
Mixture of Recursions: How it Beats Transformer

Transformer telah menjadi tulang punggung kemajuan pesat dalam Large Language Models (LLMs) seperti GPT, Gemini, hingga Claude. Arsitektur ini dikenal karena kemampuannya mengelola dependensi jangka panjang dalam teks melalui mekanisme self-attention yang efisien dan paralel. Namun, di balik keberhasilannya terdapat keterbatasan fundamental yang semakin mencolok seiring skala model bertambah besar, yaitu konsumsi sumber daya yang berlebihan. Pada praktiknya, Transformer memproses setiap token dalam input dengan jumlah komputasi yang identik, terlepas dari kompleksitas token tersebut. Baik token sederhana seperti “dan” maupun token kompleks seperti “diplomatically,” seluruhnya melewati pipeline lapisan yang sama dengan intensitas pemrosesan yang seragam. Keseragaman ini, meskipun elegan dari sisi desain, menghasilkan pemborosan compute yang signifikan. Ketika skala model terus tumbuh untuk mengejar akurasi yang lebih tinggi, beban memori, latency inference, dan biaya energi menjadi semakin sulit untuk diabaikan.
Oleh karena itu, muncul sebuah pertanyaan, “apakah mungkin sebuah model belajar untuk menyesuaikan kedalaman berpikirnya secara dinamis dengan hanya mengalokasikan sumber daya sesuai kebutuhan kompleksitas token?”. Pertanyaan inilah yang menjadi landasan lahirnya Mixture of Recursions (MoR), sebuah pendekatan baru dari KAIST dan Google DeepMind (Bae et al., 2025). MoR memperkenalkan arsitektur yang menggabungkan dua paradigma penting, yaitu parameter sharing dan adaptive token-level computation ke dalam satu sistem terpadu yang efisien. Alih-alih memperlakukan semua token secara setara, MoR memungkinkan setiap token untuk “memutuskan” sendiri seberapa dalam ia perlu diproses. Token yang sederhana dapat keluar lebih awal, sementara token yang lebih kompleks diberi kesempatan untuk diproses lebih dalam melalui mekanisme recursive computation. Dengan MoR, kita tidak hanya berbicara tentang efisiensi model, tetapi juga tentang pergeseran paradigma dari arsitektur yang seragam dan boros menjadi sistem yang adaptif, cerdas, dan hemat secara struktural.
Mixture of Recursions
Mixture of Recursions (MoR) dibangun di atas gagasan yang sederhana namun revolusioner, yaitu tidak semua token membutuhkan kedalaman pemrosesan yang sama. Pada arsitektur ini, setiap token diperlakukan sebagai entitas yang dapat menilai “berapa banyak berpikir” yang ia perlukan, token sederhana cukup melewati satu atau dua tahap pemrosesan, sedangkan token kompleks diberi kesempatan untuk masuk lebih dalam ke dalam loop. Secara teknis, MoR menggunakan satu blok layer Transformer yang diulang secara rekursif, bukan menumpuk layer berbeda seperti pada arsitektur konvensional. Komponen kunci yang memungkinkan fleksibilitas ini adalah router, modul ringan yang menentukan apakah token akan melanjutkan ke recursion berikutnya atau “keluar” dari proses lebih awal. Berbeda dari mekanisme early exit klasik yang pasif dan statis, router di MoR bersifat dinamis dan dilatih secara end-to-end bersama model utama.
“Mixture-of-Recursions is like a smart helper that looks at each Lego piece and says: “Hmm, this one’s easy, let’s do it once.” Or “This one’s tricky, let’s work on it a few more times.” – Gupta (2025) via Medium
Secara kognitif, pendekatan ini mencerminkan bagaimana manusia membaca, kita tidak merenungkan setiap kata secara merata. Kata hubung seperti “yang” atau “dan” diproses cepat dan langsung dilewati, sementara kata-kata kompleks atau ambigu seperti “defensively confident” bisa memicu pemrosesan lanjutan untuk memahami makna dan konteksnya. MoR meniru pola ini, namun dalam bentuk mekanisme komputasi yang efisien dan diferensial.
