
Knowledge Distillation: Menyuling Pengetahuan Model AI agar Lebih Efisien
Pendahuluan
Dalam beberapa tahun terakhir, model kecerdasan buatan (AI) dan deep learning berkembang sangat pesat. Model seperti GPT, BERT, atau Vision Transformer menunjukkan kemampuan luar biasa dalam memahami bahasa, mengenali gambar, dan memecahkan berbagai tugas kompleks. Namun, di balik performa tinggi itu, terdapat tantangan besar: ukuran model yang sangat besar dan kebutuhan komputasi yang tinggi.
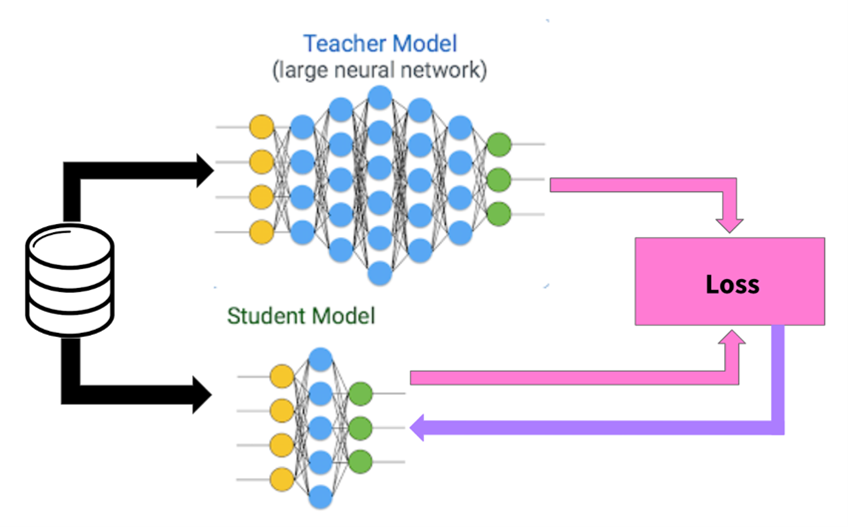
Untuk menjawab tantangan ini, para peneliti mengembangkan teknik yang disebut Knowledge Distillation — sebuah metode untuk “menyuling” pengetahuan dari model besar (teacher model) ke model yang lebih kecil (student model). Ide dasarnya adalah agar model kecil tetap dapat bekerja hampir sebaik model besar, tetapi dengan kebutuhan sumber daya yang jauh lebih ringan.
Konsep ini pertama kali diperkenalkan oleh Geoffrey Hinton dan rekannya pada tahun 2015 dalam paper berjudul Distilling the Knowledge in a Neural Network (Hinton, Vinyals & Dean, 2015). Sejak saat itu, metode ini berkembang pesat dan digunakan dalam berbagai bidang, mulai dari pemrosesan bahasa alami hingga visi komputer.
Source : https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764/
Cara Kerja Knowledge Distillation
Secara sederhana, Knowledge Distillation adalah proses transfer pengetahuan dari model besar ke model kecil melalui pembelajaran yang terarah. Prosesnya terdiri atas beberapa tahap utama:
- Model Teacher
Model teacher adalah model besar yang telah dilatih dan memiliki performa tinggi pada suatu tugas tertentu. Model ini berfungsi sebagai sumber pengetahuan yang akan ditiru oleh model student.
- Model Student
Model student memiliki arsitektur lebih sederhana dengan jumlah parameter lebih sedikit. Tujuannya adalah mempelajari cara kerja teacher agar dapat meniru pola prediksinya tanpa harus sebesar model aslinya.
- Soft Labels dan Temperature Scaling
Alih-alih hanya menggunakan label keras (seperti “anjing” atau “kucing”), Knowledge Distillation menggunakan soft labels — yaitu probabilitas keluaran dari model teacher.
Untuk membuat distribusi ini lebih “lunak” dan informatif, digunakan sebuah parameter yang disebut temperature (T). Nilai T yang lebih tinggi membuat distribusi probabilitas lebih halus, memungkinkan student memahami nuansa keputusan yang diambil oleh teacher.
