
Tantangan NLP untuk Bahasa Daerah: Menjembatani Kesenjangan Teknologi Linguistik di Indonesia
 Source: midjourney
Source: midjourney
Indonesia memiliki kekayaan linguistik yang luar biasa dengan lebih dari 700 bahasa daerah tersebar dari Sabang sampai Merauke. Namun, di era digital yang didominasi teknologi Natural Language Processing (NLP), sebagian besar bahasa daerah ini tertinggal jauh di belakang. Sementara bahasa-bahasa besar seperti Inggris, Mandarin, atau bahkan Bahasa Indonesia terus berkembang dalam ekosistem teknologi, bahasa-bahasa daerah menghadapi ancaman kepunahan, baik secara kultural maupun teknologi.
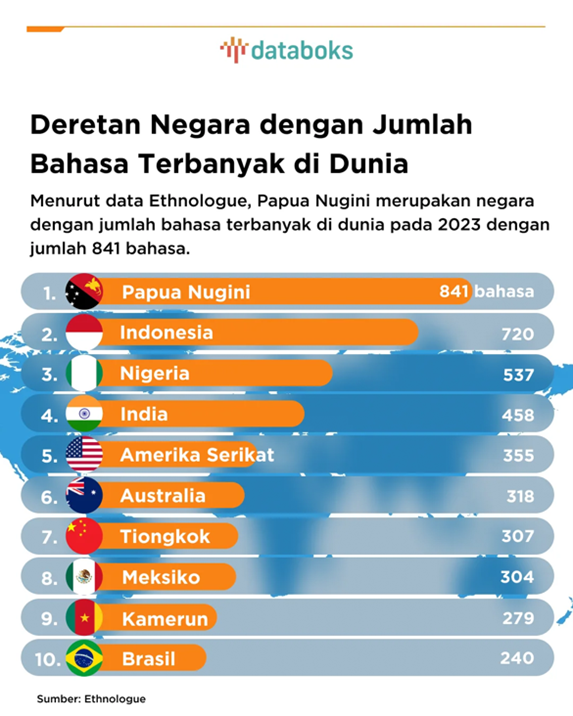
Source: databoks
Mengapa Bahasa Daerah Penting dalam Era Digital?
Bahasa bukan sekadar alat komunikasi, melainkan wadah identitas, pengetahuan lokal, dan pandangan dunia suatu komunitas. Ketika sebuah bahasa terpinggirkan dari ruang digital, bukan hanya penuturnya yang kehilangan akses terhadap teknologi modern, tetapi seluruh umat manusia kehilangan perspektif unik yang dibawa oleh bahasa tersebut. Bayangkan seorang petani di pedalaman Sumba yang ingin mengakses informasi pertanian melalui smartphone, namun semua aplikasi hanya tersedia dalam Bahasa Indonesia atau Inggris. Atau seorang nenek di Toraja yang ingin bercerita kepada cucunya melalui video call, tetapi fitur subtitle otomatis tidak mengenali bahasanya. Inilah realitas yang dihadapi jutaan penutur bahasa daerah di Indonesia.
Tantangan Utama dalam Pengembangan NLP untuk Bahasa Daerah
Tantangan terbesar dalam mengembangkan sistem NLP untuk bahasa daerah adalah minimnya data digital yang tersedia. Kebanyakan model NLP modern berbasis pembelajaran mesin membutuhkan ribuan bahkan jutaan contoh teks untuk dapat berfungsi dengan baik. Bahasa Inggris memiliki miliaran halaman web dan dataset yang tersedia secara terbuka, sementara bahasa-bahasa seperti Sasak, Batak Toba, atau Makassar hanya memiliki sebagian kecil dari jumlah tersebut. Data yang ada pun sering kali tidak terstruktur dengan baik, masih tersimpan dalam bentuk tulisan tangan, rekaman audio tanpa transkripsi, atau dokumen-dokumen kuno yang belum terdigitalisasi.
Kompleksitas variasi dialek menambah kesulitan tersendiri. Bahasa daerah di Indonesia memiliki variasi dialek yang sangat beragam, bahkan dalam satu kelompok bahasa yang sama. Sebagai contoh, Bahasa Jawa memiliki dialek Jawa Tengah, Jawa Timur, dan Banyumasan yang masing-masing memiliki kosakata dan pelafalan berbeda. Bahasa Batak terbagi menjadi Batak Toba, Karo, Mandailing, Pakpak, Simalungun, dan Angkola dengan karakteristik linguistik yang unik. Sebuah model yang dilatih untuk Bahasa Jawa Tengah mungkin tidak akan bekerja dengan baik untuk Bahasa Jawa Banyumasan, sehingga pengembang harus memutuskan apakah akan membuat model terpisah untuk setiap dialek atau mencoba membuat model yang cukup fleksibel untuk menangani semua variasi.
Sistem penulisan yang beragam juga menjadi hambatan signifikan. Berbeda dengan Bahasa Indonesia yang menggunakan alfabet Latin secara konsisten, banyak bahasa daerah memiliki sistem penulisan tradisional yang unik seperti aksara Jawa, Bali, Sunda, Rejang, dan Lontara. Tantangannya berlipat ganda ketika sebuah bahasa dapat ditulis dalam dua sistem berbeda. Misalnya, Bahasa Jawa dapat ditulis dalam aksara Jawa atau alfabet Latin, dan model NLP harus mampu memahami dan memproses kedua sistem ini dengan akurat.
