
Mengapa EmbeddingGemma Merupakan Terobosan dalam Teknologi Embedding Multibahasa Terbaik Sejauh Ini

Fig 1. Tampilan EmbeddingGemma (Choi et al | Google Developers 2025)
Dalam era kecerdasan buatan (AI) modern, embeddings menjadi fondasi penting untuk memahami bahasa alami. Embeddings memungkinkan sistem AI mengubah teks menjadi representasi numerik yang dapat diproses oleh mesin. Representasi ini tidak hanya sekadar angka, melainkan peta semantik yang memungkinkan komputer mengenali makna, hubungan, serta konteks antar kata dan kalimat. Teknologi ini digunakan di banyak bidang: retrieval augmented generation (RAG), mesin pencari semantik, sistem rekomendasi, hingga chatbot interaktif.
Namun, tantangan besar masih ada. Sebagian besar model embedding populer memiliki ukuran yang besar, memerlukan sumber daya komputasi yang signifikan, dan tidak selalu mendukung multibahasa dengan baik. Hal ini membatasi penerapan AI terutama di perangkat lokal atau edge devices. Di titik inilah Google memperkenalkan EmbeddingGemma, sebuah model embedding multibahasa yang diklaim ringan, efisien, dan tetap berkinerja tinggi.
Apa Itu EmbeddingGemma?
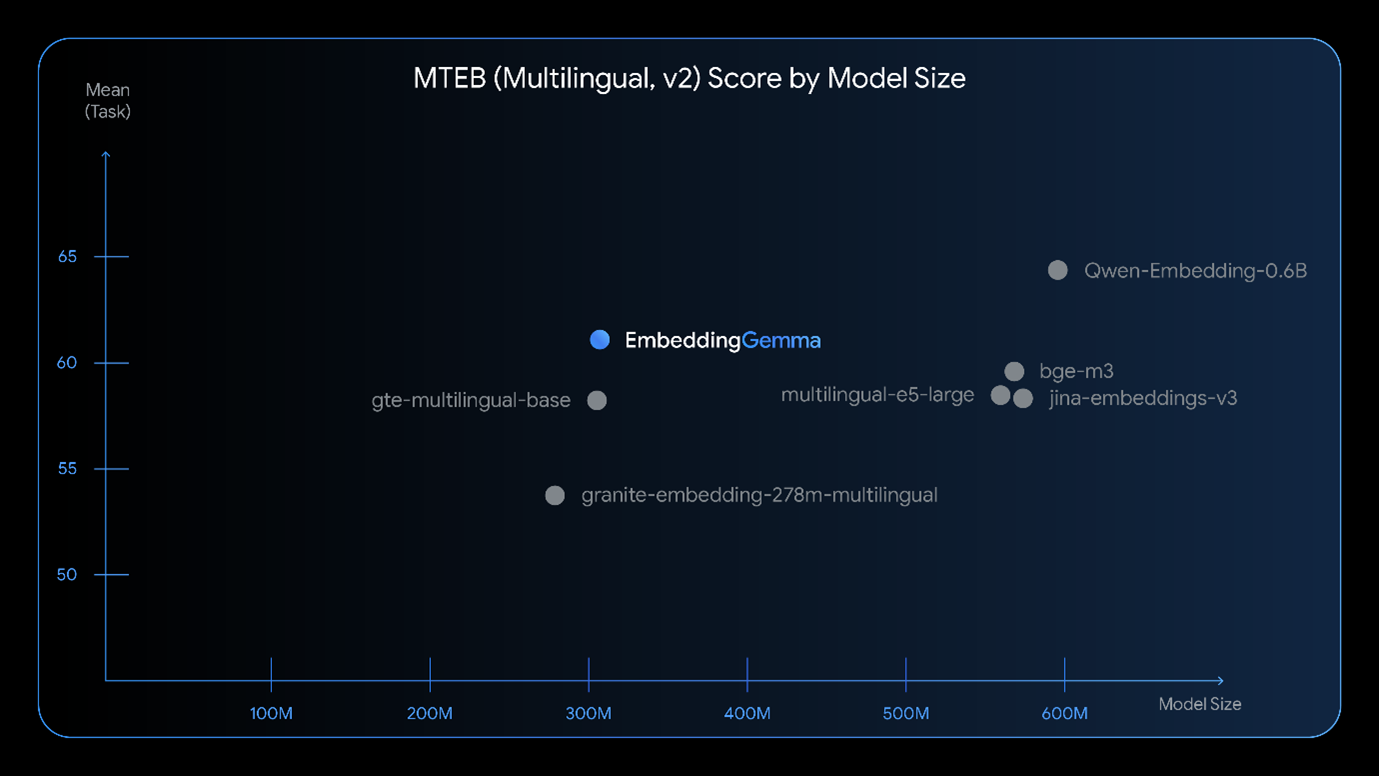
Fig 2. Komparasi EmbeddingGemma dengan model pupuler dengan ukuran yang lebih besar (Choi et al | Google Developers 2025)
EmbeddingGemma merupakan model text embedding dari keluarga Gemma, yang dikembangkan oleh Google DeepMind. Berbeda dengan model bahasa besar (LLM) generatif, EmbeddingGemma dirancang khusus sebagai encoder yang menghasilkan representasi vektor teks berkualitas tinggi. Dengan ukuran relatif kecil sekitar 256 juta parameter model ini bisa dijalankan di perangkat dengan sumber daya terbatas. Meski kecil, performanya tidak kalah dengan embedding kelas atas yang berukuran lebih besar. Google menekankan bahwa EmbeddingGemma dapat bekerja secara lokal tanpa harus bergantung pada layanan cloud, sehingga menjaga privasi data pengguna.
