
Retrieval-augmented Generation Sebagai Solusi untuk Masalah Halusinasi dalam AI Generatif
Sumber: Writer’s Edit
AI Yang Tahu Segalanya
Large Language Models (LLMs) seperti GPT, Claude, atau Gemini telah mengubah cara kita berinteraksi dengan teknologi. Mereka tampak seperti “tahu segalanya”, dapat menjawab pertanyaan, merangkum artikel, menulis kode, bahkan membuat sebuah puisi. Akan tetapi, di balik kecanggihan ini, ada satu persoalan mendasar yang belum sepenuhnya terpecahkan, yaitu model AI tidak benar-benar mengerti atau mengetahui sebuah kebenaran.
LLMs bekerja dengan memprediksi token berikutnya berdasarkan pola dari data pelatihan yang sangat besar. Mereka tidak memiliki akses ke internet secara langsung, tidak tahu peristiwa yang terjadi setelah data pelatihan dikumpulkan, dan tidak bisa memperbarui pengetahuan kecuali melalui pelatihan ulang. Hal ini menciptakan ilusi bahwa AI mengetahui semuanya, padahal yang terjadi adalah prediksi statistik yang canggih (Gao et al., 2024).
Masalah ini menjadi semakin nyata ketika pengguna mulai mengandalkan AI untuk menjawab pertanyaan-pertanyaan faktual, legal, teknis, atau bahkan medis. Pada konteks inilah muncul istilah “hallucination“, yaitu ketika AI menyampaikan informasi yang tidak akurat dengan penuh keyakinan.
Mengarang Dengan Percaya Diri (Hallucinations)
“Hallucination” dalam konteks AI generatif merujuk pada fenomena ketika model menghasilkan output yang terdengar benar, tapi sebenarnya salah, tidak relevan, atau sepenuhnya fiktif. Masalah ini bukan sekadar salah ketik atau noise, melainkan hasil dari ketidakmampuan model untuk mengetahui apakah suatu informasi benar atau salah (Amugongo et al., 2024).
Contohnya sederhananya, seperti menanyakan kepada model siapa presiden Indonesia saat ini. Jika model dilatih sebelum 2024, ia mungkin akan menyebut nama yang sudah tidak menjabat. Namun, ia akan melakukannya dengan gaya bahasa yang percaya diri, seolah informasi itu valid. Hal inilah mengapa hallucination dianggap berbahaya, terutama jika digunakan dalam aplikasi seperti chatbot hukum, sistem diagnosa medis, atau penasehat keuangan. Menurut GeeksforGeeks (2025), hallucination terjadi karena model tidak memiliki mekanisme internal untuk melakukan verifikasi fakta secara eksplisit. Mereka hanya “mengira” berdasarkan pola, bukan memastikan berdasarkan sumber.
Retrieval-Augmented Generation Sebagai Solusi
Retrieval-Augmented Generation (RAG) muncul sebagai pendekatan arsitektural untuk mengatasi keterbatasan ini. Alih-alih mengandalkan semua jawaban dari parameter internal model, RAG menggabungkan kemampuan generatif dengan retrieval informasi eksternal yang dapat diakses saat proses inference berlangsung. RAG memungkinkan model untuk mencari data atau referensi dari sumber yang lebih dinamis, seperti dokumen internal, artikel terkini, atau basis data enterprise, dan menggunakannya secara langsung untuk membentuk jawaban. Hal inilah yang membedakannya dari model bahasa konvensional yang hanya mengandalkan pengetahuan statis hasil training.
Source: Geeks for Geeks (2025)
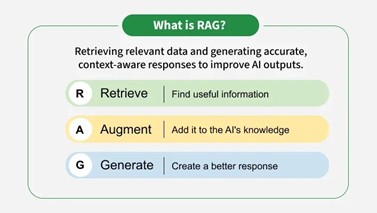
Secara prinsip, pendekatan RAG terdiri dari tiga komponen utama
Retrieve
Tahap ini melibatkan pencarian informasi yang relevan dari knowledge base eksternal. Sistem retrieval, yang biasanya menggunakan semantic search berbasis embedding, akan mencari potongan teks atau dokumen yang paling cocok dengan pertanyaan pengguna. Informasi ini bisa diambil dari berbagai sumber seperti Wikipedia, dokumentasi produk, atau basis data internal perusahaan (AWS, 2025).
