
Fine-Tuning Vision Transformer (ViT) untuk Klasifikasi Gambar
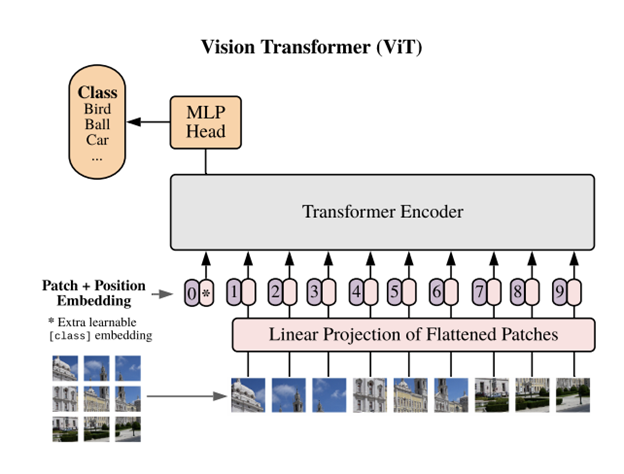
Sumber: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale (dosovitskiy et al. 2020) – https://arxiv.org/abs/2010.11929
Fine-Tuning Vision Transformer (ViT) untuk Klasifikasi Gambar
Vision Transformer (ViT) adalah pendekatan revolusioner dalam bidang computer vision yang memanfaatkan arsitektur transformer, yang mana arsitektur tersebut sebelumnya sukses besar di area Natural Language Processing (NLP). Berbeda dengan Convolutional Neural Networks (CNN) yang mengandalkan operasi lokal berbasis kernel, ViT membagi gambar menjadi patch-patch kecil dan memprosesnya sebagai urutan token, mirip dengan kata dalam kalimat. Pendekatan ini memungkinkan ViT untuk memahami hubungan spasial global dalam gambar secara lebih efektif.
Namun, model ViT, terutama versi besar seperti vit-base dan vit-large dilatih dengan sumber daya komputasi yang masif dan membutuhkan dataset dalam skala besar agar performanya optimal. Untungnya, ada suatu konsep yang bernama transfer learning dan fine-tuning, dengan konsep tersebut kita dapat memanfaatkan bobot pretrained dari model ViT yang dilatih pada dataset besar ImageNet21k dan menyempurnakannya agar sesuai dengan dataset kita yang jauh lebih kecil atau sesuai dengan konteks yang sedang kita kerjakan.
Artikel ini memaparkan panduan teknis secara ringkas tentang bagaimana melakukan fine-tuning Vision Transformer (ViT) menggunakan library Transformers dari Hugging Face, TorchVision, dan dataset dari Hugging Face.
Keunggulan Vision Transformer
- Pretraining model yang fleksibel: Model ViT tersedia dalam berbagai skala dan telah dilatih pada dataset besar seperti ImageNet-21k.
- Global Feature Learning: Attention mechanism memungkinkan model memahami keseluruhan struktur gambar, bukan hanya fitur lokal.
- Integrasi mudah: Tersedia di berbagai library populer seperti Hugging Face, timm, dan keras-cv.
- Multitask Ready: Selain klasifikasi, ViT juga dapat digunakan untuk segmentasi (SETR), deteksi objek (DETR), dan lain-lain.
Referensi: Dosovitskiy et al., 2020 – “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”
Persiapan Dataset
Kita bisa memanfaatkan dataset dari Hugging Face Hub seperti beans, cats_vs_dogs, atau dataset lokal lainnya.

Langkah berikutnya adalah memetakan label, membagi dataset (train/test), dan menyiapkan fungsi transformasi gambar menggunakan torchvision.transforms.
Load Pretrained ViT dan Processor
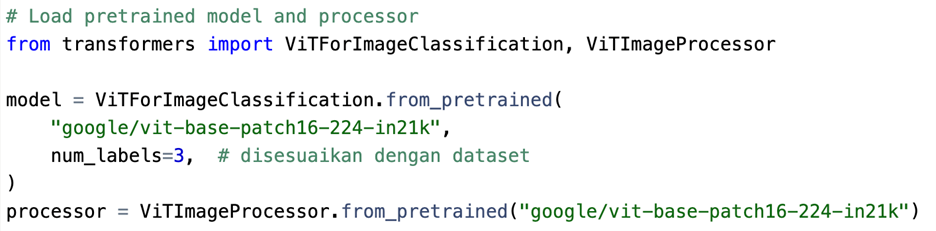
ViT menggunakan resolusi input 224×224 secara default. Processor akan memastikan gambar diubah ke format tensor dengan mean/std yang sesuai dengan model.
Transformasi dan Encoding Gambar

Fine-Tuning dengan Trainer
Gunakan Trainer dari Hugging Face untuk proses training yang simple.

Trainer secara otomatis menangani batching, loss computation, backpropagation, dan logging.
Evaluasi Model
Setelah training selesai, kita bisa melakukan evaluasi dengan metrik seperti akurasi dan F1-score. Kita dapat menggunakan library sklearn.metrics.

Export / Save Model
Model ViT dapat disimpan dalam format TorchScript atau ONNX untuk inferensi, deployment ke web, mobile, atau edge device.

Penutup
Fine-tuning Vision Transformer memberi alternatif cepat dan efisien untuk membangun sistem klasifikasi gambar berbasis arsitektur modern (Transformer). Dengan menggunakan pretrained model dari Hugging Face, kita bisa mencapai akurasi tinggi bahkan dengan data terbatas. ViT adalah contoh bagaimana arsitektur NLP dapat diadaptasi secara sukses ke area image (Computer Vision).
Referensi tambahan:
https://huggingface.co/docs/transformers/model_doc/vit
https://pytorch.org/vision/stable/models/generated/torchvision.models.vit_b_16.html
https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb
https://huggingface.co/blog/fine-tune-vit
Penulis
Muhammad Alfhi Saputra