- Fungsi Kehilangan (Loss Function)
Selama pelatihan, model student dioptimasi menggunakan dua sumber informasi:
- Hard Loss: perbedaan antara prediksi student dan label asli.
- Soft Loss: perbedaan antara prediksi student dan distribusi probabilitas teacher.
Keduanya digabungkan menjadi satu fungsi kehilangan total:
L=α⋅Lhard+(1−α)⋅T2⋅LsoftL = \alpha \cdot L_{\text{hard}} + (1 – \alpha) \cdot T^2 \cdot L_{\text{soft}}L=α⋅Lhard+(1−α)⋅T2⋅Lsoft
dengan α\alphaα sebagai bobot keseimbangan dan TTT sebagai suhu untuk memperhalus distribusi.
- Proses Pelatihan
Model student dilatih menggunakan kombinasi kedua loss tersebut hingga mampu meniru perilaku teacher dengan efisien. Setelah pelatihan selesai, model student dapat digunakan secara mandiri dengan kinerja yang hampir setara, tetapi jauh lebih ringan dan cepat.
Source : https://docs.pytorch.org/tutorials/beginner/knowledge_distillation_tutorial.html
Jenis dan Varian Knowledge Distillation
Seiring berkembangnya riset, para peneliti menemukan berbagai varian Knowledge Distillation, di antaranya:
- Response-based Distillation
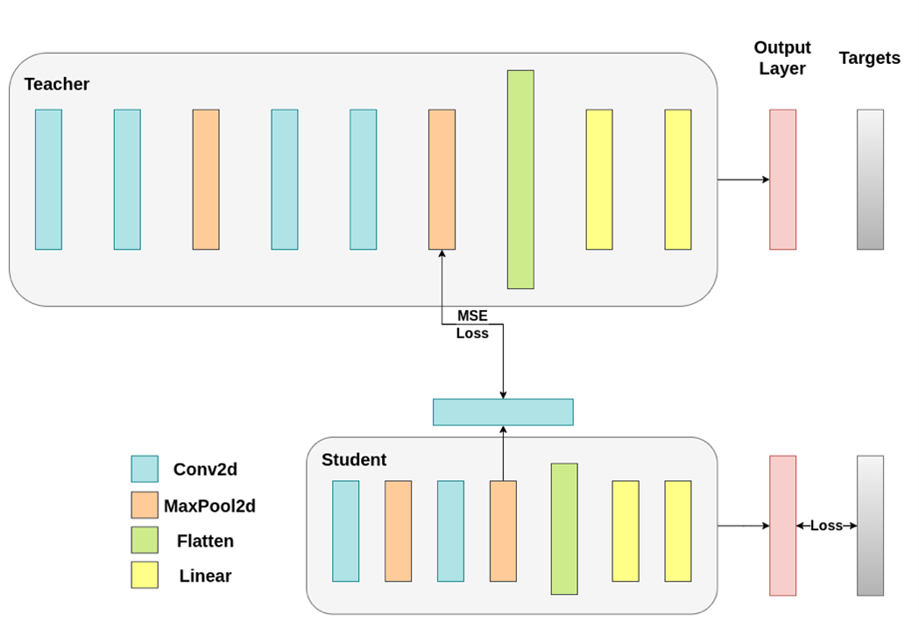
Student meniru keluaran akhir (output logits) dari teacher. Ini merupakan bentuk distillation paling klasik dan sederhana. - Feature-based Distillation
Student belajar meniru representasi internal atau fitur tersembunyi (hidden representations) dari teacher, bukan hanya hasil akhirnya. - Relation-based Distillation
Student meniru hubungan antar data yang dipelajari oleh teacher, misalnya jarak antar fitur dalam ruang representasi. - Self-Distillation
Model yang sama berperan sebagai teacher dan student secara bersamaan. Lapisan dalam model yang lebih dalam “mengajar” lapisan yang lebih dangkal, sehingga model belajar dari dirinya sendiri. - Online Distillation
Beberapa model teacher dan student dilatih secara bersamaan dalam satu sistem. Mereka saling bertukar informasi secara dinamis.