Keunggulan EmbeddingGemma
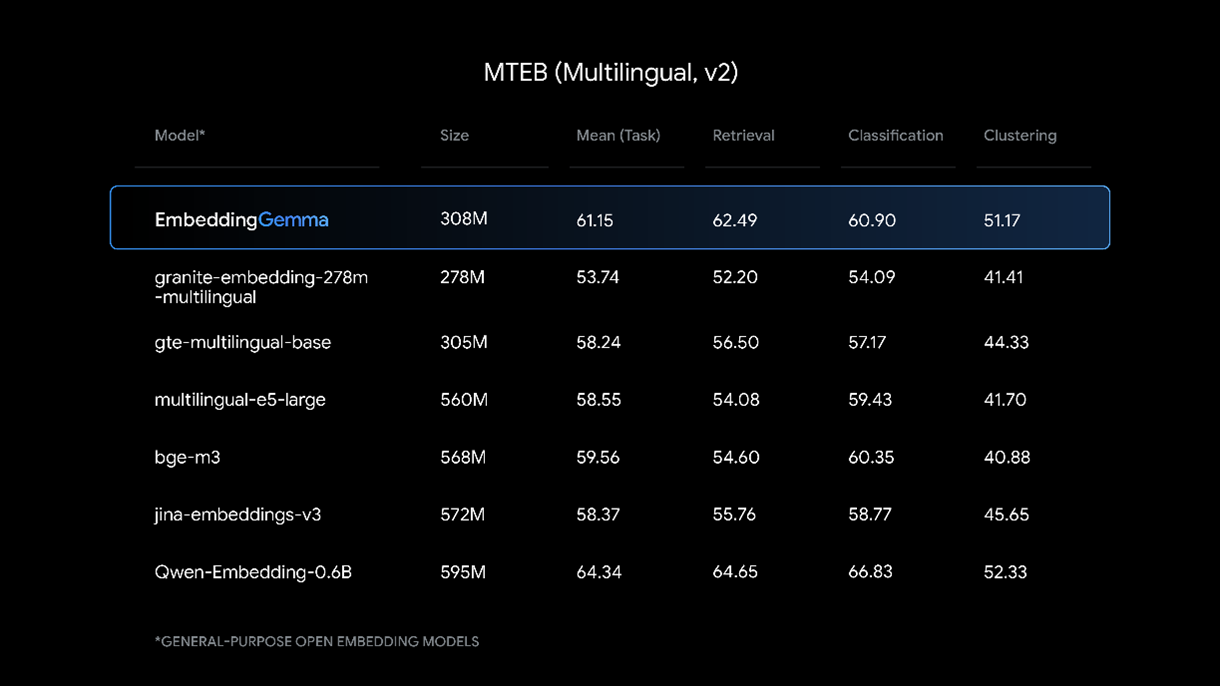
Fig 3. EmbeddingGemma dengan ukuran 308M: Unggul untuk Pencarian, Klasifikasi, dan Klasterisasi (Choi et al | Google Developers 2025)
Sebelum hadirnya EmbeddingGemma, pasar embedding banyak didominasi oleh model seperti OpenAI ada2vec, Cohere, dan Sentence-BERT. Model-model tersebut memang memberikan performa tinggi, tetapi seringkali dengan biaya besar baik dari segi ukuran maupun kebutuhan infrastruktur.