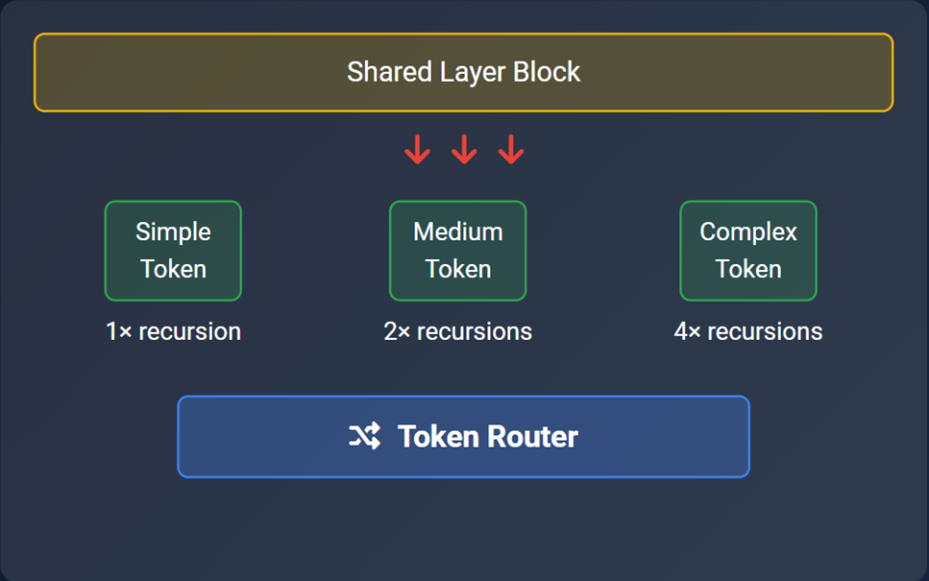
Source: Gupta (2025) via Medium
Recursive Transformer Sebuah Pondasi yang Telah Disiapkan
Sebelum lahirnya MoR, upaya untuk mengintegrasikan pemrosesan rekursif dalam arsitektur Transformer telah lebih dulu dieksplorasi oleh tim peneliti dari Stanford melalui konsep Forced Recursive Transformer (FRT) (Chen et al., 2023). Pada studi tersebut, mereka mengkaji bagaimana Transformer dapat memecahkan persoalan aritmatika kompleks dengan mendekatinya secara bertahap, layaknya proses berpikir manusia yang memecah persoalan besar menjadi langkah-langkah kecil. FRT memperlakukan proses berpikir sebagai serangkaian “thinking steps” rekursif, di mana output dari satu langkah dijadikan input untuk langkah selanjutnya. Dengan menggunakan satu blok Transformer yang sama secara berulang, model ini menunjukkan bahwa pendekatan berbasis recursion dapat meningkatkan kemampuan generalisasi. Bahkan, meskipun hanya dilatih pada ekspresi matematika dengan panjang tertentu, model FRT berhasil melakukan extrapolation, yaitu menyelesaikan ekspresi yang jauh lebih kompleks dari yang pernah ia lihat saat pelatihan. Hal ini dicapai dengan parameter yang tetap, karena layer yang sama digunakan berulang sehingga efisien dari segi ukuran model.

Source: Gupta (2025) via Medium
Namun, keterbatasan mendasar pada arsitektur ini adalah sifatnya yang rigid, yaitu semua input diproses dengan jumlah recursion yang tetap. Baik soal yang sederhana maupun yang rumit, seluruhnya dipaksa melalui jumlah langkah pemrosesan yang sama. Tidak ada mekanisme bagi model untuk menyesuaikan kedalaman pemrosesan berdasarkan tingkat kesulitan token atau ekspresi. Di sinilah MoR melakukan lompatan penting. Ia mempertanyakan asumsi bahwa kedalaman pemrosesan harus seragam dan menggantinya dengan prinsip komputasi adaptif per token. Dengan memasukkan komponen router yang menentukan secara dinamis berapa kali token harus diproses, MoR membawa fleksibilitas baru yang tidak dimiliki FRT, token sederhana bisa keluar lebih awal, sementara token rumit dapat diberi waktu berpikir lebih panjang. Hal ini bukan sekadar efisiensi, ini adalah fondasi dari pemrosesan yang lebih cerdas dan hemat.
Router dan Caching: Cara Mixture of Recursions Bekerja
MoR memadukan dua gagasan kunci yang sebelumnya berjalan terpisah dalam pengembangan arsitektur efisien, yaitu parameter sharing melalui recursion dan adaptive computation per token. Integrasi ini menghasilkan sebuah sistem di mana setiap token tidak hanya melewati layer yang sama berulang, tetapi juga memiliki fleksibilitas untuk memutuskan kapan berhenti diproses. Mekanismenya dapat dijelaskan melalui tiga komponen utama:
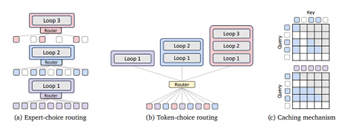
Source: Bae et al. (2025)
1. Routing
Routing merupakan mekanisme inti yang memungkinkan model memproses token secara adaptif. Dalam arsitektur MoR, terdapat dua pendekatan utama yang dikembangkan:
• Expert-choice routing: Pada setiap recursion step, router memilih subset token (top-k) yang masih perlu dilanjutkan ke recursion berikutnya, sedangkan token lain dianggap selesai. Strategi ini memberi fleksibilitas per-token secara bertahap. Untuk menghindari informasi dari masa depan selama training autoregressive, MoR menambahkan auxiliary loss pada routing layer (Bae et al., 2025).
