
APLIKASI SPEECH RECOGNITION BAHASA INDONESIA BERBASIS ANDROID
Saat ini, kemajuan teknologi sangatlah pesat dan berperan penting dalam kehidupan masyarakat. Dan kemajuan teknologi juga berpengaruh pada kemajuan teknologi mobile. Dan perangkat mobile pun telah menjadi kebutuhan yang sangat penting bagi kehidupan masyarakat sekarang dan banyak masyarakat yang menggunakan perangkat mobile phone. Perkembangan mobile sangat membantu masyarakat dalam melakukan komunikasi. Selain itu banyak aplikasi-aplikasi atau software yang diciptakan untuk menunjang kegunaan atau manfaat dari perangkat mobile tersebut. Sehingga kegunaan mobile akhir-akhir ini tidak hanya untuk komunikasi dan penyaji informasi saja, namun juga dapat memberikan hiburan bagi penggunanya.
Salah satu mobile phone yang sangat banyak digunakan di Indonesia adalah platform Android. Kecenderungan penduduk di Indonesia untuk menggunakan smartphone Android dikarenakan fitur-fitur yang tersedia dalam smartphone ini dapat memuaskan kebutuhan para konsumen. Salah satunya yang dapat diunggulkan dari smartphone ini adalah bersifat open source.
Aplikasi-aplikasi mobile saat ini banyak menggunakan kecerdasan buatan atau biasa disebut dengan Artificial Intelligence (AI). Sehingga dalam hal ini, akan diterapkan kecerdasan buatan speech recognition atau pengenalan pola suara untuk platform Android.
Aplikasi speech recognition (speech to text) sebenarnya sudah sering digunakan dalam mobile phone oleh platform Android, Apple, dan Blackberry. Perusahaan ternama seperti Google sangat cepat dalam mengembangkan aplikasi speech recognition yang bersifat online atau membutuhkan jaringan internet. Speech recognition yang berkembang pada saat ini kebanyakan menggunakan Bahasa Inggris.
Ada dua metode yang digunakan dalam perancangan dan pembuatan aplikasi speech recognition, yaitu :
- Metode Analisis
Pada metode analisis dilakukan studi pustaka, seperti membaca dari berbagai sumber di internet, buku-buku, dan jurnal-jurnal tentang definisi speech recognition untuk menunjang pembuatan aplikasi speech recognition ini. Ada beberapa hal yang dilakukan, yaitu :
- Metode Perancangan
Untuk perancangan sistem dari aplikasi Speech Recognition ini, penulis menggunakan metode Waterfall. Berikut ini adalah tahapan-tahapan dalam metode Waterfall, antara lain :
- menentukan spesifikasi sistem yang dibutuhkan dari keseluruhan sistem untuk mengaplikasikan program Speech Recognition
- pengumpulan dan peningkatan data-data yang berhubungan pada sistem dan berfokus pada karakteristik sistem yang akan dibuat.
- pembuatan model atau desain dari sistem. Pembuatan model ini meliputi : aliran data pada sistem sehingga sistem dapat menghasilkan output yang sesuai dengan input yang diberikan, dan desain tampilan user interface.
- pengkodean program dilakukan dengan menggunakan perangkat lunak Eclipse dengan library Pocketsphinx. Setelah itu dilakukan pengujian untuk mengetahui letak error atau kesalahan yang ada.
- pengembangan, dan penyebaran sistem kepada para user agar setiap sistem dapat berjalan dengan baik dan mencapai hasil yang lebih maksimal bagi para user saat menggunakan aplikasi ini.
Pengujian aplikasi dilakukan oleh penulis (2 orang) dan pengguna (50 orang). Hasil pengujian yang didapat adalah hasil keakuratan yang baik, dan dapat digunakan secara offline (tanpa menggunakan akses internet).