Augment
Informasi yang berhasil ditemukan lalu diintegrasikan ke dalam prompt model. Proses ini menambahkan konteks faktual langsung ke dalam input LLMs. Dengan begitu, model tidak hanya menebak dari memorinya, tetapi bisa merespon dengan mempertimbangkan fakta yang tepat.
Generate
Setelah prompt diperkuat dengan informasi dari retriever, LLMs menghasilkan jawaban akhir yang lebih akurat, relevan, dan dapat ditelusuri sumbernya. Proses ini disebut juga sebagai context-aware generation, di mana hasil output secara langsung dipengaruhi oleh dokumen aktual yang disisipkan.
Dengan kata lain, RAG membuat AI “berpikir dengan bantuan catatan”. Sebelum menjawab, ia mencari referensi terlebih dahulu, mirip dengan bagaimana manusia membuka buku atau Googling sebelum memberi penjelasan. Pendekatan ini tidak hanya memperkaya konteks, tetapi juga membuat proses berpikir AI menjadi lebih transparan dan mudah diaudit. AWS (2025) menyebut metode ini sebagai salah satu cara paling efektif untuk meningkatkan akurasi sistem berbasis LLMs sekaligus mengurangi risiko hallucination yang merugikan pengguna.
Cara Retrieval-Augmented Generation Bekerja
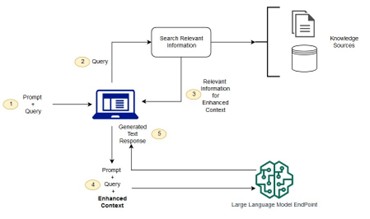
Untuk memahami lebih dalam tentang cara kerja RAG, mari kita lihat alur proses lengkapnya berdasarkan diagram berikut:
Source: AWS (2025)
Langkah-langkah utama yang terjadi dalam sistem RAG adalah sebagai berikut:
- Prompt dan Query Masuk: Proses dimulai saat pengguna mengirimkan pertanyaan atau permintaan ke sistem. Hal ini disebut sebagai query, yang dapat disertai konteks tambahan dalam bentuk prompt.
- Query Dikirim ke Retriever: Sistem kemudian mengubah query menjadi representasi vektor (embedding) dan mencocokkannya dengan dokumen atau potongan informasi dalam knowledge sources, seperti database atau dokumen internal perusahaan (Koval, 2025).
- Pencarian dan Seleksi Informasi: Retriever mengeksekusi pencarian semantik untuk menemukan dokumen paling relevan. Potongan-potongan hasil pencarian ini (biasanya top-k) disiapkan untuk dijadikan konteks tambahan.
- Konteks Diperkuat dan Digabungkan: Hasil retrieval digabungkan dengan query awal, membentuk enhanced prompt atau enhanced context. Hal ini adalah kombinasi antara pertanyaan pengguna dan informasi faktual yang ditemukan dari sumber luar.
- Generasi Jawaban oleh LLMs: Prompt yang telah diperkuat ini dikirim ke LLMs untuk diproses dan menghasilkan respons akhir. Risiko hallucination dapat ditekan secara signifikan karena jawaban disusun dengan mengacu pada dokumen aktual (Gao et al., 2024).
Diagram alur ini menekankan pentingnya dua komponen utama: retriever dan generator yang bekerja secara sinergis. Sistem ini memberikan fleksibilitas tinggi karena isi knowledge base bisa diperbarui kapan saja tanpa harus melatih ulang model besar. Oleh karena itu, RAG banyak diadopsi dalam use case yang menuntut factuality, traceability, dan modularitas.
Kenapa Retrieval-Augmented Generation Penting?