• Token-choice routing: Di sini, jumlah recursion untuk setiap token ditentukan sekali di awal, membuat inference sangat cepat karena tidak perlu evaluasi ulang. Namun, router harus cukup presisi sejak awal untuk memprediksi kebutuhan compute tiap token (Bae et al., 2025).
2. Recursive Looping
Alih-alih menyusun banyak layer unik seperti pada Transformer biasa, MoR menggunakan satu blok encoder-decoder yang di-reuse secara rekursif. Pendekatan ini mirip dengan Universal Transformer atau Recurrent Transformer, tetapi berbeda karena tidak memaksa semua token menempuh jumlah loop yang sama. Menurut Bae et al. (2025), skema Middle cycle sharing, di mana bagian tengah blok Transformer dibagi antar recursion, memberikan efisiensi parameter terbaik tanpa menurunkan akurasi.
3. KV Caching
Salah satu inovasi penting MoR adalah caching yang berbasis aktivitas token. Saat decoding, hanya token yang masih dalam proses recursion yang menyimpan Key-Value (KV) pairs. Token yang sudah keluar tidak lagi menyimpan state apapun sehingga mengurangi footprint memori secara signifikan (Bae et al., 2025). Lebih lanjut, mereka mengusulkan KV sharing, di mana recursion tahap lanjut dapat menggunakan kembali cache dari recursion pertama. Hal ini terbukti menurunkan latency prefill saat inference tanpa degradasi akurasi yang signifikan (Bae et al., 2025).
Mixture of Recursions Bicara Data bukan Hanya Sekedar Hype Semata
MoR bukan sekadar ide bagus atau eksperimen akademik, ia adalah proposal yang telah dikuatkan oleh hasil empiris yang meyakinkan. Pada pengujian komprehensif pada berbagai benchmark dan skenario inference, arsitektur ini menunjukkan peningkatan efisiensi dan performa yang nyata dibanding Transformer konvensional. Salah satu pencapaian paling menonjol adalah pada aspek throughput inference, di mana MoR mencapai peningkatan hingga 2× lebih cepat dibanding Transformer biasa pada ukuran parameter dan batch yang setara (Dickson, 2025). Hal ini dimungkinkan berkat dua inovasi utama: (1) token-level early exit, yang memungkinkan token tidak relevan keluar lebih cepat dari pipeline komputasi; dan (2) depth-wise batching, yaitu pengelompokan token berdasarkan recursion step sehingga eksekusi paralel di GPU menjadi lebih optimal (Bae et al., 2025).
Dari segi efisiensi ukuran model, MoR juga jauh lebih ringan. Pada eksperimen skala kecil, model MoR-118M berhasil menyamai, bahkan mengungguli performa Transformer-315M dalam beberapa task zero-shot dan few-shot seperti LAMBADA, HellaSwag, dan PIQA (Bae et al., 2025). Hal ini menunjukkan bahwa dengan hanya sepertiga parameter, MoR mampu mempertahankan, bahkan meningkatkan kualitas representasi. Lebih lanjut, proses pelatihan pun menjadi lebih hemat. Dalam konfigurasi yang dilaporkan, MoR mengurangi waktu training sebesar 19%, serta menurunkan penggunaan peak memory hingga 25% dibanding model baseline Transformer. Efisiensi ini berasal dari dua komponen, parameter sharing via recursion, yang mengurangi footprint model secara keseluruhan dan selective KV caching, yang hanya menyimpan pasangan key-value untuk token aktif, berlawanan dengan caching statis untuk semua token di semua layer seperti pada vanilla Transformer (Bae et al., 2025).
Tidak hanya unggul secara komputasi, performa MoR juga kompetitif. Pada benchmark seperti LAMBADA. MoR mengungguli vanilla Transformer dengan skor 70,6 vs 68,4, meskipun hanya menggunakan 70% dari parameter model tersebut. Di PIQA dan HellaSwag, dua benchmark yang menuntut kemampuan inferensi kausal dan pemahaman dunia nyata, MoR juga secara konsisten unggul tipis, membuktikan bahwa efisiensi tidak perlu mengorbankan akurasi. Dengan capaian-capaian ini, MoR bukan hanya “Transformer yang lebih hemat,” melainkan arsitektur yang menawarkan jalan baru dalam desain model efisien, yang secara adaptif menyesuaikan komputasi dengan kebutuhan real-time di level token.
