
Di Balik Tumbangnya Cloudflare: Berbagai Layanan Global Ikut Terkena Imbasnya
 (sumber: dokumentasi pribadi)
(sumber: dokumentasi pribadi)
Pada 18 November 2025 kemarin, internet global sempat tersendat ketika Cloudflare, yang merupakan penopang besar jaringan web dunia mengalami gangguan serius pada infrastruktur internalnya, sehingga mengalami global outage. Insiden ini pertama kali diumumkan pada pukul 11:28 waktu UTC, saat Cloudflare melaporkan adanya internal service degradation yang menyebabkan sejumlah layanan mengalami error secara intermittent [1]. Mungkin bagi banyak orang, insiden ini kelihatan seperti ‘internet lagi rusak bareng-bareng’. Dampaknya terasa luas, karena berbagai layanan web yang menggunakan Cloudflare tidak bisa diakses, termasuk X (formerly Twitter), ChatGPT, hingga dashboard internal Cloudflare sendiri. Butuh waktu sekitar hampir 6 jam hingga pukul 17:07 waktu UTC sampai Cloudflare mengumumkan bahwa insiden resmi diselesaikan. Lucunya, penyebabnya bahkan bukan karena DDoS atau serangan siber lainnya.
Kesalahan Teknis, Bukan Serangan
Cloudflare melalui situs blog resmi mereka [2] menjelaskan bahwa insiden global outage ini bukan akibat cyber–attack atau DDoS, melainkan teknis internal akibat kegagalan berjenjang dari perubahan perizinan database. Pembaruan izin salah satu sistem database internal (ClickHouse) menyebabkan database mengeluarkan entri duplikat ke dalam sebuah query yang digunakan untuk membangun “feature file”, file penting yang digunakan oleh sistem Bot Management Clouflare. Feature file itu kemudian bertambah ukurannya menjadi dua kali lipat, dipropagasi dan menyebar luas ke seluruh server Cloudflare di seluruh dunia, melewati batas yang diantisipasi oleh sistem mereka. Terjadilah crash pada core proxy software Clouflare akibat file yang terlalu besar itu, yang berimbas pada aliran traffic di seluruh jaringan Cloudflare ikut tumbang.
Sempat Disangka Sebagai Serangan
Karena pola error yang naik-turun, sistem internal Cloudflare mencatat gejala seperti serangan DDoS besar-besaran. Apalagi, secara kebetulan, status page Cloudflare juga ikut down, padahal status page itu di-host di luar Cloudflare, sepenuhnya terpisah. Ini makin membuat tim mengira ada pihak yang sedang menyerang seluruh infrastruktur mereka.
Penyebab pola error yang naik turun adalah karena file Bot Management itu di-generate ulang setiap 5 menit. Jika query dijalankan pada node ClickHouse yang sudah mendapat update permissions, hasilnya jelek. Jika query di node yang belum berubah, hasilnya benar. Alhasil 5 menit jaringan normal, tapi 5 menit kemudian semuanya error, lalu kembali lagi sampai akhirnya semua node ClickHouse menghasilkan file jelek. Barulah sistem ‘stabil’ tapi dalam kondisi gagal.
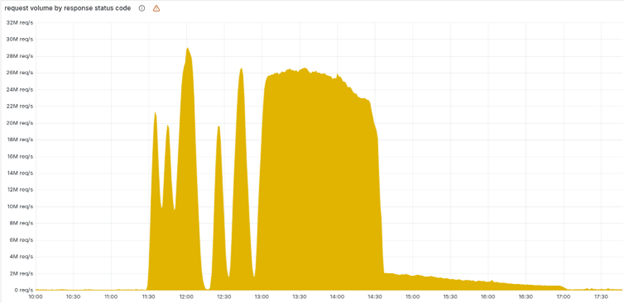
Bagan yang menunjukkan volume kode status HTPP error 5XX yang dilayani jaringan Cloudflare (sumber: https://blog.cloudflare.com/18-november-2025-outage/?utm_source=chatgpt.com/)
Dampak pada Layanan
- Banyak pengguna melaporkan error di layanan populer: ChatGPT, X, aplikasi kripto, platform developer
- Banyak layanan mengalami HTTP 5xx errors, terutama aplikasi yang tergantung pada Cloudflare untuk routing dan proteksi
- Beberapa sistem internal Cloudflare juga terganggu: Workers KV, dashboard (susah login), sistem autentikasi, dan Turnstile
- Reputasi Cloudflare bisa terpengaruh, terutama setelah outage besar (ini disebut sebagai salah satu outage terburuk sejak 2019 menurut internal Cloudflare).
Secara brutal, insiden ini menunjukkan bagaimana internet global sangat bergantung pada satu pemain besar seperti Cloudflare. Kesalahan kecil pada satu komponen bisa memicu efek domino ke jutaan pengguna.
Pemulihan
Mulai 13:05 UTC, Cloudflare melakukan langkah-langkah :
- Mem-bypass beberapa layanan (Workers KV, Access) agar tidak memakai proxy yang rusak.
- Menghentikan propagasi otomatis file konfigurasi.
- Mengganti file rusak dengan versi lama yang masih valid.
- Memaksa restart pada core proxy di seluruh jaringan.
Pada 14:30 UTC, traffic inti mulai pulih. Dan pada 17:06 UTC, seluruh sistem kembali normal.
Future Improvement
Dalam pernyataan resmi mereka, Cloudflare juga menegaskan hal-hal yang akan dilakukan sebagai perbaikan ke depannya.
- Mereka berencana memperkuat sistem agar lebih toleran terhadap file konfigurasi besar (hardening ingestion).
- Menyiapkan kill switch global untuk fitur.
- Mencegah kemungkinan core dump atau laporan kesalahan (error report) yang membebani sumber daya sistem.
- Meninjau ulang mode kegagalan untuk kondisi error di seluruh modul core proxy.
Take A Notes!
- Perusahaan cloud besar sekalipun bisa punya single point of failure yang bahaya kalau tidak diantisipasi dengan desain redundan dan proteksi ekstra. Terbukti dari insiden global outage dari Cloudflare, padahal mereka menangani ~20% trafik web global. Jadi, ketika mereka down, efeknya tidak kecil. Ini jadi pengingat bahwa meski memakai ‘cloud’, internet tetap rentan, satu titik kegagalan bisa menjatuhkan banyak layanan besar sekaligus.
- Automasi sangat berguna (misalnya untuk memperbarui file konfig), tetapi juga bisa menjadi bumerang jika perubahan-perubahan tersebut tidak diperiksa dengan batas aman. Sistem Bot Management Cloudflare contohnya, memang penting buat proteksi, tapi ketika mekanismenya sendiri gagal, dia bisa jadi sumber bencana.
- Pengguna dan perusahaan yang bergantung ke Cloudflare pasti akan menuntut jaminan lebih kuat agar kejadian serupa tidak terulang, tetapi syukurnya Cloudflare cukup terbuka soal penyebab dan cara pemulihan, yang membantu menumbuhkan kembali kepercayaan.
Penulis
Felicia Natania Lingga, S.Kom – FDP Scholar
Referensi
[1] Cloudflare Global Network experiencing issues: Incident Report for Cloudflare. Cloudflare System Status. Retrieved from: https://www.cloudflarestatus.com/incidents/8gmgl950y3h7 on 20 November 2025
[2] Prince, M. 2025. Cloudflare outage on November 18, 2025. Cloudflare Blog. Retrieved from: https://blog.cloudflare.com/18-november-2025-outage/?utm_source=chatgpt.com/ on 20 November 2025