
Adversarial Attack: Ketika AI Tertipu Gambar yang Disamarkan

Sumber: Midjourney
Saat ini, kita hidup di zaman ketika artificial intelligent (AI) sudah menjadi bagian dari banyak aspek kehidupan, seperti kamera ponsel yang mengenali wajah, mobil yang bisa mengemudi sendiri, dan sistem keamanan yang dapat mengenali intrusi. Akan tetapi, apa jadinya jika sistem AI yang sangat cerdas ini bisa ditipu hanya dengan sedikit perubahan yang nyaris tak terlihat pada gambar? Fenomena ini disebut Adversarial Attack, yaitu serangan terhadap model AI (terutama deep learning) dengan cara mengubah input sedikit saja, cukup untuk membuat model “bingung” dan mengambil keputusan yang salah, meskipun bagi manusia input itu masih tampak normal. Hal ini bukan sekadar eksperimen lab semata, tetapi potensi bahayanya sangat nyata, terutama pada sistem keamanan, pertahanan, dan transportasi.
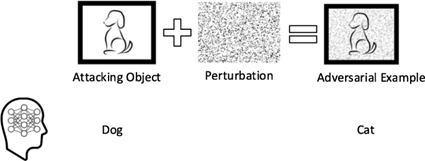
Source: Sun et al. (2018)
Adversarial attack terjadi ketika sebuah input, misalnya gambar dimanipulasi dengan gangguan kecil yang disengaja (perturbation) sehingga output model AI menjadi keliru. Gangguan ini sangat halus hingga tidak bisa dibedakan oleh mata manusia, tetapi sangat signifikan bagi model AI yang sangat sensitif terhadap perubahan numerik pada input-nya. Contoh paling terkenal adalah penelitian oleh Goodfellow et al. (2014), di mana gambar seekor panda diberi gangguan kecil menggunakan teknik Fast Gradient Sign Method (FGSM). Bagi manusia, gambar tersebut tetap terlihat seperti panda, tetapi bagi model deep neural network mengklasifikasikannya sebagai “gibbon” dengan tingkat keyakinan sangat tinggi. Lalu, bagaimana serangan ini dilakukan?
- Fast Gradient Sign Method (FGSM): Menggunakan turunan gradien dari loss terhadap input untuk menentukan arah perubahan terkecil yang membuat loss meningkat maksimal.
- Projected Gradient Descent (PGD): Versi iterative dari FGSM, dengan gangguan kecil yang diterapkan secara bertahap untuk menghindari batas maksimum.
- Carlini-Wagner (CW) Attack: Teknik lanjutan yang sangat kuat dan mampu menghindari banyak deteksi pertahanan.
- Universal Adversarial Perturbations: Perturbasi umum yang dapat menipu banyak gambar sekaligus, bukan hanya satu.
Adversarial attack bukanlah kebetulan. Ada beberapa alasan mengapa model deep learning bisa begitu mudah dikelabui. Berikut ini adalah beberapa faktor utama yang menjadi penyebabnya:
- Model deep learning bekerja pada domain numerik, bukan semantik. Sedikit perubahan nilai piksel bisa memindahkan input ke “wilayah keputusan” yang berbeda.
- Model cenderung belajar korelasi, bukan pemahaman. Misalnya, model mengasosiasikan tekstur atau noise tertentu dengan label tertentu.
- Model sangat kompleks dan high-dimensional, membuatnya rentan terhadap overfitting terhadap pola yang tidak manusiawi.
Meskipun terdengar seperti eksperimen akademis, serangan ini sudah terbukti punya dampak nyata di berbagai sistem yang kita gunakan. Beberapa contohnya adalah sebagai berikut:
- Keamanan kendaraan otonom: Peneliti menunjukkan bahwa menempelkan stiker tertentu pada rambu lalu lintas bisa membuat mobil self-driving salah membaca rambu sebagai batas kecepatan yang berbeda (Eykholt et al., 2018).
- Keamanan wajah: Sistem face recognition dapat ditipu hanya dengan memakai kacamata khusus atau pola pada topi, menyebabkan kesalahan identifikasi atau akses yang tidak sah.
- Deteksi malware: File berbahaya bisa dimodifikasi agar terlihat “aman” oleh sistem deteksi berbasis AI.
Untungnya, meskipun ancaman ini nyata, berbagai upaya telah dilakukan untuk menciptakan model yang lebih tahan terhadap serangan. Beberapa pendekatan yang telah dikembangkan meliputi:
- Adversarial Training: Melatih model dengan data yang telah diserang untuk membuatnya lebih tahan.
- Defensive Distillation: Mengurangi sensitivitas model terhadap perubahan kecil dengan mempelajari distribusi keluaran dari model yang sudah dilatih.
- Input Preprocessing: Menghapus atau menormalkan gangguan pada input sebelum diproses oleh model (misalnya dengan denoising).
- Certified Defenses: Teknik formal yang dapat menjamin batas keamanan terhadap perturbasi dalam ukuran tertentu.