Mixture of Recursions dan Masa Depan Transformer
Apakah MoR akan menggantikan Transformer? Belum tentu. Akan tetapi, MoR adalah kandidat kuat untuk menggantikan mereka dalam banyak aplikasi real-time atau edge deployment. Tidak hanya lebih hemat parameter, MoR juga membuka arah desain baru, model yang adaptif terhadap beban kerja token. Untuk memahami posisi MoR dibanding dua pendekatan populer lainnya, Vanilla Transformer dan Mixture of Experts (MoE). Berikut ini adalah ringkasan arsitekturalnya.

Source: Gupta (2025) via Medium
Tantangan yang Harus Dihadapi Mixture of Recursions
Meskipun MoR menawarkan terobosan signifikan dalam efisiensi dan fleksibilitas arsitektur Transformer, inovasi ini masih menyisakan sejumlah tantangan teknis yang perlu diperhatikan, terutama jika ingin diadopsi secara luas di sistem skala industri. Beberapa permasalahan muncul dari kompleksitas arsitektur itu sendiri, seperti kestabilan proses routing, kesulitan paralelisasi saat inference, dan trade-off antara akurasi dan efisiensi memori. Selain itu, meskipun hasil eksperimen awal sangat menjanjikan, performa MoR pada skala besar seperti model 10B+ parameter masih menjadi tanda tanya terbuka.
• Stabilitas Routing
Pada pendekatan token-choice routing, distribusi token per recursion depth dapat menjadi tidak seimbang, menyebabkan load imbalance yang berdampak pada efisiensi training dan inference. Untuk mengatasi ini, MoR menggunakan strategi bias-based routing guna mengarahkan token ke depth yang lebih merata.
• Information Leakage
Pada expert-choice routing, router dapat mengevaluasi semua token secara global. Tanpa mitigasi, ini berpotensi menyebabkan leakage informasi dari masa depan selama pelatihan autoregressive. MoR mengatasi ini dengan auxiliary routing loss untuk mencegah penggunaan informasi yang tidak seharusnya.
• Kesulitan Parallelism saat Inference
Batching menjadi rumit karena token bisa berada di recursion depth yang berbeda. Hal ini diatasi dengan depth-wise batching, yaitu pengelompokan token per recursion level, tetapi tetap menambah overhead implementasi dibanding Transformer biasa.
• Trade-Off dalam KV Sharing
Meskipun KV reuse menghemat memori, pada konfigurasi tertentu hal ini menurunkan akurasi, terutama di routing berbasis token yang sensitif terhadap konteks awal.
• Skalabilitas Terbatas
Saat ini, MoR baru diuji pada model hingga 1.7B parameter. Belum ada bukti bahwa arsitektur ini dapat mempertahankan efisiensi dan stabilitas ketika digunakan dalam skala LLM besar seperti GPT-3 (175B+) atau lebih.
Kesimpulan
Sebagai pendekatan yang menggabungkan parameter sharing dan komputasi adaptif, Mixture of Recursions (MoR) menawarkan arah baru dalam evolusi arsitektur Transformer, model yang tidak hanya efisien secara struktural, tetapi juga cerdas dalam mengalokasikan daya komputasi per token. Dengan bukti peningkatan throughput, pengurangan memori, dan performa yang kompetitif meski berukuran lebih kecil, MoR menunjukkan bahwa efisiensi dan performa tidak lagi harus menjadi trade-off. Meskipun tantangan seperti stabilitas routing dan skalabilitas pada model besar masih perlu diatasi, MoR telah membuka jalan bagi era baru arsitektur yang lebih adaptif, hemat, dan logis, di mana model belajar bukan hanya apa yang harus diproses, tetapi juga kapan harus berhenti memproses.
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Bae, S., Kim, Y., Bayat, R., Kim, S., Ha, J., Schuster, T., Fisch, A., Harutyunyan, H., Ji, Z., Courville, A., Yun, S. (2025). Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation. arXiv:2507.10524.
Chen, J., Lee, I., & Deshpande, R. (2023). Recursive Transformer: A Novel Neural Architecture for Generalizable Mathematical Reasoning. Stanford.
Dickson, B. (2025). Mixture-of-recursions delivers 2x faster inference—Here’s how to implement it. VentureBeat. https://venturebeat.com/ai/mixture-of-recursions-delivers-2x-faster-inference-heres-how-to-implement-it/. Di akses 8 Agustus 2025.
Gummadi, S. D. (2025). Mixture of Recursions: DeepMind’s Breakthrough in Efficient AI. Medium. https://medium.com/@gsaidheeraj/mixture-of-recursions-deepminds-breakthrough-in-efficient-ai-9da4bc494986. Di akses 8 Agustus 2025.
Gupta, M. (2025). Google’s Mixture Of Recursions: End of Transformers. Medium. https://medium.com/data-science-in-your-pocket/googles-mixture-of-recursions-end-of-transformers-b8de0fe9c83b. Di akses 8 Agustus 2025.