EmbeddingGemma menawarkan alternatif yang menarik:
- Lebih kecil dan ringan, sehingga ramah perangkat lokal.
- Multibahasa unggul, sementara banyak model populer masih terbatas di bahasa Inggris dan ini menjadi sesuatu yang sulit dicapai oleh model sebelumnya.
- Privasi lebih baik, karena inference bisa dilakukan offline.
- Integrasi luas, karena tersedia di Hugging Face, mendukung LangChain, LlamaIndex, dan Transformers.js untuk inference di browser.
Dengan kombinasi ini, EmbeddingGemma bukan hanya bersaing, tetapi juga memperluas akses ke embedding berkualitas tinggi bagi lebih banyak pengembang di seluruh dunia. Didukung dengan fitur fitur utamanya seperti:
1. Dukungan Multibahasa
EmbeddingGemma dilatih menggunakan berbagai bahasa, sehingga mampu memberikan hasil representasi teks yang akurat tidak hanya dalam bahasa Inggris, tetapi juga di bahasa lain. Dalam pengujian benchmark seperti MTEB (Massive Text Embedding Benchmark) dan M-MTEB (Multilingual MTEB), model ini menunjukkan performa yang konsisten tinggi di berbagai tugas multibahasa.
2. Matryoshka Representation Learning (MRL)
Salah satu inovasi utama dari EmbeddingGemma adalah penggunaan Matryoshka Representation Learning. Teknik ini memungkinkan embedding tetap berkualitas meskipun dimensi vektornya dikompresi. Artinya, pengembang dapat menyesuaikan ukuran embedding sesuai kebutuhan misalnya 512 atau 256 dimensi tanpa kehilangan performa signifikan.
3. Efisiensi dan Ringan
Dengan parameter yang relatif kecil, EmbeddingGemma bisa dijalankan pada perangkat dengan kapasitas terbatas seperti laptop standar atau bahkan browser. Hal ini memberikan peluang besar untuk aplikasi AI yang dapat diakses secara luas tanpa ketergantungan pada infrastruktur mahal.
4. Konteks Luas (2K Tokens)
Model ini mendukung jendela konteks hingga 2.000 token, memungkinkan pemahaman teks yang lebih panjang dan kompleks dibanding embedding sederhana.
5. Privasi dan On-Device Inference
Salah satu keunggulan besar adalah kemampuannya untuk digunakan tanpa internet. Dengan inference lokal, aplikasi dapat menjaga data pengguna tetap privat, sebuah aspek yang semakin penting di era kesadaran privasi digital.
Kesimpulan
EmbeddingGemma hadir sebagai jawaban atas tantangan besar dalam teknologi embedding: bagaimana menciptakan representasi teks yang akurat, mendukung multibahasa, efisien, serta menjaga privasi pengguna. Dengan fitur seperti Matryoshka Representation Learning, jendela konteks 2K tokens, dan kemampuan berjalan di perangkat lokal, model ini menandai sebuah lompatan penting dalam dunia AI. Lebih dari sekadar model embedding, EmbeddingGemma adalah sebuah langkah menuju AI yang lebih inklusif, dapat diakses oleh semua kalangan, dan relevan di berbagai konteks budaya serta bahasa. Tidak berlebihan jika dikatakan bahwa sejauh ini, EmbeddingGemma adalah salah satu terobosan terbesar dalam teknologi embedding multibahasa.
Penulis:
Samson Ndruru
FDP Scholar
Daftar Pustaka:
- Aarsen, T., Xenova, J., Bartolome, A., Roy Gosthipaty, A., Cuenca, P., & Paniego, S. (2025, September 4). Welcome EmbeddingGemma, Google’s new efficient embedding model. Hugging Face Blog. https://huggingface.co/blog/embeddinggemma
- Choi, M., Dua, S., & Lisak, A. (2025, September 4). Introducing EmbeddingGemma: The best-in-class open model for on-device embeddings. Google Developers Blog. https://developers.googleblog.com/en/introducing-embeddinggemma/
- Google. (2025, September 4). EmbeddingGemma model overview. Google AI for Developers. https://ai.google.dev/gemma/docs/embeddinggemma
- Gupta, M. (2025, September). Google Embedding Gemma: The best embeddings for your AI. Medium. https://medium.com/data-science-in-your-pocket/google-embedding-gemma-the-best-embeddings-for-your-ai-c90433d08ae6