
Penggunaan Latent Semantic Analysis (LSA) dalam Pemrosesan Teks
Latent Semantic Analysis (LSA) merupakan sebuah metode yang memanfaatkan model statistik matematis untuk menganalisa struktur semantik suatu teks. LSA bisa digunakan untuk menilai esai dengan mengkonversikan esai menjadi matriks-matriks yang diberi nilai pada masing-masing term untuk dicari kesamaan dengan term referensi. Secara umum, langkah-langkah LSA dalam penilaian esai adalah sebagai berikut:
1. Text Preprocessing
Preprocessing adalah proses normalisasi teks sehingga informasi yang dimuat merupakan bagian yang padat dan ringkas namun tetap merepresentasikan informasi yang termuat didalamnya. Dalam tahap ini, terdapat beberapa proses diantaranya:
- Stopwords Removal : Pada stopwords removal, kata-kata yang tergolong sebagai kata depan, kata penghubung, dan kata-kata lain yang tidak mewakili makna dari kalimat akan dieliminasi. Contohnya adalah sebagai berikut:
- Menghapus kata-kata “am, is, are, and, in, etc” dan berbagai singkatan. Apabila dalam konteks Bahasa Indonesia, contoh kata-kata yang dihapus adalah “yang, di, ke, dari, pada, dalam, dan”.
Contoh daftar kata-kata yang termasuk dalam stopword bisa dilihat pada tautan: https://www.ranks.nl/stopwords - Mengubah kata yang diawali dengan huruf besar menjadi huruf kecil.Di bawah ini adalah contoh dari kalimat sebelum dan sesudah proses stopwords removal:
- Sebelum proses stopwords removal : “Latent Semantic Analysis (henceforth LSA) is a linguistic theory and method. It has been used in natural language processing to determine semantic relationships in large bodies of corpora.”
- Sesudah proses stopwords removal : “latent semantic analysis linguistic theory method used natural language processing determine semantic relationships large bodies corpora”
- Menghapus kata-kata “am, is, are, and, in, etc” dan berbagai singkatan. Apabila dalam konteks Bahasa Indonesia, contoh kata-kata yang dihapus adalah “yang, di, ke, dari, pada, dalam, dan”.
- Stemming : Langkah berikutnya adalah stemming. Pada proses ini, kata akan dinormalkan menjadi kata dasar pembentuk kata tersebut. Caranya adalah dengan menghilangkan imbuhan yang melekat pada kata, sehingga hasilnya adalah kata dasarnya. Apabila dalam Bahasa Inggris, proses stemming bisa mengikutsertakan pengembalian bentuk tense dari kata kerja bentuk ke-2 atau ke-3 menjadi kata kerja bentuk ke-1.
Di bawah ini adalah contoh dari kalimat sebelum dan sesudah proses stemming:- Sebelum proses stemming : “latent semantic analysis linguistic theory method used natural language processing determine semantic relationships large bodies corpora”
- Sesudah proses stemming : “latent semantic analysis linguistic theory method use nature language process determine relationship large body corpo”
2. Term-document Matrix
Setelah melalui stopwords removal dan stemming, matriks term-document dibangun dengan menempatkan kata hasil proses stemming (term) ke dalam baris. Matriks ini disebut term-document matrix. Setiap baris mewakili sebuah kata yang unik, sedangkan setiap kolom mewakili konteks dari mana kata-kata tersebut diambil. Konteks yang dimaksud bisa berupa kalimat, paragraf, atau seluruh bagian dari teks.
Di bawah ini merupakan contoh term-document matrix:
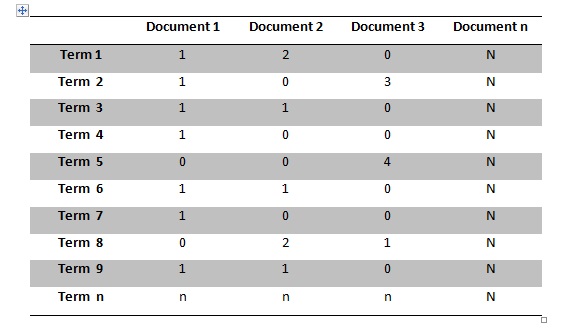
Pada tabel di atas, baris pertama mewakili stemmed term (term 1, term 2, dst), dan bagian kolom mewakili konteks, yaitu teks. Nilai yang terletak pada setiap cell pada tabel menunjukkan berapa kali sebuah term muncul dalam sebuah dokumen. Contohnya, term 1 muncul 1 kali pada dokumen ke-1, dan muncul 2 kali pada dokumen ke-2, namun term 1 tidak muncul pada dokumen 3, dan seterusnya.
3. Singular Value Decomposition
Singular Value Decomposition (SVD) adalah salah satu teknik reduksi dimensi yang bermanfaat untuk memperkecil nilai kompleksitas dalam pemrosesan term-document matrix. SVD merupakan teorema aljabar linier yang menyebutkan bahwa persegi panjang dari term-document matrix dapat dipecah/didekomposisikan menjadi tiga matriks, yaitu :
– Matriks ortogonal U
– Matriks diagonal S
– Transpose dari matriks ortogonal V
Yang dirumuskan dengan :

Hasil dari proses SVD adalah vektor yang akan digunakan untuk menghitung similaritasnya dengan pendekatan cosine similarity.
4. Cosine Similarity Measurement
Cosine similarity digunakan untuk menghitung nilai kosinus sudut antara vektor dokumen dengan vektor kueri. Semakin kecil sudut yang dihasilkan, maka tingkat kemiripan esai semakin tinggi.
Formula dari cosine similarity adalah sebagai berikut:

Dari hasil cosine similarity, akan didapatkan nilai yang akan dibandingkan dengan penilaian manusia untuk diuji selisih nilainya.