
AI Bersuara, Fakta Terkaburkan: Membedah Halusinasi dalam Large Language Modelling
 Source: analyticsvidya.com (2024)
Source: analyticsvidya.com (2024)
Pada beberapa tahun terakhir, dunia menyaksikan kemunculan sistem AI yang bisa “berbicara” dengan lancar, menjawab berbagai pertanyaan, menulis puisi, bahkan membantu menulis kode. Semua tugas tersebut dapat dilakukan oleh Large Language Models (LLM) seperti ChatGPT, Claude, LLaMA, atau Gemini. Model-model ini dilatih dengan miliaran kata dari internet dan mampu menghasilkan teks yang sangat meyakinkan, terstruktur rapi, gramatikal, dan terlihat cerdas. Namun di balik kehebatannya, LLM menyimpan satu kelemahan mendasar, yaitu mereka bisa dengan sangat fasih menyampaikan informasi yang salah. Fenomena ini disebut sebagai “hallucination“, yakni ketika AI mengarang informasi yang tidak pernah diajarkan atau tidak benar, tetapi tetap menyampaikannya seolah itu fakta karena kemasannya begitu mulus, banyak orang sulit membedakan antara jawaban valid dan halusinasi meyakinkan ini. Masalah ini tidak hanya terdapat pada bidang akademik, tetapi potensi penyalahgunaan LLM untuk menyebarkan disinformasi, propaganda, bahkan manipulasi sosial dan politik kini menjadi perhatian global.
Pada literatur NLP, “hallucination” merujuk pada keluaran teks dari model AI yang tidak didasarkan pada data latih atau fakta yang valid. Menurut Ji et al. (2023), halusinasi dalam LLM dibagi menjadi dua:
- Intrinsic hallucination: AI menghasilkan kalimat yang secara logika bertentangan dengan input atau instruksi.
- Extrinsic hallucination: AI memberikan informasi tambahan yang terdengar benar, tetapi sebenarnya tidak berbasis pada data manapun.
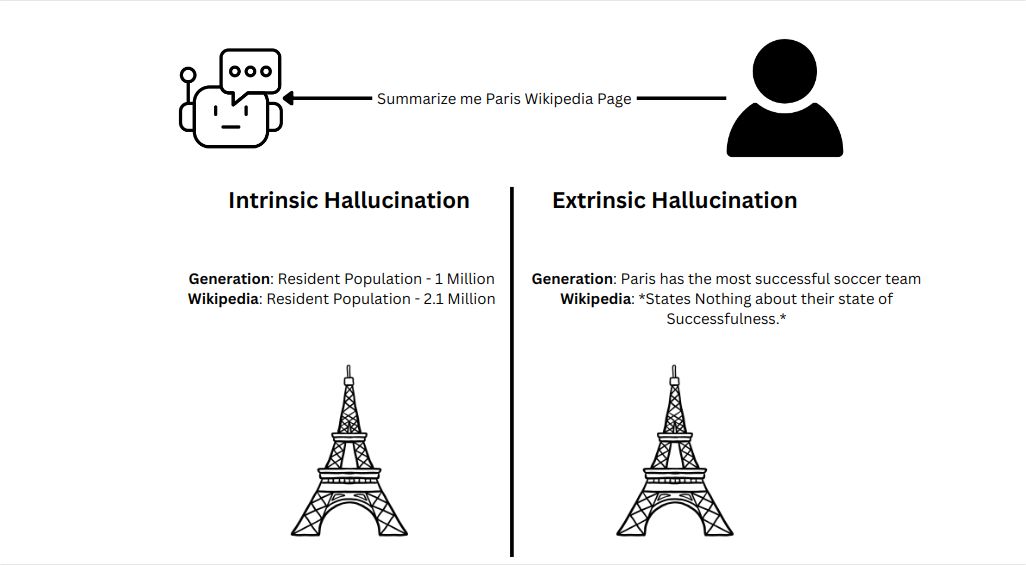
Source: Sharma (2024)
Meskipun terdengar meyakinkan, sebenarnya jawabannya tidak benar. Hal ini yang dinamakan sebagai hallucination. Hallucination tidak mengartikan model “berbohong”, tetapi karena model tidak benar-benar “mengerti” apa yang ia katakan.
Mengapa Halusinasi Ini Bisa Terjadi?
Halusinasi bukanlah bug, melainkan konsekuensi dari cara LLM bekerja. Model ini tidak menyimpan database fakta, melainkan menghitung probabilitas kata berdasarkan konteks sebelumnya. Beberapa penyebab utamanya adalah sebagai berikut:
- LLM belajar dari data tak terstruktur di internet, yang bisa mengandung kesalahan, hoaks, atau pendapat bias.
- Model dirancang untuk “menyelesaikan kalimat”, bukan “mengecek kebenaran”. Tujuan utamanya adalah fluency, bukan factual accuracy (Bender et al., 2021).
- Tidak ada mekanisme internal untuk verifikasi fakta atau penalaran berbasis logika formal, kecuali dipasangkan dengan retrieval-based systems.
