
LARGE LANGUANGE MODELS SUDAH KETINGGALAN ZAMAN? LARGE CONCEPT MODELS SIAP AMBIL ALIH

Source: AI Generated
Pendahuluan
Artificial Intelligence (AI) saat ini sangat bergantung pada Large Language Models (LLMs), yaitu model yang bekerja dengan memprediksi token satu demi satu (kata atau potongan kata). Meski mampu menghasilkan teks yang mengalir, LLMs memiliki keterbatasan terutama dalam hal penalaran konseptual dan keberlanjutan logis pada teks panjang. Kemudian, munculah sebuah pertanyaan “Bagaimana jika AI bisa berpikir dalam bentuk gagasan utuh, bukan sekadar kata-kata?” Large Concept Models (LCMs) hadir sebagai jawaban atas tantangan ini.
Apa itu Large Concept Models?
Large Concept Models (LCMs) adalah paradigma baru dalam pengembangan model bahasa yang dirancang untuk mengatasi keterbatasan mendasar dari Large Language Models (LLMs). Jika LLMs memproses input dan output dalam bentuk token (yakni kata atau potongan kata), maka LCMs beroperasi pada unit semantik yang lebih besar dan bermakna secara konseptual, yaitu konsep yang umumnya setara dengan satu kalimat atau ide utuh. Alih-alih memprediksi satu token demi satu secara berurutan, LCM bertugas untuk memprediksi konsep berikutnya dalam bentuk vektor embedding dalam ruang semantik tinggi. Pada konteks ini, “konsep” didefinisikan sebagai representasi kompresi dari satu atau beberapa kalimat yang membawa makna logis, relasional, dan dapat dianalisis secara semantik (Barrault et al., 2024).
Untuk merepresentasikan konsep-konsep tersebut, LCMs menggunakan SONAR, sebuah model encoder–decoder berbasis embedding multilingual dan multimodal. SONAR mendukung hingga 200+ bahasa dan mampu menangani tidak hanya teks tetapi juga modalitas lain seperti suara dan audio, menjadikan LCMs sebagai model agnostik bahasa dan modalitas (Barrault et al., 2024). Representasi konseptual ini membuat LCMs sangat kuat dalam memahami, mengorganisasi, dan memprediksi alur pemikiran manusia secara lebih abstrak.
Konsep Dasar Bagaimana Large Concept Models Bekerja
Secara umum, LCMs menggantikan pendekatan prediksi kata-demi-kata seperti pada LLMs, dengan prediksi berbasis ide atau konsep utuh. Untuk memahami perbedaannya, mari kita lihat ilustrasi yang dikemukakan oleh Gupta (2025).
Bayangkan Anda sedang menulis cerita. Dengan LLMs seperti ChatGPT, sistem akan memprediksi kata selanjutnya berdasarkan kata-kata sebelumnya. Misalnya, jika Anda mengetik: “The cat sat on the…” Maka model akan melengkapi dengan “mat.” Model ini bekerja seperti mengisi kalimat secara satu per satu kata, mirip dengan permainan tebak kata. Metode ini efektif untuk menghasilkan teks yang mengalir, tetapi terkadang gagal menangkap makna keseluruhan dari kalimat atau paragraf.
Sebaliknya, LCMs beroperasi pada level yang lebih tinggi, bukan memprediksi token, tetapi memprediksi ide atau konsep selanjutnya. Masih dalam konteks menulis cerita, jika Anda mengetik: “The cat sat on the mat. It was a sunny day. Suddenly…” Maka LCM akan memprediksi sesuatu seperti “a loud noise came from the kitchen.” Dalam hal ini, model tidak sekadar melengkapi kata, tetapi mencoba menebak gagasan penuh yang secara logis dan semantis melanjutkan narasi sebelumnya. LCM seperti merancang satu unit cerita sekaligus, bukan sekadar menyusun kata per kata. Ini memberi keunggulan dalam hal koherensi, penalaran, dan struktur ide, terutama dalam konteks generasi teks panjang atau argumentatif.
