
AI Security 101: Ancaman dan Pertahanan dalam Sistem Artificial Intelligence

Artificial Intelligence (AI) telah berkembang pesat dan kini digunakan dalam berbagai sektor, mulai dari keuangan, kesehatan, hingga hiburan. Akan tetapi, kemajuan ini membawa tantangan baru dalam aspek keamanan. AI tidak lagi sekadar alat pasif, tetapi telah menjadi sistem yang mampu mengambil keputusan, memproses informasi sensitif, bahkan berinteraksi dengan dunia nyata melalui agen. Oleh karena itu, pendekatan keamanan tradisional sering kali tidak memadai dalam menghadapi kerentanan yang dimiliki sistem AI modern.
Perbedaan utama terletak pada sifat AI yang kompleks, tidak dapat diprediksi, dan sangat tergantung pada data yang dikonsumsi. Sistem AI seperti model generatif dan agen berbasis Large Language Models (LLMs) memiliki permukaan serangan yang lebih luas, kemampuan emergen yang tidak dirancang secara eksplisit, serta nilai ekonomi yang tinggi sehingga menarik perhatian penyerang (Zhu et al., 2024). Hal ini menjadikan perlunya sistem keamanan khusus yang disesuaikan dengan dinamika dan arsitektur AI modern.
Apa itu AI Security?
AI Security adalah cabang dari keamanan cyber yang berfokus pada perlindungan sistem AI dari berbagai bentuk ancaman, baik yang berasal dari serangan eksternal maupun dari kesalahan internal. Hal ini mencakup aspek confidentiality (kerahasiaan), integrity (integritas), dan availability (ketersediaan), dengan pendekatan yang lebih adaptif terhadap karakteristik unik sistem AI. Tidak seperti keamanan sistem tradisional yang dapat mengandalkan sandboxing, patching, atau firewall, sistem AI harus menghadapi serangan seperti data poisoning, adversarial examples, dan prompt injection, yang sangat kontekstual dan dinamis. Oleh karena itu, AI Security tidak hanya mencakup proteksi teknis, tetapi juga mencakup desain arsitektur yang aman, pengawasan akses model, hingga pengelolaan data dan sesi pengguna secara aman.
Di samping menjaga sistem dari eksploitasi langsung, AI Security juga menekankan pentingnya menjaga kepercayaan pengguna dan kepatuhan terhadap regulasi. Pada banyak kasus, sistem AI memproses informasi pribadi, membuat keputusan yang berdampak sosial, atau berinteraksi dengan infrastruktur penting seperti layanan keuangan dan kesehatan. Oleh karena itu, AI Security juga mencakup prinsip transparansi, auditability, dan fairness agar sistem tidak hanya aman dari sisi teknis, tetapi juga dapat dipercaya secara etis dan legal di mata publik dan regulator.
Jenis Ancaman dalam AI Security
Ancaman terhadap keamanan sistem AI tidak terbatas pada manipulasi teknis semata, tetapi juga mencakup risiko sistemik yang berdampak luas terhadap data, privasi, dan regulasi. Pada konteks AI modern, terdapat enam ancaman utama yang perlu diperhatikan secara serius, yaitu data poisoning, model theft, adversarial attacks, privacy breaches, compliance violations, dan generative AI misuse. Berikut adalah penjelasan dari masing-masing ancaman.

Source: Robb (2025) via BlackFog
1. Data Poisoning
Data poisoning terjadi ketika training dataset disusupi dengan data manipulatif yang tampak valid. Saat model dilatih, pola berbahaya ini diserap sehingga logika model pun terdistorsi dan dapat menimbulkan backdoor yang aktif pada input tertentu (He et al., 2024). Data poisoning menjadi sangat kritikal ketika model diterapkan di konteks diagnostik medis atau sistem keuangan, di mana kesalahan logika dapat memicu konsekuensi besar.
2. Model Theft
Model theft terjadi saat penyerang meniru perilaku model AI (model extraction) hanya lewat query input-output, tanpa mengetahui parameter internalnya. Strategi ini memungkinkan pembuatan model tiruan tanpa izin atau lisensi (He et al., 2024). Aktivitas seperti ini semakin umum terjadi pada LLMs atau platform prediksi publik yang rendah keamanan API sehingga menyebabkan risiko hilangnya kekayaan intelektual dan potensi penyalahgunaan teknologi.
3. Adversarial Attacks
Input yang disiapkan secara adversarial bisa memanipulasi model AI agar salah klasifikasi. Misalnya, gambar digit “6” yang terlihat sama bagi manusia tapi dikenali sebagai “0” oleh model AI. Hal ini sering digunakan dalam serangan pada sistem pengenalan visual (Zhu et al., 2024). Adversarial attacks sering memanfaatkan batasan toleransi model, menjadikannya ancaman serius pada sistem keamanan seperti face recognition, autonomous vehicles, atau sistem fidelity tinggi lainnya.