Potensi Penyalahgunaan dalam Disinformasi
Ketika ”hallucination” terjadi di sinilah masalah menjadi serius. Kemampuan LLM untuk menghasilkan teks berkualitas tinggi dalam jumlah besar dan waktu singkat membuka pintu bagi berbagai bentuk penyalahgunaan:
1. Pabrik Konten Hoaks dan Spam Otomatis
Aktor jahat dapat menggunakan LLM untuk membuat ribuan artikel palsu, komentar politik, atau ulasan palsu yang tampak natural. OpenAI sendiri telah menyatakan bahwa LLM bisa digunakan untuk “influence operations” (OpenAI, 2023).
2. Manipulasi Politik dan Kampanye Gelap
LLM dapat dengan mudah digunakan untuk membuat narasi politik palsu atau meniru gaya bicara tokoh tertentu untuk menyebarkan pesan yang salah.
3. Scam dan Phishing yang Lebih Meyakinkan
E-mail penipuan atau manipulasi sosial yang dulu terbatas oleh grammar yang buruk kini bisa dibuat dengan sangat baik berkat kemampuan generatif LLM.
4. Deepfake Teks dan Palsukan Sumber
LLM bisa “menciptakan kutipan” dari tokoh terkenal yang terdengar otentik, tetapi tidak pernah diucapkan. Hal ini berbahaya untuk dunia jurnalistik dan hukum.
5. Meracuni Sistem Pencarian Modern
Search engine kini tidak hanya mengambil informasi dari web, tetapi juga menghasilkan jawaban yang tampak benar padahal sebenarnya salah atau tidak terverifikasi. Hal ini menimbulkan kekhawatiran bahwa pencarian online bukan lagi tempat mencari kebenaran, tetapi telah menjadi arena baru bagi disinformasi otomatis (IEEE Spectrum, 2023).
Upaya Mengatasi dan Tantangan Etika
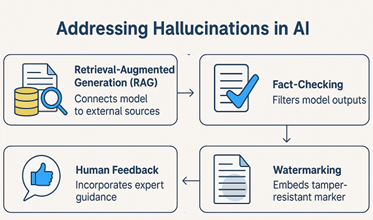
Seiring semakin meluasnya penggunaan LLM dalam kehidupan sehari-hari, kekhawatiran terhadap dampak negatif dari halusinasi AI pun semakin mengemuka. Model yang mampu menghasilkan teks dengan gaya meyakinkan, tetapi tidak selalu akurat menimbulkan tantangan besar baik dari sisi teknis maupun etika. Di satu sisi, kita ingin memanfaatkan kecanggihan LLM untuk produktivitas dan kreativitas, tetapi di sisi lain kita juga harus memastikan bahwa informasi yang dihasilkan tidak menyesatkan atau dimanipulasi. Oleh karena itu, berbagai pendekatan telah dikembangkan untuk mengurangi risiko halusinasi, sekaligus menjawab pertanyaan lebih besar tentang tanggung jawab, transparansi, dan keandalan dalam penggunaan sistem AI generatif.
- Retrieval-Augmented Generation (RAG): LLM disambungkan ke database atau search engine eksternal yang valid untuk memastikan model hanya menghasilkan jawaban yang bersumber dari dokumen nyata dan dapat diverifikasi.
- Fact-checking post-processing: Sistem terpisah digunakan untuk mengevaluasi kembali hasil keluaran model, menyaring pernyataan yang tidak didukung fakta, serta memberikan peringatan atau koreksi jika perlu.
- Training dengan feedback manusia: Teknik Reinforcement Learning from Human Feedback (RLHF) memungkinkan model belajar membedakan jawaban yang akurat dan aman dari yang keliru atau menyesatkan, berdasarkan preferensi manusia (Ouyang et al., 2022).
- Watermarking Teknologi penandaan tersembunyi pada teks buatan AI untuk membantu deteksi, pelacakan, dan mitigasi penyebaran konten generatif yang berpotensi digunakan untuk manipulasi.
LLM telah membuka era baru komunikasi antara manusia dan mesin. Akan tetapi, di balik kemampuannya yang luar biasa, tersembunyi risiko besar yaitu model yang sangat meyakinkan belum tentu sepenuhnya benar atau valid. Dalam dunia di mana informasi adalah kekuatan, AI yang menghaluskan kebohongan bisa jauh lebih berbahaya dari AI yang keliru terang-terangan. Oleh karena itu, penting bagi kita baik peneliti, pengembang, pembuat kebijakan, maupun pengguna umum untuk memahami keterbatasan AI dan membangun ekosistem yang bertanggung jawab dan tahan terhadap penyalahgunaan. Jika AI bisa berbohong dengan fasih, siapa yang akan kita percaya saat kebenaran dipertaruhkan?
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. Proceedings of FAccT ’21. https://dl.acm.org/doi/10.1145/3442188.3445922.
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., … & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys (CSUR). https://arxiv.org/abs/2303.01157.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Christiano, P. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155. https://arxiv.org/abs/2203.02155.
OpenAI. (2024). Disrupting a covert Iranian influence operation. https://openai.com/index/disrupting-a-covert-iranian-influence-operation/. Di akses 25 Mei 2025.
Smith, C. S. (2023). AI Hallucinations Are Poisoning Web Search. https://spectrum.ieee.org/ai-hallucination. Di akses 25 Mei 2025.
Sharma, A. (2024). Decoding LLM Hallucinations: A Deep Dive into Language Model Errors. https://zilliz.com/blog/decoding-llm-hallucinations-deep-dive-into-llm-errors. Di akses 25 Mei 2025.