
REINFORCEMENT LEARNING FROM HUMAN FEEDBACK DALAM PENGEMBANGAN MODEL AI

Source: Midjourney (AI Generated)
Pendahuluan
Dalam beberapa tahun terakhir, kemampuan Large Language Models (LLMs) seperti ChatGPT, Claude, dan Gemini dalam menghasilkan respons yang lebih relevan, sopan, dan sesuai konteks telah mencuri perhatian dunia. Kemajuan ini tidak hanya ditentukan oleh ukuran model atau banyaknya data pelatihan, tetapi juga oleh pendekatan pelatihan lanjutan yang dikenal sebagai Reinforcement Learning from Human Feedback (RLHF). RLHF merupakan salah satu inovasi penting dalam bidang Artificial Intelligence (AI), yang memungkinkan model tidak hanya meniru data, tetapi juga belajar dari preferensi manusia secara eksplisit. Dengan mengintegrasikan masukan manusia ke dalam proses development, RLHF membantu membentuk perilaku model agar lebih sesuai dengan ekspektasi pengguna dalam dunia nyata.
Namun, menentukan seperti apa keluaran model yang dianggap “baik” bukanlah hal yang mudah. Menurut Lambert et al. (2022), meskipun model bahasa telah menunjukkan kemampuan luar biasa dalam menghasilkan teks yang beragam dan menarik dari prompt manusia, penilaian terhadap kualitas teks bersifat sangat subjektif dan bergantung pada konteks. Dalam satu situasi, seperti menulis cerita fiksi, kreativitas sangat diutamakan, sedangkan dalam kasus lain seperti artikel informatif, akurasi menjadi hal yang utama. Bahkan dalam konteks pemrograman, yang dibutuhkan adalah keluaran yang dapat dijalankan secara fungsional. Karena alasan itulah, pelatihan model dengan mempertimbangkan preferensi manusia menjadi semakin penting untuk memastikan bahwa model tidak hanya menghasilkan teks yang koheren, tetapi juga tepat guna sesuai konteks penggunaannya.
Apa Itu Reinforcement Learning From Human Feedback?
Reinforcement Learning from Human Feedback (RLHF) adalah pendekatan pelatihan yang bertujuan untuk menyelaraskan perilaku model AI dengan nilai dan preferensi manusia. RLHF berfungsi sebagai jembatan antara model yang dilatih dengan data tanpa label (unsupervised learning) dan kebutuhan akan sistem AI yang dapat berinteraksi secara responsif dan aman di dunia nyata. Alih-alih menggunakan label eksplisit dalam supervised learning, RLHF memanfaatkan penilaian manusia terhadap output model untuk membentuk reward function. Hal ini memungkinkan model untuk tidak hanya menghasilkan respons yang masuk akal secara sintaksis, tetapi juga relevan secara sosial, etis, dan komunikatif.
Dalam praktiknya, RLHF digunakan sebagai tahap pelatihan lanjutan (fine-tuning) setelah model dasar dilatih. Proses ini terbukti meningkatkan kualitas instruksional, relevansi jawaban, dan kemampuan dialog model secara signifikan. Contoh utama penerapan RLHF adalah pada pengembangan InstructGPT oleh OpenAI, yang kemudian menjadi basis bagi ChatGPT (Ouyang et al., 2022). Untuk memberikan gambaran umum tentang bagaimana pendekatan ini bekerja, berikut adalah ilustrasi proses RLHF yang menyajikan interaksi antara model dasar, umpan balik manusia, dan proses optimisasi untuk menghasilkan model yang lebih selaras dengan nilai-nilai manusia.
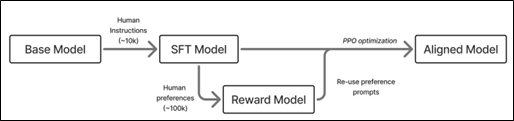
Source: Lambert (2025)
Mengapa Membutuhkan Human Feedback?
Pelatihan model AI dengan data internet berskala besar sering kali menghasilkan keluaran yang faktual, tetapi tidak selalu relevan secara sosial atau komunikatif. Menurut Mahareja (2025), dengan adanya intervensi manusia model berpotensi untuk:
- Mengurangi Kesalahan: Model AI kadang-kadang membuat keputusan yang salah jika data yang dipelajari tidak lengkap atau kurang representatif. Human Feedback dapat memberikan klarifikasi dan koreksi terhadap hasil yang kurang tepat.
- Mengatasi Keterbatasan Data: Data yang tidak mencerminkan situasi dunia nyata atau data yang tidak lengkap dapat membatasi kemampuan model AI untuk membuat keputusan yang baik. Masukan manusia membantu untuk mengisi kekosongan dalam data tersebut.
- Menjamin Nilai dan Etika yang Diinginkan: Model AI dapat membuat keputusan yang tidak sesuai dengan nilai-nilai sosial dan etika jika tidak diawasi. Melalui human feedback, AI dapat dilatih untuk membuat keputusan yang lebih bertanggung jawab.
Human feedback digunakan untuk menyaring, mengarahkan, dan menyempurnakan hasil output model. Hal ini penting karena apa yang “benar” dalam satu konteks bisa jadi “salah” dalam konteks lain dan manusia memiliki intuisi sosial dan kebijakan yang tidak dimiliki oleh mesin.
Bagaimana RLHF Bekerja?