Berdasarkan hasil analisis kebutuhan user, terdapat beberapa kesimpulan yang dapat diambil: (1) sebagian besar responden menggunakan handphone selama lebih dari 6 jam dalam sehari. (2) Sebagian besar responden menggunakan handphone dengan platform Samsung (Android). (3) Didapat hasil fitur speech recognition paling sedikit digemari. (4) Sebagian besar responden belum merasa puas dengan fitur yang disediakan oleh handphone yang dimiliki. (5) Mayoritas responden sudah mengetahui yang dimaksud dengan sistem speech recognition. (6) Sebagian besar responden belum pernah menggunakan aplikasi speech recognition. (7) Sebagian besar responden menjawab bahwa fitur aplikasi speech recognition itu bermanfaat. (8) Sebagian besar responden menjawab ingin handphone mereka dilengkapi dengan fitur aplikasi speech recognition.
Ada beberapa hal yang perlu dilakukan untuk melakukan pelatihan atau training kata dengan metode HMM (Hidden Markov Model), yaitu sebagai berikut :
- Pengumpulan Data
Pengumpulan data awal dimana daftar kata dibuat dan setiap kata dipecah menjadi sub-sub kata. Sub-sub kata lalu dimasukkan kedalam daftar fonetik. Membuat daftar kalimat yang berisi kata-kata yang akan di training. Satu kalimat terdiri dari 8-10 kata yang dapat diulang. Dari daftar kalimat yang dibuat, dapat dibuat file language model yang berisi 1-gram, 2-gram, 3-gram, nilai likelihood dan faktor back-off. Selanjutnya dibuat file suara menggunakan format wav 16 bit 44.100 Hz mono sesuai dengan jumlah kalimat yang telah dibuat di daftar kalimat.
- Pelatihan Parameter (training)
Proses training dimulai dari pengecekan tiap kata dan sub kata yang berada di daftar kata dan daftar fonetik. Proses tidak dapat dilanjutkan apabila ditemukan ketidakcocokkan diantara kedua file tersebut.Proses selanjutnya adalah dimulainya proses HMM dimana proses ini melatih CI (context independent) model untuk sub kata yang ada di daftar fonetik. Dilanjutkan dengan melatih CD (context dependent) model sub kata dengan keadaan untied. Hasilnya adalah CD untied model yang dipakai untuk membuat decision tree.
Proses dilanjutkan dengan membuat decision tree untuk setiap state dari sub kata. Setelah decision tree dibuat, makan akan dilanjutkan dengan tree pruning ( membuang hal-hal yang tidak diperlukan) dari decision tree.
Proses terakhir yang dilakukan adalah melatih final model yang disebut CD tied model. Final model ini dilatih dengan berberapa tahapan yaitu 1 Gaussian per state HMM dilanjutkan dengan 2 Gaussian per state HMM dan diakhiri dengan 3 Gaussian per state HMM. Proses ini diakhiri dengan penghapusan interpolasi.
- Penyimpanan Parameter
Setelah proses training selesai dijalankan akan dihasilkan 8 file yaitu mdef, feat.params, mixture_weights, means, noisedict, transition_matrices, variances, dan senddump. Kedelapan file tersebut beserta daftar kata dan language model nantinya akan di push kedalam sistem yang digunakan untuk proses pengenalan suara dan dirubah menjadi text.
Berikut ini adalah gambar-gambar saat aplikasi speech recognition dijalankan :
- Tampilan splash screen
Tampilan awal layar saat baru masuk ke dalam aplikasi speech recognition.

- Tampilan layar input
Setelah tampilan splash screen, maka aplikasi masuk ke tampilan layar input.

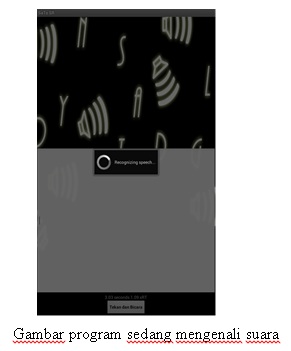
- Tampilan program sedang mengenali suara
Ketika user menekan tombol “Tekan dan Bicara” dan mengucapkan kata, maka sistem menerima input dan berusaha mengenali kata yang diucapkan.
- Tampilan layar setelah suara dikenali
Setelah mengenali kata yang diucapkan oleh user, maka sistem menampilkan hasil output berupa teks dari kata yang telah diucapkan oleh user.

