
Feature Descriptor : SIFT (Scale Invariant Feature Transform) Part 1 : Introduction to SIFT
Features and interesting points are important information that can be extracted from an image to provide a “feature” description of an object in the image. This description can then be used to locate the object in another image which is usually called as image matching. Image matching is a fundamental aspect of many problems in computer vision, including object or scene recognition, solving for 3D structure from multiple images, and motion tracking. In order to achieve a good matching result, there are many considerations when extracting features and record them from an image.
Matching features across different images is a common problem in computer vision. When the images are similar in nature, which means they have same scales and same orientations, simple corner detector can be used to extract features from both images. However, when the images are different both in scales and rotations, simple corner detector cannot solve the problem. Some corner detectors like Harris detector is rotation invariant, which means, we still can find the same corner even if the image is rotated. It is obvious because corners remain corners in rotated image. However, Harris is not scale invariant because a corner may not be a corner if the image is scaled. A corner in a small image within a small window may look flat when it is zoomed in the same window as illustrated on the picture below :
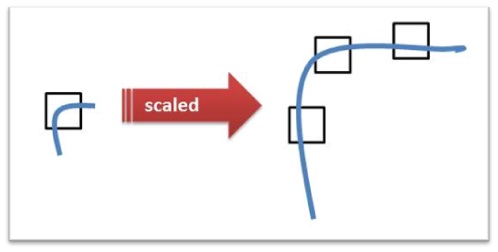
SIFT stands for Scale Invariant Feature Transform is a popular interest point descriptor which is widely used because of its scale and rotation invariant characteristics. SIFT was created by David Lowe from University British Columbia in 2004. The example of SIFT robustness against rotation and scale transformation is shown in the picture below :

In short, there are three goals which are expected to be achieved by using SIFT :
- To extract distinctive invariant features which can be correctly matched against a large database of features, providing a basis for object and scene recognition
- Extracting features which are invariant to image scale and rotation
- Extracting features which are robust against affine distortion, change in 3D viewpoint, and noise.
The Advantages of SIFT
Besides of its scale and rotation invariant features, SIFT also have several other advantages:
- Locality
Before we go through details, we should know first what is local feature and what is the difference between local and global features?
Basically there are two types of features that can be extracted from an image, they are global and local features. Global features describe the image as a whole to generalize the entire object. It includes contour representations, shape descriptors, and texture features such as shape matrices and Histogram of Gradient (HOG). Local features describe the image patches (key points in the image) of an object. The example of local features are SIFT and SURF. Generally, global features are used for low level applications such as object detection and classification and for higher level applications such as object recognition, local features are used because it is more robust to occlusion and clutter than global features. - Distinctive
Individual feature extracted by SIFT has very distinctive descriptor, which allows a single feature to find its correct match with good probability in a large database of features. - Quantity
One major advantage of SIFT is it can generates large numbers of features that densely cover the image over the full range scales and locations. For instance, it is possible to collect 2000 stable features from a typical image of size 500×500 pixels. As we know that the quantity of features is important for object recognition, where to detect the small objects in cluttered background, it requires at least 3 features from each object to be correctly matched for reliable identification. - Efficiency
The performance of SIFT is close to real-time performance
The details about SIFT algorithm will be explained in part 2.
References
Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2), 91-110.