LCMs Vs LLMs
Untuk memahami keunggulan konseptual yang ditawarkan oleh LCMs, penting untuk membandingkannya secara langsung dengan LLMs. Berdasarkan Gupta (2025), perbedaan antara keduanya bukan hanya bersifat teknis, tetapi menyentuh dimensi mendasar dalam cara model memahami dan memproses informasi. Jika LLMs beroperasi pada level token, memprediksi kata demi kata berdasarkan urutan sebelumnya, maka LCM mengambil pendekatan yang lebih advanced dengan memprediksi konsep atau ide secara utuh. Hal ini berdampak pada berbagai aspek mulai dari cara input direpresentasikan, proses pelatihan, efisiensi reasoning, hingga kemampuan generalisasi lintas bahasa dan modalitas. Berikut adalah ringkasan perbedaan antara LCMs dan LLMs.
| Aspek | LLMs | LCMs |
| Level Abstraksi | Token (kata/subkata) | Konsep (kalimat/gagasan) |
| Representasi Input | Token dalam bahasa tertentu | Embedding kalimat yang agnostik terhadap bahasa & modalitas |
| Generasi Output | Kata demi kata, fokus pada koherensi lokal | Kalimat demi kalimat, fokus pada koherensi global dan penalaran |
| Dukungan Bahasa & Modalitas | Terbatas; biasanya satu modalitas (teks) | Multibahasa dan multimodal (teks, suara, gambar) dalam satu ruang konsep |
| Tujuan Pelatihan | Meminimalkan error prediksi token (cross-entropy) | Meminimalkan error prediksi konsep (MSE di ruang embedding) |
| Reasoning dan Perencanaan | Reasoning bersifat implisit dan lokal | Reasoning eksplisit pada level hierarki ide dan rencana |
| Kemampuan Zero-Shot | Lemah untuk bahasa/modalitas yang belum dilatih | Kuat untuk generalisasi lintas bahasa dan modalitas |
| Efisiensi Konteks Panjang | Tidak efisien karena kompleksitas attention kuadratik | Lebih efisien karena memproses urutan embedding kalimat yang lebih pendek |
| Aplikasi | Cocok untuk tugas berbasis kata seperti pelengkapan teks, terjemahan, dan tanya-jawab | Unggul untuk tugas berbasis kalimat seperti ringkasan, generasi cerita, dan reasoning multimodal |
| Fleksibilitas | Terbatas pada teks; butuh retraining untuk bahasa atau modalitas baru | Fleksibel tanpa retraining lintas bahasa dan modalitas karena berbasis konsep |
Fitur Kunci dari Large Concept Models
Pada artikel analisis teknis yang diterbitkan oleh Shrikhande (2025) di ADaSci, dijelaskan bahwa LCMs dirancang bukan hanya untuk menghasilkan teks, tetapi untuk merepresentasikan dan memproses konsep secara efisien, manusiawi, dan fleksibel. Dengan mengandalkan embedding semantik yang canggih seperti SONAR, LCM mengubah pendekatan pemrosesan bahasa alami menjadi lebih hierarkis dan terorganisir. Keunggulan ini tercermin dalam empat fitur utama yang membedakan LCM dari pendekatan model bahasa konvensional. Berikut adalah empat fitur kunci dari LCMs.
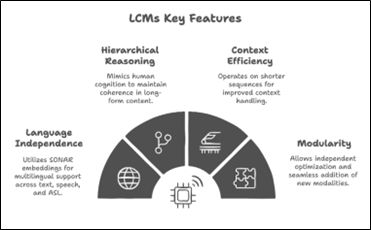
Source: Shrikhande (2025)
- Hierarchical Reasoning
LCMs dirancang untuk meniru cara berpikir manusia, di mana satu gagasan terhubung dengan gagasan lain secara logis dan terstruktur. Shrikhande (2025) menyebut bahwa LCMs dapat menjaga koherensi dalam teks panjang melalui struktur pemrosesan konsep berjenjang (hierarki). Hal ini membuat LCMs unggul dalam tugas-tugas seperti penalaran multistep, argumentasi, dan penceritaan naratif.
- Context Efficiency
Berbeda dengan LLMs yang sering mengalami degradasi performa pada konteks panjang, LCMs beroperasi dalam urutan yang lebih pendek karena ia bekerja pada level kalimat atau gagasan, bukan token. Hal ini tidak hanya membuatnya lebih efisien secara komputasi, tetapi juga lebih kuat dalam memahami konteks global dari sebuah dokumen.
- Language Independence
LCMs menggunakan embedding SONAR yang telah dilatih untuk mendukung lebih dari 200 bahasa serta berbagai modalitas seperti teks, suara, dan bahkan American Sign Language (ASL). Dengan demikian, LCMs bersifat agnostik terhadap bahasa dan tidak perlu diadaptasi ulang untuk digunakan dalam lingkungan multibahasa.
