
Memahami Cara Kerja Similarity Detection seperti Turnitin: Bukan Sekadar Mesin Anti-Plagiarisme
Di era digital saat ini, kemudahan dalam mengakses informasi membuat mahasiswa dapat dengan cepat menemukan berbagai referensi untuk mendukung penulisan karya ilmiah. Namun, kemudahan tersebut juga membuka peluang terjadinya plagiarisme, baik disengaja maupun tidak. Untuk menjaga keaslian karya akademik, banyak perguruan tinggi kini menggunakan sistem similarity detection seperti Turnitin, iThenticate, atau Grammarly Plagiarism Checker. Sistem ini sering disebut sebagai “alat pendeteksi plagiarisme”, padahal sebenarnya fungsinya adalah mengukur tingkat kemiripan teks dengan sumber lain yang telah ada.
 Source : https://www.turnitin.id/
Source : https://www.turnitin.id/
Secara sederhana, similarity detection system adalah alat berbasis algoritma yang membandingkan teks yang diunggah pengguna dengan jutaan dokumen lain di dalam basis data. Sumber pembanding ini meliputi situs web, artikel jurnal, buku digital, serta arsip tugas mahasiswa dari berbagai universitas. Tujuan sistem ini bukan untuk langsung menilai apakah suatu teks merupakan plagiarisme, melainkan menghitung seberapa besar kesamaan teks pengguna dengan sumber yang sudah ada. Hasil perbandingan ini disebut sebagai Similarity Index atau Similarity Score.
Cara Kerja Sistem Similarity Detection seperti Turnitin
Proses kerja Turnitin terdiri atas beberapa tahap penting yang melibatkan analisis teks secara sistematis. Berikut adalah tahapan umumnya:
- Pra-pemrosesan Teks (Pre-processing)
Pada tahap awal, sistem akan membersihkan dokumen dari elemen-elemen nonteks seperti gambar, tabel, catatan kaki, dan format khusus. Langkah ini dilakukan agar hanya isi teks utama yang dianalisis. Selanjutnya, sistem mengubah semua huruf menjadi format standar dan menghapus karakter yang tidak relevan agar hasil pencocokan menjadi lebih akurat.
- Pemisahan Kata atau Frasa (Tokenization)
Setelah teks dibersihkan, sistem memecah isi dokumen menjadi potongan-potongan kecil yang disebut token. Token bisa berupa kata tunggal, frasa, atau kombinasi beberapa kata yang berurutan (n-gram). Misalnya, kalimat “Pendidikan tinggi di Indonesia terus berkembang” dapat diubah menjadi potongan-potongan seperti “Pendidikan tinggi di”, “tinggi di Indonesia”, dan “Indonesia terus berkembang”. Langkah ini memungkinkan sistem untuk mengenali pola teks dengan lebih detail.
- Pencocokan Pola (Text Matching)
Pada tahap ini, sistem melakukan proses pencocokan antara token-token dari dokumen pengguna dengan database yang dimilikinya. Turnitin menggunakan dua pendekatan utama:
- String Matching: mencocokkan kata dan frasa yang identik secara langsung.
- Fuzzy Matching: mengenali teks yang mengalami sedikit perubahan, seperti penggantian sinonim atau pergeseran struktur kalimat.
Database yang digunakan terdiri dari tiga sumber utama:
- Database internal Turnitin (tugas dan karya mahasiswa dari seluruh dunia).
- Database eksternal (artikel jurnal, e-book, repository, dan situs web).
- Konten arsip yang diindeks dari berbagai penerbit dan institusi akademik.
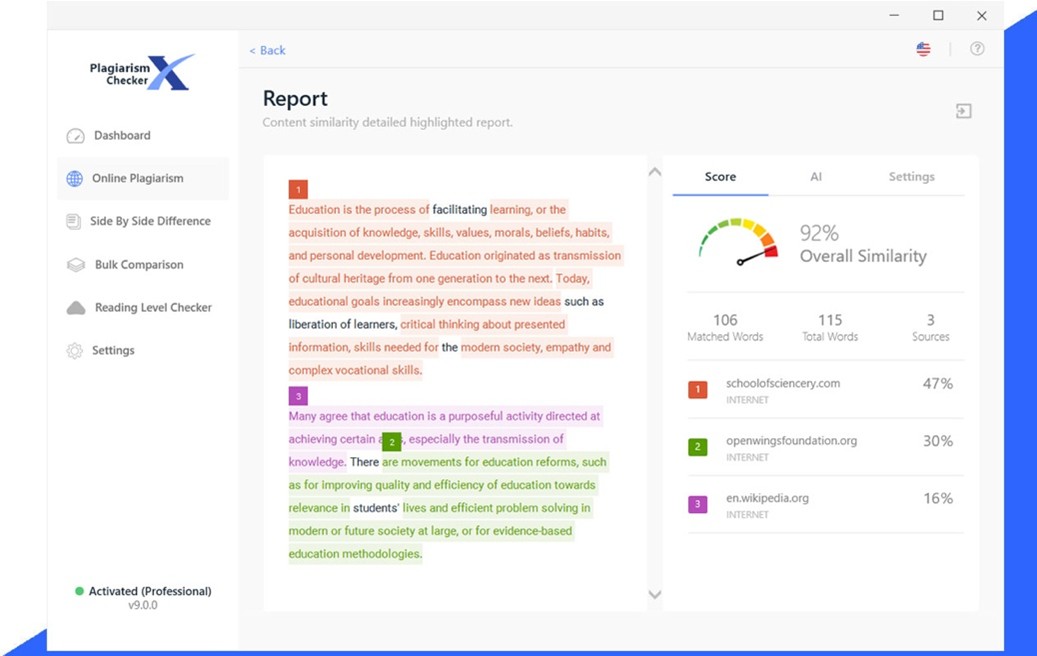
- Perhitungan Persentase Kemiripan (Similarity Calculation)
Setelah proses pencocokan selesai, sistem menghitung persentase kesamaan antara dokumen pengguna dan sumber yang ditemukan. Misalnya, 12 persen teks mirip dengan jurnal A, 8 persen dengan situs web B, dan 5 persen dengan tugas mahasiswa lain, sehingga total similarity index menjadi 25 persen. Namun, angka ini tidak berarti 25 persen dari teks adalah hasil plagiarisme. Nilai tersebut hanya menunjukkan bahwa 25 persen isi dokumen memiliki kesamaan dengan teks lain yang telah ada.