Manfaat Knowledge Distillation
- Efisiensi Komputasi dan Memori
Model yang lebih kecil dapat dijalankan di perangkat dengan sumber daya terbatas seperti ponsel, IoT, atau sistem edge computing. - Kecepatan Inferensi
Model ringan memberikan waktu prediksi yang jauh lebih cepat, penting untuk aplikasi real-time seperti deteksi objek dan asisten virtual. - Regularisasi dan Generalisasi
Distillation membantu model student menghindari overfitting, karena belajar dari distribusi probabilitas yang lebih halus. - Transfer Pengetahuan Halus (Dark Knowledge)
Model teacher tidak hanya mentransfer jawaban akhir, tetapi juga “intuisi” tentang tingkat keyakinan antar kelas.
Tantangan dalam Knowledge Distillation
- Kesenjangan Kapasitas (Capacity Gap)
Jika student terlalu sederhana, ia tidak mampu mereplikasi kompleksitas teacher. Desain arsitektur menjadi faktor penting. - Pemilihan Parameter (Temperature dan α)
Nilai parameter yang tidak tepat dapat menyebabkan student gagal belajar dengan baik dari teacher. - Ketergantungan pada Data Latih
Jika data yang digunakan untuk student berbeda dengan yang digunakan oleh teacher, hasil distillation bisa menurun. - Stabilitas Pelatihan
Proses distillation kadang tidak stabil, terutama pada model besar yang memiliki distribusi probabilitas sangat kompleks.
Aplikasi Knowledge Distillation
- Natural Language Processing (NLP)
Contoh terkenal adalah DistilBERT, versi ringan dari BERT, yang memiliki ukuran 40% lebih kecil tetapi performa hampir sama. - Computer Vision
Digunakan untuk memperkecil model deteksi objek (misalnya YOLO atau Faster R-CNN) agar dapat dijalankan di perangkat mobile. - Speech Recognition dan Edge AI
Memungkinkan sistem pengenalan suara berjalan langsung di perangkat tanpa memerlukan komputasi awan. - Pendidikan dan Riset AI
Memberikan cara baru untuk memahami bagaimana model kompleks dapat men-transfer “pengetahuan implisit” kepada model lain.
Kesimpulan
Knowledge Distillation adalah salah satu inovasi penting dalam pembelajaran mesin modern. Teknik ini memungkinkan peneliti dan praktisi menggabungkan dua hal yang sebelumnya tampak bertolak belakang: model yang kuat dan efisien secara komputasi. Dengan memindahkan pengetahuan dari model besar ke model kecil, distillation membuka jalan bagi penerapan AI yang lebih luas, cepat, dan hemat energi.
Ke depan, penelitian mengenai self-distillation, multi-teacher learning, dan cross-domain distillation akan terus berkembang. Dengan kemajuan ini, diharapkan teknologi AI dapat diintegrasikan ke berbagai aspek kehidupan tanpa kehilangan efektivitas maupun efisiensi.
Penulis
Fiqri Ramadhan Tambunan S.Kom., M.Kom – FDP Scholar
Referensi
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.
- Gou, J., Yu, B., Maybank, S. J., & Tao, D. (2021). Knowledge Distillation: A Survey. International Journal of Computer Vision, 129, 1789–1819.
- Moslemi, N., et al. (2024). Advances in Knowledge Distillation: A Comprehensive Review. Artificial Intelligence Review, 57(3), 1107–1134.
- Jiao, X., Yin, Y., Shang, L., et al. (2020). TinyBERT: Distilling BERT for Natural Language Understanding. Findings of EMNLP 2020, 4163–4174.
- Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., & Bengio, Y. (2015). FitNets: Hints for Thin Deep Nets. arXiv:1412.6550.
- Zhou, X., et al. (2024). Reproducible and Stabilized Knowledge Distillation. Machine Learning Journal, 113(2), 125–139.