- Modularity
Desain arsitektur LCMs memungkinkan optimisasi modular, artinya setiap komponen seperti encoder, model inti, dan decoder dapat dikembangkan atau diganti secara independen. Hal ini mempermudah pengembangan jangka panjang serta memungkinkan integrasi modalitas baru secara seamless (misalnya penambahan input visual atau sinyal sensorik).
Arsitektur Large Concept Models
Untuk dapat memproses informasi secara semantik dan logis, LCMs dibangun dengan arsitektur yang sangat berbeda dari LLMs. Alih-alih beroperasi pada token dan bergantung penuh pada mekanisme self-attention untuk urutan kata, LCMs dirancang untuk bekerja pada level konsep atau ide yang direpresentasikan sebagai embedding kalimat atau gagasan. Arsitektur ini bukan hanya mencerminkan pergeseran dari “language modeling” ke “concept modeling,” tetapi juga memungkinkan reasoning multistep, pemrosesan multimodal, dan efisiensi kontekstual yang lebih tinggi. Berikut adalah tiga komponen utama yang menjadi tulang punggung LCM.
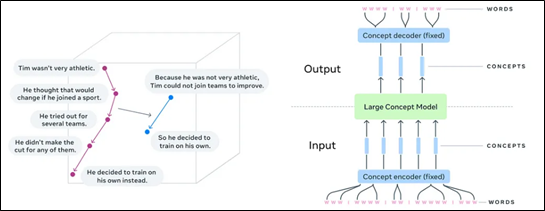
Source: Barrault et al. (2024)
- Concept Encoder
Komponen awal dari LCMs bertugas untuk mengubah input berupa teks menjadi representasi embedding konseptual menggunakan ruang embedding SONAR. Encoder ini bersifat “frozen” atau tidak dilatih ulang sehingga memberikan representasi yang stabil dan konsisten lintas bahasa dan modalitas (Shrikhande, 2025). Hal ini memungkinkan LCM untuk menerima input dari lebih dari 200 bahasa secara adil. Seperti ditunjukkan dalam ilustrasi Barrault et al. (2024), kata-kata terlebih dahulu diproses menjadi unit konsep yang lebih besar sebelum dimasukkan ke dalam model utama.
- LCMs Core (Reasoning and Prediction Engine)
Setelah input dikonversi menjadi konsep, inti LCMs yang berupa arsitektur transformer dengan modifikasi akan memproses urutan embedding tersebut untuk memprediksi konsep berikutnya. McKee (2025) menggambarkan bagian ini sebagai pusat reasoning dan planning dari LCMs. Dalam proses ini, model beroperasi secara autoregresif di ruang embedding, memungkinkan pengambilan keputusan logis berdasarkan ide sebelumnya, bukan sekadar token sebelumnya. Komponen ini juga dapat diperkaya dengan PreNet dan PostNet untuk meningkatkan kualitas input atau output embedding (Shrikhande, 2025).
- Concept Decoder
Output dari LCMs core adalah embedding konseptual baru yang belum dalam bentuk bahasa. Untuk menerjemahkannya ke dalam bentuk teks atau suara yang dapat dimengerti manusia, LCM menggunakan concept decoder yang mengubah kembali embedding menjadi kalimat atau pernyataan verbal (Barrault et al., 2024). Pada LCMs decoding dilakukan dalam unit ide sehingga proses ini jauh lebih efisien dibandingkan decoding token demi token seperti pada LLMs.
Selanjutnya, arsitektur LCMs juga dapat dimodifikasi ke dalam beberapa varian bergantung pada kebutuhan tugas. Berikut adalah beberapa varian dari LCMs.
- Base-LCMs
Versi standar yang menggunakan arsitektur transformer untuk memprediksi embedding konsep berikutnya, dioptimalkan dengan loss Mean Squared Error (MSE). Cocok untuk ringkasan dan reasoning secara umum.
- Diffusion LCMs
Memanfaatkan pendekatan berbasis diffusion untuk membentuk embedding secara bertahap dengan stabilitas lebih tinggi. Ideal untuk skenario generasi teks kreatif atau pembuatan narasi bertingkat.
- Quantized LCMS
Menggabungkan residual vector quantization untuk menghasilkan representasi diskrit dari embedding konsep, yang sangat efisien dan cocok untuk perangkat edge atau sistem dengan keterbatasan komputasi.
