
Mekanisme Ajaib di Balik ChatGPT: Memahami Model Transformer

Selamat datang di era teknologi di mana mesin dapat memahami, menjawab, dan bahkan berinteraksi dengan manusia melalui bahasa alami. Ya betul, namanya ChatGPT. ChatGPT adalah sebuah model AI yang dibangun oleh OpenAI dan adalah salah satu contoh luar biasa dari teknologi ini. Akan tetapi, dibalik kecanggihannya terdapat mekanisme kompleks yang dikenal sebagai model transformer. Artikel ini akan mengungkap bagaimana model Transformer bekerja, bagaimana model Transformer dapat membuat ChatGPT memahami konteks, dan mengapa model Transformer menjadi fondasi dari revolusi AI berbasis bahasa.
Apa Itu Model Transformer?

Model transformer pertama kali diperkenalkan oleh Vaswani et al. pada tahun 2017. Model transformer adalah arsitektur jaringan saraf yang dirancang khusus untuk mengatasi batasan-batasan dari model berbasis urutan sebelumnya, seperti Recurrent Neural Network (RNN) dan Long Short-Term Memory (LSTM). RNN dan LSTM bagus dalam mengenali urutan data, tetapi memiliki keterbatasan dalam menangani konteks yang sangat panjang. Model Transformer memperkenalkan mekanisme yang disebut self-attention, yang memungkinkan model ini menangkap konteks dari keseluruhan teks tanpa harus memproses kata satu per satu secara sekuensial.
1. Mekanisme Self-Attention: Menyulap Teks Menjadi Konteks
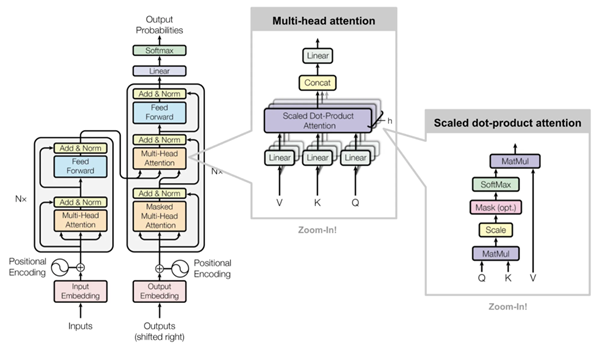
Source: Vaswani, 2017 via https://www.ionio.ai/
Mekanisme self-attention adalah kunci dari keajaiban model Transformer. Pada dasarnya, self-attention bekerja dengan menilai seberapa penting setiap kata dalam kalimat terhadap kata-kata lain. Dengan cara ini, model dapat memahami konteks dengan lebih baik dan menghasilkan respons yang lebih tepat. Misalnya, Ketika kalian meminta ChatGPT untuk “Tolong Jelaskan Materi Mengenai Machine Learning dan Deep Learning”. Model Transformer akan memberi bobot yang lebih besar terhadap kata “Materi”, “Machine Learning”, dan “Deep Learning” dari pada memberi perhatian penuh pada kata-kata yang kurang penting seperti “Tolong” atau “dan”. Dengan kata lain, self-attention memungkinkan model memahami konteks keseluruhan, alih-alih hanya menghafal urutan kata demi kata.
Secara teknis, self-attention beroperasi dengan mematakan setiap kata dalam kalimat menjadi vektor numerik, lalu menghitung bobot interaksi antar kata. Kombinasi nilai ini yang memungkinkan model untuk mengeteahui seberapa besar pengaruh setiap kata terhadap makna keseluruhan. Hal ini lah yang membuat model Transformer unggul dalam mengenali konteks dalam teks yang panjang.
2. Struktur Encoder-Decoder yang Mengagumkan
Model Transformer terdiri dari dua komponen utama, yaitu encode dan decoder.
- Encoder: Encoder adalah komponen yang memproses input data, seperti teks atau kalimat. Encoder bekerja dengan memecah teks menjadi bagian-bagian kecil, kemudian menggabungkan maknanya dengan mempertimbangkan konteks menggunakan self-attention.