RAG menjadi krusial dalam ekosistem AI modern karena ia memberikan solusi yang efisien, fleksibel, dan dapat diandalkan untuk berbagai kebutuhan yang tidak bisa diselesaikan dengan model generatif murni. Salah satu alasan utamanya adalah kemampuannya untuk mengurangi hallucination dengan menyediakan jalur bagi model untuk merujuk kembali ke sumber informasi nyata, bukan hanya mengandalkan memorinya sendiri (Amugongo et al., 2024). Selain itu, RAG memungkinkan penggunaan informasi yang selalu diperbarui tanpa harus melakukan retraining ulang terhadap keseluruhan LLMs. Hal ini sangat berguna dalam skenario dinamis seperti e-commerce, sistem pengetahuan perusahaan, hukum, dan medis, di mana informasi berkembang secara cepat dan konten perlu direvisi secara berkala (Barrihadianto, 2024).
RAG juga membawa nilai tambah dari sisi efisiensi biaya dan waktu. Menurut Jaokar (2024) via Data Science Central, model berbasis retrieval dapat digunakan untuk adaptasi domain dengan menambahkan dokumen baru ke dalam vector database, tanpa perlu menghabiskan sumber daya besar untuk fine-tuning model utama. Hal ini menjadikan RAG sebagai pilihan ideal untuk perusahaan yang ingin mengadopsi LLM tanpa investasi infrastruktur besar. Dalam konteks explainability dan transparency, RAG unggul karena jawaban yang dihasilkan selalu mengandung jejak dokumen atau sumber yang digunakan. Hal ini memudahkan pengguna untuk melakukan verifikasi atas jawaban yang diterima, sesuatu yang semakin penting dalam dunia AI yang harus bisa diaudit dan dipercaya (Koval, 2025).
Dengan kemampuannya untuk menggabungkan kekuatan reasoning dari LLM dan akurasi data dari retriever, RAG menjadi fondasi yang kuat bagi sistem-sistem generatif yang digunakan di dunia nyata. Ia tidak hanya meningkatkan kualitas jawaban, tapi juga meningkatkan kepercayaan pengguna terhadap AI itu sendiri.
Perbedaan RAG dengan Model Bahasa Konvensional
RAG secara mendasar berbeda dari model bahasa konvensional seperti GPT, yang mengandalkan sepenuhnya pada pengetahuan yang diperoleh dari proses pra-pelatihan. Pada model seperti GPT, informasi dihasilkan murni dari representasi yang sudah disimpan dalam parameter model, yang tidak dapat diperbarui tanpa retraining. Hal ini membuat model konvensional sangat kuat dalam menyintesis pengetahuan yang telah ada dalam memorinya, namun lemah ketika berhadapan dengan data baru, fakta kontekstual, atau domain yang sangat spesifik dan berkembang cepat (Barrihadianto, 2024).
RAG memperbaiki keterbatasan ini dengan menambahkan lapisan retrieval informasi eksternal sebelum proses generasi dimulai. Ketika pertanyaan diajukan, model tidak langsung memberikan jawaban berdasarkan memorinya, tetapi terlebih dahulu mencari dokumen relevan dari sumber eksternal seperti vector database, lalu menyusun respons dengan mempertimbangkan informasi tersebut. Pendekatan ini menjadikan RAG sangat cocok untuk tugas-tugas yang memerlukan informasi terkini, spesifik terhadap industri atau domain, serta fleksibel untuk diperbarui tanpa melatih ulang model dasar (AWS, 2025).
Model konvensional bersifat tertutup dan statis, pengetahuannya berhenti pada tanggal cutoff pelatihan. Sebaliknya, RAG bersifat modular dan dinamis. Knowledge base eksternal dapat diperbarui sewaktu-waktu tanpa menyentuh parameter model utama. Hal ini menjadikan RAG lebih hemat biaya, lebih fleksibel, dan lebih andal dalam lingkungan yang cepat berubah, seperti hukum, kesehatan, kebijakan publik, dan industri berbasis data. Dengan demikian, RAG bukan hanya alternatif, tapi representasi dari evolusi model bahasa menuju sistem yang lebih faktual, kontekstual, dan dapat dipercaya (Gao et al., 2024).