Pengaplikasian Large Concept Models
Dengan arsitektur berbasis konsep yang memungkinkan reasoning hierarkis, prediksi jangka panjang, serta dukungan multibahasa dan multimodal, LCMs sangat cocok diterapkan dalam berbagai skenario yang memerlukan pemahaman konteks global, struktur logis yang dalam, dan penarikan kesimpulan lintas ide. Tidak seperti LLMs yang lebih cocok untuk generasi teks cepat di level kata, LCMs unggul dalam tugas-tugas konseptual kompleks di dunia nyata. Berikut beberapa area utama di mana LCM telah mulai menunjukkan keunggulannya dibanding model LLMs.
- Summarization dan Summary Expansion
Salah satu aplikasi paling menonjol dari LCMs adalah dalam summarization dan summary expansion. LCMs dapat mengabstraksi poin-poin utama, menjaga alur logis, dan menghasilkan ringkasan yang tidak hanya koheren secara lokal, tetapi juga menyeluruh. Studi oleh Barrault et al. (2024) menunjukkan bahwa LCMs mampu menghasilkan ringkasan yang lebih presisi dan koheren dibandingkan LLMs dengan parameter setara. Bahkan, dalam eksperimen zero-shot, LCMs lebih stabil terhadap teks panjang dan domain khusus.
- Chatbot Enterprise dan Penalaran Eksplisit
Dalam implementasi chatbot berskala enterprise, kebutuhan akan reasoning eksplisit, penyesuaian gaya komunikasi, dan pemrosesan instruksi kompleks menjadi tantangan utama. LCMs menyediakan pendekatan baru karena mampu menyusun respons berbasis konsep, bukan hanya reaksi token. Bhatnagar (2024) dalam laporan teknisnya menyebutkan bahwa open-source LCMs dapat memetakan jalur reasoning secara transparan, memberikan potensi untuk auditabilitas dan kontrol output chatbot.
- Cyber Security dan Log Analysis
Dalam domain cyber security, log analysis membutuhkan kemampuan untuk menghubungkan kejadian yang tersebar dalam waktu dan konteks berbeda. LCMs dapat digunakan untuk membaca, merangkum, dan mengkorelasikan log sistem ke dalam alur sebab-akibat (causal reasoning), misalnya mendeteksi potensi ancaman yang tersembunyi dalam jejak aktivitas jaringan. LCMs unggul dalam menyusun ulang informasi menjadi kronologi naratif yang mudah dianalisis oleh tim Security Operation Center (SOC).
Tantangan dalam Large Concept Models
Meskipun LCMs menghadirkan pendekatan baru yang menjanjikan dalam Natural Language Processing (NLP) dan reasoning konseptual, teknologi ini juga menyimpan tantangan yang signifikan. Menurut McKee (2025) melalui DataCamp, beberapa keterbatasan teknis dan struktural masih menjadi hambatan utama dalam pengembangan dan implementasi LCM secara luas. Berikut adalah beberapa tantangan paling krusial yang perlu dipahami.
- Kebutuhan Data dan Sumber Daya yang Lebih Tinggi
Berbeda dengan LLMs yang langsung melatih model dari korpus teks mentah, LCMs membutuhkan preprocessing tambahan berupa segmentasi kalimat dan konversi ke dalam embedding konseptual. Proses ini menuntut kapasitas penyimpanan yang besar serta pipeline ekstraksi data yang kompleks. Pelatihan LCMs juga dilakukan di level kalimat, bukan token sehingga diperlukan ratusan miliar kalimat untuk mencapai generalisasi yang baik. Akibatnya, LCMs menuntut daya komputasi dan infrastruktur yang jauh lebih besar dibandingkan LLMs.
- Kompleksitas Debugging dan Interpretabilitas
LCM bekerja dalam ruang embedding berdimensi tinggi, di mana setiap konsep tidak dapat dipecah menjadi token-token sederhana. Hal ini membuat analisis kesalahan (error tracing) menjadi lebih sulit. Jika pada LLMs kita bisa mengidentifikasi kesalahan pada kata atau frasa tertentu, dalam LCMs kesalahan terjadi pada representasi konsep penuh yang lebih abstrak dan kurang intuitif untuk ditelusuri. Model ini unggul dalam menjaga koherensi makro, tetapi kurang transparan saat dievaluasi secara mikroskopik.
- Biaya Komputasi yang Tinggi
Meskipun efisien dalam memahami konteks panjang, beberapa varian LCMs, terutama LCMs berbasis diffusion membutuhkan lebih banyak langkah untuk menghasilkan output. Proses iteratif ini menjadikan generasi teks lebih lambat dan mahal secara komputasi. Jika dibandingkan dengan LLMs yang hanya membutuhkan satu pass untuk menghasilkan token, LCMs harus menyempurnakan representasi embedding melalui banyak tahapan. Hal ini menjadi kurang efisien untuk tugas sederhana seperti respons cepat dalam chatbot atau pencarian cepat.