4. Privacy Breaches
Sistem AI yang dilatih menggunakan data sensitif sangat rentan terhadap pelanggaran privasi, terutama jika tidak dilindungi dengan teknik seperti differential privacy. Pada beberapa kasus, model dapat “mengulang” kembali data pelatihan secara tidak sengaja melalui prediksi output-nya. Hal ini memungkinkan informasi pribadi, seperti nama, alamat, atau nomor kartu, terekspos ke pengguna lain sehingga menciptakan risiko hukum dan reputasi.
5. Compliance Violations
Banyak model AI, terutama yang dikembangkan secara cepat dan open-source, tidak memperhatikan aspek kepatuhan terhadap regulasi seperti GDPR, HIPAA, atau undang-undang perlindungan data lainnya. Ketika AI digunakan dalam konteks yang menyangkut data pengguna, risiko pelanggaran hukum menjadi sangat nyata. Model yang gagal menghapus data pengguna sesuai permintaan, atau tidak memberi transparansi atas bagaimana keputusan dibuat, dapat memicu sanksi hukum serius.
6. Generative AI Misuse
Model generatif seperti LLM atau image generators dapat disalahgunakan untuk membuat konten palsu, deepfake, spam, atau bahkan kode berbahaya. Potensi untuk manipulasi sosial dan penipuan digital meningkat drastis karena model ini mampu menghasilkan teks dan media yang sangat realistis. Tanpa pembatasan dan kontrol yang ketat, generative AI bisa menjadi alat penyebar disinformasi berskala besar.
Studi Kasus pada AI Security
Kasus kebocoran data pada agen AI korporat menunjukkan bahwa bahkan sistem yang dirancang untuk efisiensi internal pun bisa menjadi celah serius bagi keamanan informasi. Salah satu contoh yang sering dikutip adalah insiden di mana chatbot internal perusahaan seperti Samsung secara tidak sengaja membocorkan kode sumber internal saat berinteraksi dengan karyawan. Hal ini terjadi karena model AI tidak dirancang untuk membedakan konteks internal dan eksternal secara eksplisit sehingga informasi sensitif dapat diproses dan direproduksi tanpa filter keamanan yang memadai. Fenomena ini dikenal sebagai inference leakage, yaitu kondisi di mana sistem AI membocorkan potongan data pelatihan atau dokumen internal saat merespons pertanyaan pengguna (He et al., 2024).
Lebih jauh lagi, hasil uji penetrasi terhadap agen AI otonom memperlihatkan bahwa lebih dari 80% eksperimen memungkinkan agen tersebut mengeksekusi perintah shell berbahaya, seperti menghapus file, mengakses sistem file host, atau menjalankan proses ilegal. Hal ini menunjukkan bahwa tanpa adanya batasan eksplisit, AI dapat bertindak di luar ruang lingkup yang diinginkan pengembang, memicu gangguan operasional atau bahkan eskalasi serangan. Kelemahan ini umumnya muncul karena model terlalu terbuka dalam menerima dan mengeksekusi instruksi, serta minimnya integrasi sistem moderasi atau sandboxing di layer implementasi. Oleh karena itu, penting bagi organisasi untuk memperlakukan agen AI seperti sistem produksi berisiko tinggi yang memerlukan kontrol akses, logging ketat, dan audit keamanan berkala.
Strategi Pertanahan AI Security
Seiring meningkatnya kompleksitas sistem AI dan ancaman yang menyertainya, pendekatan keamanan tidak lagi bisa bersifat reaktif atau satu lapis. Dibutuhkan strategi pertahanan yang komprehensif, berlapis, dan terintegrasi dengan seluruh siklus hidup AI, mulai dari pengumpulan data, pelatihan model, hingga implementasi dan interaksinya dengan pengguna. Pendekatan ini tidak hanya bertujuan untuk mencegah serangan, tetapi juga mendeteksi anomali, merespons insiden dengan cepat, dan menjaga keandalan serta kepercayaan terhadap sistem AI.
1. Verifikasi Data
Menjaga kualitas dan keaslian data training adalah langkah pertama dalam melindungi model. Teknik seperti data sanitization dan deteksi outlier membantu mendeteksi poisoning sebelum model dilatih (Zhu et al., 2024). Selain itu, audit metadata training dataset secara berkala dapat menambah lapisan keamanan dalam pipeline AI.
2. Robust Training
Pendekatan seperti adversarial training, differential privacy, dan fine-tuning khusus dapat meningkatkan daya tahan model terhadap input jahat (Zhu et al., 2024). Melatih ulang model menggunakan sintesis data yang terkontrol juga membantu mengurangi kemungkinan inferensi leakage dan backdoor.