Ketidaksempurnaan Retrieval-Augmented Generation
Meskipun RAG menjanjikan peningkatan akurasi dan fleksibilitas dalam sistem AI, pendekatan ini tidak lepas dari berbagai tantangan teknis dan operasional yang patut diperhatikan. Dalam banyak kasus, efektivitas RAG sangat bergantung pada kualitas komponen retrieval dan integrasi pipeline-nya. Berikut adalah beberapa tantangan utama dalam implementasi RAG:
- Kualitas retriever menjadi penentu utama akurasi. Jika sistem retrieval gagal menemukan dokumen yang benar-benar relevan, maka LLMs akan tetap menghasilkan output yang keliru, dengan tambahan konteks yang salah. Koval (2025) menekankan bahwa kegagalan pada tahap retrieval dapat berdampak langsung pada kualitas hasil akhir, membuat sistem tetap rentan terhadap hallucination meskipun sudah berbasis RAG.
- Latensi tambahan menjadi isu signifikan. Tidak seperti model konvensional yang langsung menghasilkan output setelah menerima input, RAG harus melalui proses pencarian data terlebih dahulu. Proses retrieval dan pembentukan prompt yang diperkuat ini menambah waktu respons secara keseluruhan. Dalam sistem real-time seperti asisten virtual atau customer service otomatis, peningkatan latensi ini bisa menurunkan pengalaman pengguna (GeeksforGeeks, 2025).
- Pengelolaan knowledge base tidaklah sederhana. Agar efektif, dokumen yang digunakan untuk retrieval harus selalu relevan, bersih, dan terstruktur dengan baik. Database yang kotor atau tidak diperbarui justru dapat memperbesar risiko misinformasi. Hal ini menuntut infrastruktur dan engineering pipeline yang solid serta tim yang secara berkala mengelola konten (AWS, 2025).
- Evaluasi sistem RAG lebih kompleks. Kesalahan bisa terjadi di salah satu atau keduanya karena output akhir dipengaruhi oleh dua komponen (retriever dan generator). Maka dari itu, diperlukan strategi evaluasi yang mampu mengisolasi masalah, seperti apakah kesalahan berasal dari pencarian yang kurang relevan, atau dari cara LLM menafsirkan konteks yang sudah benar.
- Biaya operasional yang meningkat. Meskipun tidak memerlukan retraining model utama, sistem RAG memerlukan penyimpanan untuk vector database, komputasi untuk indexing dan retrieval, serta arsitektur tambahan untuk pengelolaan dokumen. Hal ini menambah lapisan kompleksitas teknis dan finansial yang harus dipertimbangkan sebelum mengadopsinya secara luas (Jaokar, 2024).
Step by Step Proses RAG dalam Melakukan Aksinya
Untuk lebih memahami bagaimana RAG bekerja dalam praktik, mari kita telaah sebuah contoh nyata dalam konteks kesehatan. Bayangkan seorang pengguna mengalami gejala yang tidak ia pahami dan mencari jawaban melalui chatbot berbasis AI. Jika AI tersebut hanya bergantung pada data pelatihan awal seperti pada model konvensional, besar kemungkinan ia akan memberikan informasi yang sudah usang atau bahkan tidak akurat. Namun dengan pendekatan RAG, sistem dapat memberikan jawaban yang lebih akurat, relevan, dan terkini karena ia mengakses sumber pengetahuan eksternal yang terpercaya. Berikut adalah tahapan proses RAG berdasarkan contoh medis yang diambil dari GeeksforGeeks (2025).
Tahap Retrieval
Sistem RAG mengakses basis pengetahuan medis yang luas, yang dapat mencakup buku teks, makalah penelitian, hingga situs kesehatan tepercaya seperti WHO atau Mayo Clinic. Dengan memanfaatkan kemampuan pencarian semantik, retriever menelusuri database untuk menemukan potongan informasi (passages) yang relevan dengan gejala penyakit yang ditanyakan pengguna. Hasil retrieval ini difokuskan untuk memberikan fakta-fakta yang spesifik dan kontekstual terhadap query pengguna.