- Keterbatasan Struktural dan Representasi Konsep
Bekerja pada level kalimat berarti LCMs harus mengemas seluruh gagasan ke dalam satu unit embedding. Hal ini menimbulkan masalah apabila sebuah kalimat terlalu panjang (mengandung lebih dari satu ide pokok) atau terlalu pendek (tidak cukup informasi untuk membentuk representasi semantik yang bermakna). Selain itu, kalimat dalam bahasa alami jauh lebih bervariasi daripada token sehingga LCMs menghadapi masalah sparsitas data karena tidak ada cukup pengulangan struktur konseptual seperti halnya kata dalam LLMs.
Teknologi LCMs masih dalam tahap eksplorasi dan pengembangan aktif. Sebagai ekosistem open source, banyak tantangan ini kini sedang diatasi oleh komunitas riset dan industri. McKee (2025) mencatat bahwa kolaborasi terbuka dalam desain encoder, strategi optimasi, dan efisiensi model menjadi kunci untuk membawa LCM ke tingkat produksi dan penerapan yang lebih luas.
Kesimpulan
Large Concept Models (LCMs) mewakili lompatan paradigma dalam pengembangan AI, dari pendekatan berbasis token menuju pemahaman konsep yang lebih holistik dan semantik. Dengan memproses informasi dalam bentuk representasi ide atau kalimat, LCMs menghadirkan pendekatan yang lebih mirip cara manusia berpikir, yakni berbasis makna, konteks, dan logika antar ide. Keunggulan seperti reasoning hierarkis, efisiensi konteks panjang, serta kemampuan generalisasi lintas bahasa dan modalitas menjadikan LCM sangat menjanjikan untuk tugas-tugas yang memerlukan presisi kognitif tinggi, seperti penalaran hukum, diagnosis medis, peringkasan ilmiah, hingga smart assistant dalam NLP yang lebih dapat dipercaya.
Namun demikian, LCMs masih dihadapkan pada berbagai tantangan fundamental, mulai dari kebutuhan komputasi besar, kompleksitas debugging, hingga representasi konsep yang tidak selalu seragam. Tantangan ini wajar mengingat pendekatan yang diusung LCMs bersifat transformatif dan menyentuh akar arsitektur pemrosesan AI modern. Meski demikian, dengan dukungan riset terbuka, peningkatan encoder semantik seperti SONAR dan eksplorasi arsitektur modular yang fleksibel, LCM memiliki potensi kuat menjadi fondasi menuju artificial general intelligence (AGI) yang lebih rasional, inklusif, dan dapat dipertanggungjawabkan. Perubahan ini bukan hanya bersifat teknis, tetapi juga filosofis menggeser fokus AI dari “prediksi kata” ke “pemahaman ide”.
Penulis
Satriadi Putra Santika, S.Stat., M.Kom – FDP Scholar
Daftar Pustaka
Barrault, L., Duquenne, P.-A., Elbayad, M., Kozhevnikov, A., Alastruey, B., Andrews, P., Coria, M., Couairon, G., Costa-jussà, M. R., Dale, D., Elsahar, H., Heffernan, K., Janeiro, J. M., Tran, T., Ropers, C., Sánchez, E., San Roman, R., Mourachko, A., Saleem, S., & Schwenk, H. (2024). Large Concept Models: Language Modeling in a Sentence Representation Space. arXiv. https://arxiv.org/abs/2412.08821.
Bhatnagar, A. (2024). Large Concept Models: a Paradigm Shift in AI Reasoning. Info Q. https://www.infoq.com/articles/lcm-paradigm-shift-ai-reasoning/#:~:text=Key%20Takeaways,effectively%20than%20traditional%20AI%20approaches. Di akses 1 Juli 2025.
Gupta, M. (2025). Meta Large Concept Models (LCM): End of LLMs?. Medium. https://medium.com/data-science-in-your-pocket/meta-large-concept-models-lcm-end-of-llms-68cb0c5cd5cf. Di akses 1 Juli 2025.
McKee, A. (2025). What Are Large Concept Models (LCMs)? DataCamp. https://www.datacamp.com/blog/large-concept-models. Di akses 1 Juli 2025.
Shrikhande, V. (2025). A Deep Dive into Large Concept Models (LCMs). ADaSci. https://adasci.org/a-deep-dive-into-large-concept-models-lcms/. Di akses 1 Juli 2025.