- Pembuatan Laporan (Report Generation)
Tahap terakhir adalah pembuatan laporan hasil pemeriksaan. Laporan ini berisi:
- Persentase total kemiripan.
- Daftar sumber yang memiliki kesamaan dengan dokumen pengguna.
- Bagian teks yang disorot warna tertentu untuk menunjukkan bagian yang mirip.
- Opsi filter untuk mengabaikan kutipan resmi, daftar pustaka, atau bagian pendek yang berada di bawah ambang batas kata tertentu.
Dengan laporan tersebut, pengguna dapat meninjau ulang bagian mana yang perlu diperbaiki atau ditulis ulang agar lebih orisinal.
Source : https://plagiarismcheckerx.com/
Interpretasi Hasil dan Kesalahan Umum
Skor similarity yang tinggi tidak selalu menunjukkan adanya plagiarisme. Dalam banyak kasus, nilai kemiripan meningkat karena hal-hal seperti penggunaan kutipan langsung, istilah teknis yang sulit diubah, atau adanya bagian standar seperti metodologi penelitian. Oleh karena itu, interpretasi laporan Turnitin perlu dilakukan secara cermat dengan mempertimbangkan konteks dan cara pengutipan yang digunakan.
Tips Menurunkan Nilai Similarity secara Etis
Agar hasil pemeriksaan Turnitin tetap rendah dan karya tulis tetap sesuai etika akademik, berikut beberapa langkah yang bisa dilakukan:
- Gunakan parafrase dengan gaya bahasa sendiri. Tulis ulang gagasan dari sumber lain menggunakan pemahaman pribadi, bukan sekadar mengganti kata.
- Cantumkan sumber dengan format sitasi yang benar. Gunakan gaya penulisan yang sesuai, seperti APA, IEEE, atau Chicago Style.
- Gunakan kutipan langsung hanya bila perlu. Pastikan setiap kutipan diberi tanda petik dan sumbernya disebutkan.
- Periksa dokumen secara mandiri sebelum pengumpulan. Gunakan Turnitin untuk memastikan tidak ada bagian yang terlalu mirip.
- Hindari manipulasi teknis. Mengubah format huruf, menyisipkan karakter tersembunyi, atau menambahkan simbol tidak akan menipu sistem dan justru bisa terdeteksi sebagai pelanggaran.
Kesimpulan
Turnitin dan sistem similarity detection lainnya bukanlah alat untuk menghukum mahasiswa, melainkan sarana edukatif yang membantu memahami pentingnya keaslian dan integritas akademik. Sistem ini berfungsi sebagai cermin yang menunjukkan seberapa orisinal tulisan seseorang, bukan sebagai penentu tunggal plagiarisme. Dengan memahami cara kerjanya, mahasiswa dan dosen dapat memanfaatkannya untuk memperbaiki kualitas penulisan, meningkatkan kejujuran ilmiah, dan menjaga reputasi akademik kampus.
Penulis
Fiqri Ramadhan Tambunan S.Kom., M.Kom – FDP Scholar
Referensi
- (2024). Understanding the Similarity Report. Retrieved from https://www.turnitin.com
- (2023). Similarity Report Guide. Turnitin Official Documentation.
- Meuschke, N., & Gipp, B. (2013). State-of-the-art in detecting academic plagiarism. International Journal for Educational Integrity, 9(1), 50–71.
- Gipp, B., & Meuschke, N. (2014). Citation-based plagiarism detection: A new paradigm in plagiarism detection. ACM Journal on Computing and Cultural Heritage, 7(1), 1–19.
- Alzahrani, S. M., Salim, N., & Abraham, A. (2012). Understanding plagiarism linguistic patterns, textual features, and detection methods. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(2), 133–149.
- Şendağ, S., & Odabaşı, H. F. (2020). Plagiarism detection and academic integrity in higher education: A review of Turnitin practices. Journal of Academic Ethics, 18(2), 173–188.