Dan berdasarkan hasil evaluasi user, ternyata aplikasi ini sudah memenuhi syarat sesuai kebutuhan user seperti: (1) Sebagian besar responden menjawab sudah puas dengan fitur yang disediakan. (2) Sebagian besar responden menjawab bahwa tampilan atau user interface dari aplikasi speech recognition ini sudah memiliki GUI yang baik. (3) Seluruh responden menjawab bahwa aplikasi speech recognition ini mudah untuk digunakan. (4) Sebagian besar responden menjawab bahwa aplikasi speech recognition ini sudah akurat. (5) Sebagian besar responden menjawab sudah puas dengan keakuratan yang dimiliki oleh aplikasi speech recognition ini. (6) Sebagian besar responden menjawab bahwa aplikasi speech recognition ini dapat diimplementasikan dan membantu user untuk di masa yang akan datang.
REFERENSI
- Android Developer. (n.d.). Diperoleh 20 September 2012 dari Android Developers : https://developer.android.com/index.html.
- Carnegie Mellon University. Diperoleh 28 Agustus 2012 dari https://cmusphinx.sourceforge.net/2011/05/building-pocketsphinx-on-android/.
- Handel, R., V. (2008). Hidden Markov Models. Diperoleh 21 Maret 2013 dari https://www.princeton.edu/~rvan/orf557/hmm080728.pdf.
- Irawan. (2011). Java untuk Orang Awam. Palembang : Maxicom.
- Jurafsky, D., & Martin, J. H. (2009). Speech and Language Processing : An Introduction To Natural Language Processing, Computational Linguistics, Speech Recognition. 2nd Edition. Upper Saddle River, N. J. : Pearson Prentice Hall.
- Kusumadewi, S. (2003). Artificial Intelligence (Teknik dan Aplikasinya). Yogyakarta : Graha Ilmu.
- Mains, R. (2001). White Paper On Speech Recognition In The SESA Call Center. University of Maryland. Diperoleh 2 Oktober 2012 dari https://www.angelfire.com/poetry/shweta_ip/SRWhitepaper.pdf.
- Marietha, S., Purwarianti, A., & Lestari, D., P. (2012). SMSsuara Application with Automatic Speech Recognition and Text to Speech on Mobile Phone. Diperoleh 3 Oktober 2012 dari https://stei.itb.ac.id/jurnal/index.php/stei-S1/article/download/73/67.
- Patel, I., & Rao, Y., S. (2010). Speech Recognition Using HMM With MFCC – An Analysis Using Frequency Spectral Decomposition Technique. Diperoleh 3 Oktober 2012 dari https://airccse.org/journal/sipij/papers/1210sipij09.pdf.
- Pressman, R., S. (2010). Software Engineering A Practitioner’s Approach. 7th Edition. New York : The McGraw-Hill Companies, Inc.
- Ronando, E., & Irawan, M., I. (2012). Pengenalan Ucapan Kata sebagai Pengendali Gerakan Robot Lengan Secara Real-Time dengan Metode Linear Predictive Coding-Neuro Fuzzy. Diperoleh 3 Oktober 2012 dari https://ejurnal.its.ac.id/index.php/sains_seni/article/download/1011/278.
- Russel, S., J., & Norvig, P. (2010). Artificial Intelligence A Modern Approach. 3rd Edition. Upper Saddle River : Prentice Hall.
- Safaat H., N. (2011). Pemrograman Aplikasi Mobile Smartphone dan Tablet PC Berbasis Android. Bandung : Informatika.
- Satori, H., Hiyassat, H., Harti, M., & Chenfour, N. (2009). Investigation Arabic Speech Recognition Using CMU Sphinx System. Diperoleh 3 Oktober 2012 dari https://www.ccis2k.org/iajit/PDF/vol.6,no.2/11IASRUCSS186.pdf.
- Supardi, Y. (2011). Semua Bisa Menjadi Programmer Android Basic. Jakarta : Elex Media Komputindo.