3. Secure Deployment
Menjalankan model dalam lingkungan yang terenkripsi seperti Trusted Execution Environments, mengisolasi akses API, dan menerapkan prinsip least privilege penting untuk menjaga integritas model saat digunakan (He et al., 2024). Selain itu, menggunakan AI Firewall, sistem moderasi input-output real-time, membantu menangkal prompt injection dan jangkauan query tidak wajar (Badman & Kosinski, 2025).
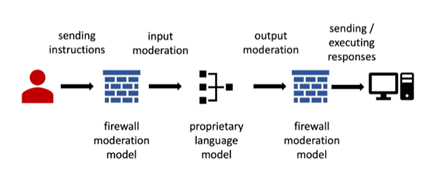
Source: Zhu et al. (2024)
4. Monitoring
Pemantauan dinamis terhadap perilaku input dan output model dilakukan melalui analisis anomaly berbasis ML. Hal ini memungkinkan deteksi dini terhadap serangan seperti model theft atau adversarial activity (Palo Alto Networks, 2024). Selain itu, threat intelligence system seperti yang dikembangkan oleh Vectra AI mengidentifikasi pola perilaku yang tidak normal dalam traffic API dan infrastruktur AI (Vectra AI, 2025).
Tantangan dan Masa Depan AI Security
Meskipun banyak strategi teknis telah dikembangkan, AI Security tetap menghadapi tantangan besar, seperti evolusi ancaman yang cepat, kurangnya standar global, dan perbedaan yurisdiksi hukum yang kompleks (He et al., 2024). Hanya sedikit organisasi yang telah mengintegrasikan tata kelola AI yang robust dalam development lifecycle. Di masa depan, kebutuhan akan AI governance yang mengatur audit trail, fairness, dan transparansi menjadi kritikal, IBM menyarankan integrasi pengawasan manusia dan sistem otomasi kebijakan (Badman & Kosinski, 2025). Regulasi, kolaborasi lintas industri, dan standarisasi teknis juga menjadi komponen vital dalam ekosistem AI Security yang berkelanjutan.
Kesimpulan
AI Security bukan hanya persoalan teknis, melainkan landasan utama bagi kepercayaan publik dan legitimasi penerapan AI dalam kehidupan sehari-hari. Sistem AI yang aman tidak cukup hanya dengan perlindungan model atau sandboxing sederhana, tetapi memerlukan pendekatan menyeluruh yang mencakup seluruh rantai proses, mulai dari pengumpulan dan validasi data, pelatihan model yang tahan gangguan, penerapan sistem deployment yang terisolasi dan diawasi, hingga tata kelola yang transparan dan dapat diaudit. Keamanan tidak bisa menjadi pelengkap, ia harus menjadi elemen inti dalam perancangan dan pengelolaan AI modern.
Di tengah lanskap ancaman yang terus berevolusi, seperti data poisoning, model theft, adversarial attacks, dan prompt manipulation, organisasi dituntut untuk lebih adaptif dan kolaboratif. Pengamanan AI yang efektif memerlukan sinergi antara inovasi teknis (AI firewall, watermarking, dan robust training) dengan kebijakan internal yang kuat serta kepatuhan terhadap regulasi yang berkembang. Melalui kombinasi tersebut, sistem AI dapat dijalankan secara aman, etis, dan berkelanjutan, memberikan manfaat maksimal bagi pengguna, tanpa mengorbankan keamanan, privasi, maupun kepercayaan publik.
Penulis
Satriadi Putra Santika
FDP Scholar
Daftar Pustaka
Badman, A., & Kosinski, M. (2025). What is AI security?. IBM. https://www.ibm.com/think/topics/ai-security. Di akses 28 Juli 2025.
He, Y., Wang, E., Rong, Y., Cheng, Z., & Chen, H. (2024). Security of AI Agents. Arxiv:Preprints 2406.08689v3.
PaloAlto. (2024). What Is AI Security?. Palo Alto Security. https://www.paloaltonetworks.com/cyberpedia/ai-security. Di akses 28 Juli 2025.
Robb, B. (2025). Key AI Data Security Strategies to Protect Your Organization. BlackFog. https://www.blackfog.com/key-ai-data-security-strategies-to-protect-your-organization/. Di akses 28 Juli 2025.
Vectra. (2025). Understanding AI Security: Definition and Explanation. Vectra AI. https://www.vectra.ai/learning/ai-security. Di akses 28 Juli 2025.
Zhu, B., Mu, N., Jiao, J., & Wagner, D. (2024). Generative AI Security: Challenges and Countermeasures. Arxiv:Preprint 2402.12617v2.