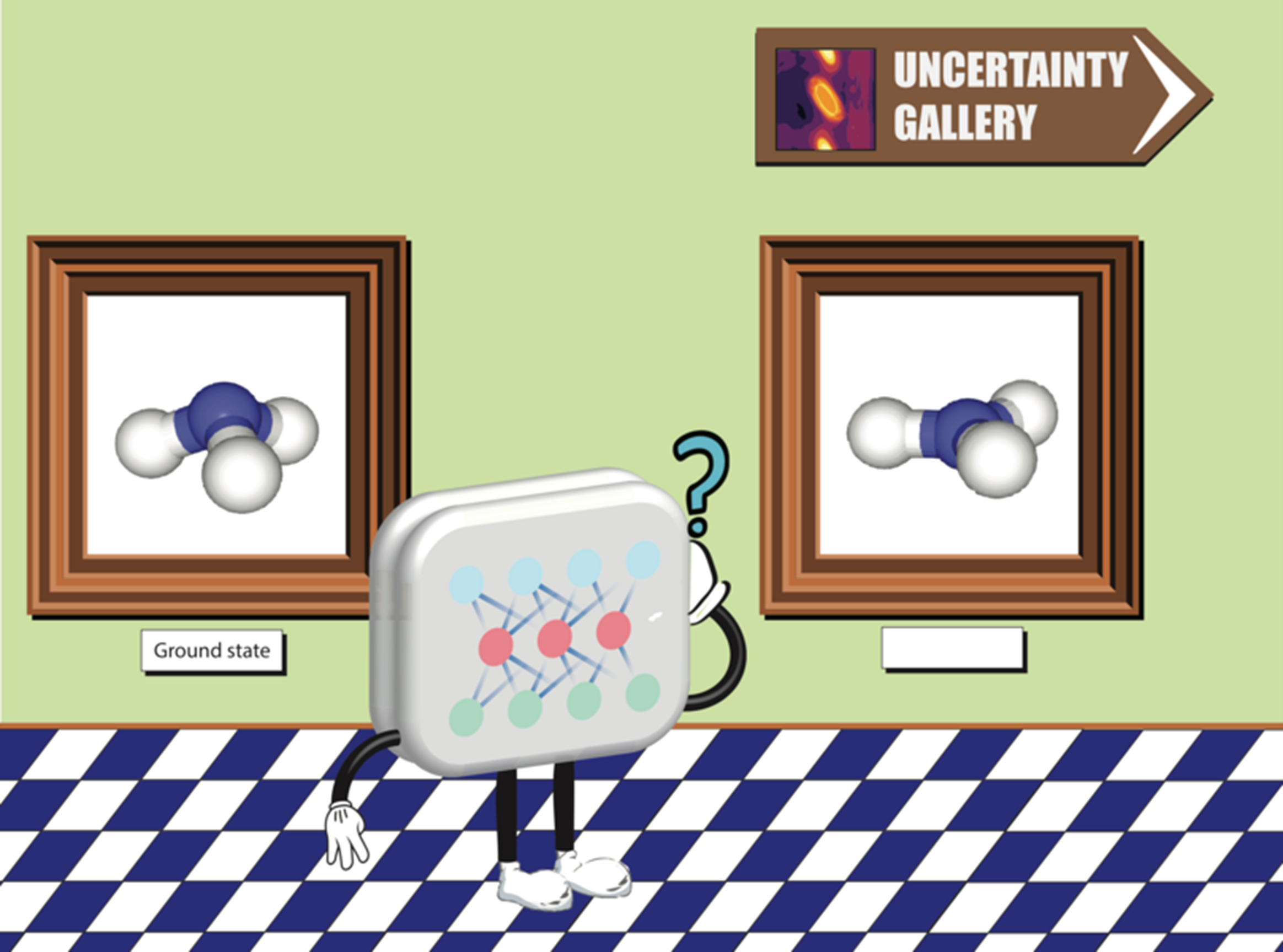
Source: news.mit.edu (2021).
Adversarial attack membuka mata kita bahwa AI, betapapun canggihnya, tetap memiliki keterbatasan. Fenomena ini menjadi pengingat bahwa AI bukanlah makhluk yang memahami dunia sebagaimana manusia memahaminya. Model AI sangat bergantung pada pola matematis yang ia pelajari dari data dan pola ini bisa dimanipulasi. Adversarial attack menunjukkan sisi rapuh dari sistem AI modern. Gambar yang terlihat normal bagi manusia bisa membuat model deep learning keliru total. Meskipun teknik pertahanan terus berkembang, tantangan dalam membangun sistem AI yang benar-benar robust dan aman masih sangat besar.
Penulis
Satriadi Putra Santika, S.Stat., M.Kom.
FDP Scholar
Daftar Pustaka
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv:1412.6572. https://arxiv.org/abs/1412.6572.
- Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., & Song, D. (2018). Robust Physical-World Attacks on Deep Learning Visual Classification. CVPR.
- Kurakin, A., Goodfellow, I., & Bengio, S. (2016). Adversarial Machine Learning at Scale. arXiv preprint arXiv:1611.01236. https://arxiv.org/abs/1611.01236.
- Papernot, N., McDaniel, P., & Goodfellow, I. (2016). Transferability in Machine Learning: From Phenomena to Black-Box Attacks Using Adversarial Samples. arXiv preprint arXiv:1605.07277.
- Sun, L., Tan, M. & Zhou, Z. (2018). A survey of practical adversarial example attacks. Cybersecur 1, 9. https://doi.org/10.1186/s42400-018-0012-9.
- Venugopal, V. (2021). Using adversarial attacks to refine molecular energy predictions. https://news.mit.edu/2021/using-adversarial-attacks-refine-molecular-energy-predictions-0901. Di akses 25 Mei 2025.