Tahap Generation
Setelah mendapatkan informasi yang relevan, sistem melanjutkan ke tahap generasi jawaban. LLM akan memproses potongan-potongan dokumen hasil retrieval bersama dengan query pengguna untuk menyusun jawaban yang koheren, terstruktur, dan secara faktual sesuai dengan konteks. Pada kasus medis, respons yang dihasilkan mungkin mencakup daftar gejala umum dari suatu kondisi, penjelasan ringkas mengenai penyebabnya, serta saran umum yang bersifat edukatif.
Contoh ini memperlihatkan bagaimana RAG mengubah peran AI dari sekadar model prediktif menjadi asisten berbasis pengetahuan yang dapat dipercaya. Proses retrieval yang dilanjutkan dengan generation berbasis konteks menjadikan informasi yang diberikan tidak hanya terdengar benar, tetapi juga dapat ditelusuri dan diperiksa ulang. Pendekatan ini sangat penting dalam aplikasi berisiko tinggi seperti kesehatan, hukum, atau keuangan.
Penutup
RAG hadir sebagai inovasi penting dalam mengatasi salah satu kelemahan paling mendasar dari LLMs, yaitu kecenderungan menghasilkan informasi yang keliru atau tidak akurat (hallucination). Dengan mengintegrasikan proses pencarian informasi eksternal yang relevan sebelum menghasilkan jawaban, RAG membawa paradigma baru dalam membangun sistem AI yang tidak hanya fasih, tetapi juga faktual dan bertanggung jawab. Pendekatan ini memperkuat kapabilitas reasoning LLM dengan sumber pengetahuan aktual, sekaligus menjawab kebutuhan akan sistem AI yang dapat diandalkan dalam konteks dinamis dan kompleks.
Meski begitu, seperti teknologi lainnya, RAG bukan tanpa kelemahan. Efektivitasnya sangat bergantung pada kualitas retrieval, infrastruktur teknis, serta manajemen knowledge base yang baik. Namun, dengan perencanaan dan implementasi yang tepat, RAG dapat menjadi tulang punggung untuk aplikasi AI di berbagai sektor, mulai dari layanan pelanggan hingga sistem pendukung keputusan berbasis data. Di masa depan, RAG bukan hanya akan menjadi solusi teknis, melainkan juga fondasi etis dalam memastikan AI bekerja tidak hanya pintar, tetapi juga benar.
Penulis
Satriadi Putra Santika, S.Stat., M.Kom.
FDP Scholar
Daftar Pustaka
Amugongo, L.M, Mascheroni, P., Brooks, S., Doering, S., & Seidel, J. (2025). Retrieval Augmented Generation for Large Language Models in Healthcare: A Systematic Review. PLOS Digital Health, 4, e0000877, doi:10.1371/journal.pdig.0000877.
AWS. (2025). What is RAG (Retrieval-Augmented Generation)?. Amazon. https://aws.amazon.com/what-is/retrieval-augmented-generation/. Diakses 13 Agustus 2025.
Barrihadianto, N. (2024). Memahami Retrieval-Augmented Generation (RAG) dalam Pengembangan AI. Medium. https://noerbarry.medium.com/memahami-retrieval-augmented-generation-rag-dalam-pengembangan-ai-e8a03383348d. Diakses 13 Agustus 2025.
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., & Wang, H. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. Arxiv: 2312.10997v5.
GeeksforGeeks. (2025). What is Retrieval-Augmented Generation (RAG) ?. https://www.geeksforgeeks.org/nlp/what-is-retrieval-augmented-generation-rag/. Diakses 13 Agustus 2025.
Jaokar, A. (2024). RAG and its evolution. Data Science Central. https://www.datasciencecentral.com/rag-and-its-evolution/. Diakses 13 Agustus 2025.
Koval, V. (2025). Anatomy of a RAG System. Medium. https://blog.venturemagazine.net/anatomy-of-a-rag-system-fea9e63ceae6. Diakses 13 Agustus 2025.