
Learning: Candidate Elimination
Version Space dapat didefinisikan sebagai kumpulan hipotesa yang valid dari sebuah algoritma.
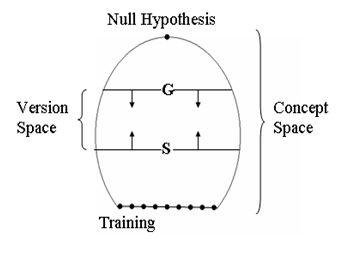
Di dalam concept space, version space direpresentasikan menjadi kumpulan set G (General) dan S (Spesific), dimana G mengandung deskripsi yang paling general (umum) sedangkan S mengandung deskripsi yang paling spesifik, dan deskripsi tersebut konsisten dengan data pelatihan yang ada.
Data pelatihan yang positif akan membuat kelompok data S menjadi lebih umum sedangkan data pelatihan negative akan membuat kelompok data G menjadi lebih spesifik. Apabila didapatkan kelompok data S dan G yang konvergen, maka dapat diperoleh sebuah deskripsi konsep yang tunggal (single concept). Algoritma yang dapat digunakan untuk mencapai tujuan ini di dalam version space dikenal sebagai algoritma Candidate Elimination (CE).
Di dalam algoritma CE, diterapkan 2 algoritma mendasar:
- Specific to General Search Algorithm
Algoritma ini bertujuan untuk men-general-kan kelompok data yang sangat spesifik. Dalam pseudocode, algoritma ini dapat didefinisikan sebagai:

- General to Specific Search Algorithm
Algoritma ini bertujuan untuk menspesifikan kelompok data yang sangat general. Dalam pseudocode, algoritma ini dapat didefinisikan sebagai:
 Dengan menggabungkan kedua algoritma tersebut, maka algoritma dari CE dapat didefinisikan dengan:
Dengan menggabungkan kedua algoritma tersebut, maka algoritma dari CE dapat didefinisikan dengan:Diketahui:
Representasi sebuah bahasa dan kumpulan data pelatihan positif dan negatifCarilah:
Deskripsi konsep yang konsisten dengan semua data pelatihan positif dan tidak ada yang konsisten dengan data pelatihan negativeLangkah-langkah:
- Inisialisasikan G agar mengandung 1 elemen, yakni deskripsi null untuk semua fitur yang direpresentasikan dalam variabel
- Inisialisasikan S agar mengandung 1 elemen, data pelatihan positif pertama
- Terimalah data pelatihan baru, dimana:
- Jika data positif :
- Hapus semua member dari G yang tidak sesuai data pelatihan positif
- Untuk setiap S, jika S tidak sesuai dengan data positif, maka gantikan S dengan generalisasi yang paling spesifik yang sesuai dengan data positif
- Jika data negative
- Hapus semua member S yang sesuai dengan data pelatihan negative
- Untuk setiap G yang sesuai dengan data negative, maka gantikan G dengan spesialisasi yang paling umum yang tidak sesuai dengan data negatif
- Jika data positif :
- Jika S dan G pada akhirnya mencapai kondisi singleton, dan sama, maka selesai. Bila tidak sama, maka kemungkinan ada ketidakkonsistenan pada data pelatihan yang ada.
Contoh penerapannya dalam dilihat dalam kasus berikut ini:
Diketahui data pelatihan, di bawah ini, carilah konsepnya:



Dengan demikian didapatkan konsep berupa: “Japan, Economy” car.
References
Stuart Russell, Peter Norvig,. 2010. Artificial intelligence : a modern approach. PE. New Jersey. ISBN:9780132071482, Chapter 19

