
Mamba: Arsitektur Model Sekuensial Yang Siap Menyaingi Transformer

Pada beberapa tahun terakhir, Transformer telah menjadi fondasi dari hampir seluruh kemajuan besar di bidang artificial intelligence, terutama dalam Natural Language Processing (NLP), computer vision, dan bahkan computational biology. Namun, seiring semakin besarnya model yang dibangun di atas arsitektur Transformer, tantangan komputasi yang timbul juga makin nyata, yaitu proses pelatihan dan inferensi yang memakan waktu, mahal secara komputasi, dan tidak efisien saat dihadapkan pada urutan data yang sangat panjang. Masalah ini menjadi alasan mengapa munculnya model Mamba pada akhir 2023 begitu mengguncang komunitas riset. Mamba bukan hanya model baru, model ini merupakan arsitektur dengan pendekatan yang sangat berbeda. Tidak seperti Transformer yang bergantung pada self-attention untuk memproses data secara paralel dalam satu konteks, Mamba didasarkan pada struktur yang dikenal sebagai Selective State Space Model (SSSM) (Gu & Dao, 2023). Konsep ini memungkinkan model untuk tetap mempertahankan efisiensi linear-time dalam memproses urutan panjang, tanpa harus membandingkan setiap elemen dalam urutan seperti yang dilakukan oleh attention mechanism dalam arsitektur Transformer.
Keunikan utama Mamba terletak pada kemampuannya untuk memilih informasi secara kontekstual, seperti apakah token tertentu layak disimpan dalam memori atau diabaikan. Fitur ini disebut sebagai selection mechanism, di mana parameter-parameter inti model (seperti Δ, B, dan C) bergantung pada isi dari input itu sendiri. Dengan kata lain, Mamba bisa “memilih” bagian penting dari input dan melupakan bagian yang tidak relevan, suatu hal yang selama ini hanya bisa dilakukan oleh model dengan memori eksplisit seperti Transformer (Grootendorst, 2024). Hal yang membuat Mamba begitu menarik adalah efisiensinya karena tidak perlu menyimpan konteks sebelumnya dalam cache seperti halnya Transformer, Mamba dapat melakukan inferensi secara jauh lebih cepat. Pada pengujian pada language modelling, Mamba 3B bahkan mampu menyamai performa Transformer 7B, dalam berbagai tugas zero-shot seperti LAMBADA, ARC, dan HellaSwag (Gu & Dao, 2023). Di sisi lain, kecepatan menghasilkan teks (generation throughput) mencapai lima kali lebih tinggi, menjadikannya jauh lebih hemat dalam penggunaan sumber daya komputasi.
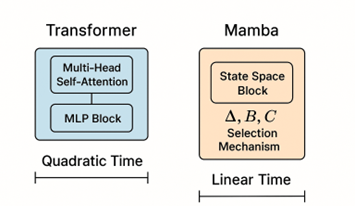
Akan tetapi, seperti banyak inovasi yang muncul tiba-tiba dan menyajikan klaim besar, Mamba juga menuai kontroversi. Beberapa peneliti mempertanyakan keabsahan benchmarking yang dilakukan, terutama karena hasilnya tampak “terlalu baik untuk menjadi kenyataan”. Misalnya, saat diuji pada dataset The Pile yang berisi teks panjang dan kompleks, Mamba tidak hanya mampu menyamai performa Transformer, tetapi juga menunjukkan hasil yang lebih baik dalam memahami dan memprediksi isi teks. Namun, hasil tersebut belum banyak direplikasi secara independen oleh tim riset lain sehingga diskusi di kalangan komunitas riset masih terus berlanjut. Menariknya, arsitektur Mamba juga relatif sederhana dibandingkan Transformer. Jika Transformer terdiri dari blok-blok multi-head attention dan MLP, maka Mamba cukup menyatukan fungsi linear dan state-space ke dalam satu blok homogen (Gade, 2024). Hal ini memberikan keuntungan dalam hal kesederhanaan implementasi dan kemudahan dalam pengoptimalan di perangkat keras modern, termasuk GPU dan edge device. Tak hanya unggul di bidang bahasa, Mamba juga menunjukkan performa kompetitif dalam domain lain seperti genomik dan audio. Pada pemodelan sekuens DNA yang memerlukan pemrosesan konteks hingga jutaan token, Mamba tetap stabil dan akurat. Bahkan untuk data audio seperti musik dan speech, Mamba mampu mengalahkan model generatif seperti DiffWave dan SaShiMi dalam metrik kualitas suara (Gu & Dao, 2023).

Meski begitu, tentu masih ada banyak pertanyaan yang belum terjawab seperti apakah Mamba bisa di-scale ke ukuran sebesar GPT-4 atau LLaMA 3? Apakah Mamba dapat mengakomodasi teknik adaptasi lanjutan seperti in-context learning, fine-tuning, atau RLHF yang telah matang di ekosistem Transformer? Penulis aslinya pun menyatakan bahwa mereka masih mengeksplorasi hal ini. Namun satu hal yang pasti, Mamba telah membuka jalan baru dalam riset arsitektur sekuensial. Model ini membuktikan bahwa performa tinggi tidak harus dibayar dengan mahalnya komputasi. Dengan tetap menjaga efisiensi dan kesederhanaan, Mamba menantang status quo yang telah lama dipegang oleh Transformer. Apakah ini pertanda era baru bagi model sekuensial? Bagaimana menurut mu?
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Gade, P. (2024). Mamba Architecture: A Leap Forward in Sequence Modeling. Medium. https://medium.com/@puneetthegde22/mamba-architecture-a-leap-forward-in-sequence-modeling-370dfcbfe44a. Di akses 25 Mei 2025.
Grootendorst, M. (2024). A Visual Guide to Mamba and State Space Models. https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state. Di akses 25 Mei 2025.
Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint arXiv:2312.00752. https://arxiv.org/abs/2312.00752
Zilliz. (2024). Mamba Architecture: A Potential Transformer Replacement? https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement. Di akses 25 Mei 2025.