Ketiadaan standardisasi ortografi memperumit situasi. Banyak bahasa daerah tidak memiliki aturan ejaan yang terstandarisasi secara luas, sehingga kata yang sama bisa ditulis dengan berbagai cara oleh penutur yang berbeda. Dalam Bahasa Minangkabau, kata “tidak” bisa ditulis sebagai “indak”, “indak”, atau “ndak” tergantung pada preferensi penulis atau daerah asalnya. Ketiadaan standardisasi ini menyulitkan pelatihan model NLP karena sistem akan menganggap variasi ejaan yang sama sebagai kata yang berbeda, mengurangi efisiensi pembelajaran dan akurasi model.
Setiap bahasa juga memiliki struktur gramatikal dan fenomena linguistik yang khas. Bahasa Jawa memiliki tingkat tutur (ngoko, madya, krama) yang sangat kompleks dan harus disesuaikan berdasarkan konteks sosial. Bahasa Sunda mengenal sistem honorifik yang rumit, sedangkan bahasa-bahasa di Papua memiliki struktur morfologi yang sangat berbeda dari bahasa-bahasa Austronesia di bagian barat Indonesia. Model NLP yang dirancang untuk Bahasa Inggris atau Indonesia tidak akan otomatis memahami kompleksitas ini tanpa penelitian linguistik yang mendalam dan adaptasi arsitektur model yang sesuai.
Dampak Sosial dan Upaya Pelestarian
Ketiadaan teknologi NLP untuk bahasa daerah bukan sekadar masalah teknis, tetapi isu keadilan sosial dan pelestarian budaya. Ketika teknologi hanya tersedia dalam bahasa-bahasa dominan, tercipta kesenjangan digital yang memperdalam ketimpangan sosial. Anak-anak dari komunitas penutur bahasa daerah terpaksa belajar dalam bahasa yang bukan bahasa ibu mereka untuk dapat mengakses pendidikan dan teknologi. Penelitian menunjukkan bahwa pembelajaran dalam bahasa ibu di tahun-tahun awal pendidikan sangat penting untuk perkembangan kognitif dan prestasi akademik anak.
Lebih jauh lagi, marginalisasi bahasa daerah dalam ruang digital mempercepat proses kepunahan bahasa. Ketika generasi muda lebih banyak berinteraksi dengan teknologi dalam Bahasa Indonesia atau Inggris, mereka secara bertahap kehilangan kemampuan untuk berbicara dalam bahasa nenek moyang mereka. UNESCO memperkirakan bahwa satu bahasa punah setiap dua minggu, dan banyak bahasa daerah Indonesia berada dalam daftar bahasa yang terancam punah.
Meskipun tantangannya besar, berbagai upaya telah dilakukan untuk mengembangkan NLP bagi bahasa daerah Indonesia.
Solusi dan Langkah ke Depan
Untuk mengatasi tantangan-tantangan ini, diperlukan pendekatan multidimensional yang melibatkan berbagai pemangku kepentingan. Teknologi terkini seperti transfer learning memungkinkan model yang dilatih pada bahasa-bahasa besar untuk diadaptasi ke bahasa dengan data terbatas. Model multibahasa seperti mBERT atau XLM-RoBERTa dapat menjadi titik awal yang baik untuk pengembangan NLP bahasa daerah. Melibatkan penutur asli dalam proses pengumpulan dan anotasi data melalui platform crowdsourcing dapat membantu mengumpulkan data dalam skala besar dengan biaya yang lebih terjangkau.
Pemerintah perlu mengalokasikan anggaran khusus untuk penelitian dan pengembangan teknologi bahasa daerah sebagai bagian dari upaya pelestarian budaya nasional. Meningkatkan kesadaran tentang pentingnya pelestarian bahasa daerah dan teknologi yang mendukungnya dapat mendorong lebih banyak orang untuk berkontribusi. Kolaborasi internasional dengan negara-negara lain yang menghadapi tantangan serupa juga dapat memberikan wawasan berharga dan membuka akses ke sumber daya dan keahlian.
Pengembangan teknologi NLP untuk bahasa daerah bukan sekadar proyek teknologi, melainkan perjuangan untuk melestarikan identitas budaya dan memastikan keadilan digital bagi semua warga negara. Dengan kolaborasi antara peneliti, teknolog, komunitas lokal, dan pembuat kebijakan, kita dapat membangun ekosistem teknologi yang lebih inklusif—yang tidak hanya melayani bahasa-bahasa dominan, tetapi juga menghormati dan melestarikan keragaman linguistik yang menjadi kekayaan bangsa.
Penulis:
Nikita Ananda Putri Masaling, S.Kom., M.Kom.
Referensi
- Aji, A. F., et al. (2022). “One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia.” Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.
- UNESCO. (2023). “Atlas of the World’s Languages in Danger.” UNESCO Publishing.
- Joshi, P., et al. (2020). “The State and Fate of Linguistic Diversity and Inclusion in the NLP World.” Proceedings of ACL 2020.
- Albiruni, R., et al. (2023). “Building NLP Resources for Indonesian Regional Languages: Challenges and Opportunities.” Language Resources and Evaluation.