekerja sesuai harapan sehingga model tersebut bukan sekadar cerdas, tetapi juga aman.
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Davies, J. B. (2025). Introducing AI Penetration Testing. BugCrowd. https://www.bugcrowd.com/blog/introducing-ai-penetration-testing/#:~:text=AI%20pen%20testing%20frequently%20asked,conduct%20Artificial%20Intelligence%20Penetration%20Testing?. Di akses 28 Juli 2025.
Dzemidovich, V., Veka, S., & Kuwchinov, P. (2025). LLM and AI Penetration Testing in 2025. SolutionsHub. https://solutionshub.epam.com/blog/post/ai-penetration-testing. Di akses 28 Juli 2025.
Ilhan, U. D. (2023). As an AI Language Model, Please Have Mercy on Me. Zigrin Security. https://zigrin.com/as-an-ai-language-model-please-have-mercy-on-me/. Di akses 28 Juli 2025.
Kumar, K. (2024). White Paper: A Practical Guide to Penetration Testing for Generative AI Systems. LinkedIn. https://www.linkedin.com/pulse/white-paper-practical-guide-penetration-testing-generative-kumar-q3duc/. Di akses 28 Juli 2025.
OffSec Team. (2025). AI Penetration Testing: How to Secure LLM Systems. OffSec. https://www.offsec.com/blog/ai-penetration-testing/. Di akses 28 Juli 2025.
Tjoa, S., Buttinger, C., Holzinger, K., & Kieseberg, P. (2020). Penetration Testing Artificial Intelligence. ERCIM NEWS 123:Research and Innovation.