- Decoder: Komponen ini bertugas menghasilkan teks berdasarkan pemahaman yang diperoleh dari encoder. Di dalam ChatGPT, decoder mengambil konteks yang diproses oleh encoder dan memberikan respon dengan hasil yang logis. Decoder berperan untuk membuat ChatGPT menghasilkan kalimat yang sesuai dengan konteks input pengguna.
Namun, perlu dicatat bahwa dalam model ChatGPT, arsitektur utamanya hanya terdiri dari komponen decoder. Ini dikarenakan ChatGPT adalah model yang dirancang untuk menghasilkan bahasa alami berdasarkan konteks, tanpa harus memproses pasangan input-output, seperti dalam tugas terjemahan.
3. Langkah-Langkah Pengolahan Teks pada ChatGPT
Berikut adalah langkah-langkah yang terjadi di balik layar ChatGPT:
- Tokenisasi: Teks yang dimasukkan oleh pengguna dibagi menjadi unit-unit kecil yang disebut token. Token ini bisa berupa kata, sebagian kata, atau karakter tunggal.
- Pemberian Bobot Melalui Self-Attention: Token-token tersebut kemudian diberikan bobot berdasarkan nilai kepentingannya pada konteks kalimat.
- Penyesuaian Melalui Layer Berlapis: Transformer bekerja dengan lapisan bertumpuk yang memungkinkan pemahaman konteks semakin dalam pada setiap lapisan.
- Penerjemahan Kembali Menjadi Teks: Setelah mendapatkan konteks dan pola yang relevan, ChatGPT menghasilkan respons dengan menerjemahkan representasi numerik kembali menjadi teks yang dapat dibaca manusia.
Kelebihan Model Transformer untuk ChatGPT
- Kecepatan Pemrosesan yang Tinggi: Transformer tidak bekerja dengan cara membaca teks secara urutan dan mengolah data dalam jumlah besar secara paralel sehingga model Transformer tidak perlu waktu lama dalam merespon input kalimat yang pengguna tuliskan,
- Kemampuan Memahami Konteks Panjang: Dengan adanya self – attention, model transformer dapat menangkap hubungan jangka panjang dalam teks.
- Fleksibilitas Pengguna: Model Transformer dapat digunakan untuk berbagai tugas, mulai dari terjemahan bahasa, analisis sentimen, hingga pembuatan teks kreatif. Menjadikan model Transformer adalah salah satu model yang multifungsi.
- Masa Depan Teknologi Bahasa dengan Model Transformer
Model Transformer adalah salah satu kemajuan terbesar dalam pemrosesan bahasa alami. Kemampuannya dalam mengolah data teks secara efisien dan dengan konteks yang mendalam telah membuka pintu bagi aplikasi AI yang lain, seperti Virtual Assistant dan Language Translator. Dalam beberapa tahun ke depan, kita mungkin akan melihat model Transformer yang lebih canggih, mampu menangani lebih banyak bahasa dan bahkan memahami emosi atau niat pengguna.
Penulis: Satriadi Putra Santika, S.Kom.
FDP Scholar
Referensi:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv:1706.03762. https://arxiv.org/abs/1706.03762.
AWS. (2024). Apa itu transformer dalam kecerdasan buatan?. Apa itu transformer dalam kecerdasan buatan?. https://aws.amazon.com/id/what-is/transformers-in-artificial-intelligence/. Diakses 30 Oktober 2024.
IBM. (2023). Apa yang dimaksud dengan model Transformer?. https://www.ibm.com/id-id/topics/transformer-model. Diakses 30 Oktober 2024.
OpenAI. (2024). Overview OpenAI Documentation. https://platform.openai.com/docs/overview. Diakses 30 Oktober 2024.
Laraswati, Bunga. (2023). Transformer dalam Machine Learning: Model Dibalik GPT, BERT, dan T5. https://blog.algorit.ma/transformer-machine-learning/. Diakses 30 Oktober 2024.