Proses RLHF terdiri dari serangkaian tahapan bertingkat yang saling melengkapi. Setiap langkah bertujuan untuk menyempurnakan model agar mampu merespons sesuai dengan nilai dan preferensi manusia. Menurut Shaip (2024), berikut adalah langkah-langkah bagaimana RLHF bekerja.
- Pre-Trained Model
Tahapan pertama dimulai dengan LLMs yang telah dilatih sebelumnya secara unsupervised menggunakan data dari internet dalam jumlah besar. Model ini sudah memiliki pemahaman dasar mengenai struktur bahasa, pengetahuan umum, dan korelasi kata, namun belum dilatih untuk mengikuti instruksi secara eksplisit.
- Supervised Fine-Tuning (SFT)
Model dasar kemudian disempurnakan melalui proses supervised learning dengan menggunakan dataset instruksi yang telah dikurasi oleh manusia. Annotator memberikan pasangan prompt–response berkualitas tinggi dan model dilatih untuk meniru respons tersebut. Tahap ini membantu model belajar bagaimana seharusnya merespons pertanyaan atau perintah dengan struktur yang lebih tepat dan sesuai konteks.
- Reward Model Training
Setelah model mampu merespons instruksi, langkah berikutnya adalah reward model. Annotator manusia diminta membandingkan dua atau lebih respons yang dihasilkan oleh model dan menentukan mana yang lebih baik. Dari penilaian ini, reward model dilatih untuk memperkirakan preferensi manusia terhadap respons yang berbeda sehingga model dapat belajar menilai kualitas jawaban berdasarkan standar manusia.
- Proximal Policy Optimization (PPO)
Dengan reward model yang telah dilatih, dilakukan proses fine-tuning lanjutan menggunakan algoritma reinforcement learning, umumnya PPO. Model utama diperbarui secara bertahap untuk memaksimalkan reward dari reward model sehingga semakin sering menghasilkan respons yang disukai manusia. PPO menjaga agar perubahan pada model tetap stabil dan tidak terlalu ekstrem dari versi sebelumnya.
- Red Teaming
Tahapan terakhir melibatkan evaluasi lanjutan oleh red team yang bertugas menguji batas, kelemahan, atau potensi penyalahgunaan model. Red teaming membantu mengidentifikasi area berisiko tinggi seperti bias, informasi salah, atau konten berbahaya sehingga dapat dilakukan perbaikan sebelum model dirilis secara luas.
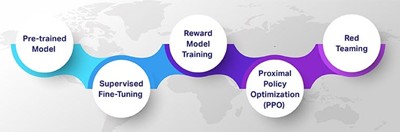
Source: Shaip (2024)
Kelebihan dan Kekurangan RLHF
Meskipun RLHF memiliki potensi besar dalam meningkatkan kinerja dan relevansi AI, ada beberapa tantangan yang perlu dipertimbangkan seiring dengan kelebihan yang ditawarkannya (Mahareja, 2025).
Kelebihan
- Peningkatan Kualitas Pembelajaran: Human feedback dapat mempercepat proses pembelajaran dan meningkatkan akurasi model AI, menjadikannya lebih efektif dalam mengambil keputusan.
- Memperbaiki Keputusan yang Memerlukan Penilaian Subjektif: Dalam situasi yang kompleks dan bervariatif, human feedback dapat memberikan evaluasi yang lebih tepat daripada data numerik atau environment yang terbatas.
- Mengurangi Bias dalam Pengambilan Keputusan AI: Dengan melibatkan lebih banyak human feedback, bias dalam model dapat dikurangi sehingga keputusan yang diambil lebih adil dan objektif.
- Menghasilkan Model yang Lebih “Human”: Dengan melibatkan nilai-nilai manusia, RLHF memastikan bahwa keputusan yang diambil oleh model AI lebih sesuai dengan etika sosial dan aturan yang berlaku.
Kekurangan
- Biaya Pengumpulan Data Manusia yang Mahal: Proses mengumpulkan human feedback memerlukan waktu, tenaga, dan biaya yang signifikan sehingga dapat menjadi kendala dalam skala besar.
- Subjektivitas dalam Human Feedback: Human feedback cenderung subjektif dan dapat bervariasi antara individu, yang dapat menyebabkan inkonsistensi dalam pelatihan model AI.
- Risiko Overfitting dan Bias: Jika agen AI terlalu mengandalkan human feedback, ada risiko terjadinya overfitting, di mana model terlalu terfokus pada preferensi tertentu dan mengabaikan variasi lain dalam data.
Contoh Pengaplikasian RLHF
Penerapan RLHF tidak hanya terbatas pada tahap penelitian, tetapi telah menjadi fondasi penting dalam pengembangan berbagai model AI. Keberhasilannya dalam menyelaraskan perilaku model dengan preferensi manusia menjadikannya strategi utama bagi perusahaan teknologi besar dalam membangun sistem yang lebih aman, kooperatif, dan berguna dalam konteks dunia nyata. Berkat pendekatan ini, model-model bahasa besar kini mampu merespons dengan cara yang lebih relevan, sopan, dan etis dalam berbagai domain aplikasi. RLHF telah diterapkan secara luas dalam model AI, seperti:
- ChatGPT: RLHF digunakan untuk membuat model mengikuti instruksi manusia lebih baik.
- Anthropic Claude: Menerapkan metode Constitutional AI yang berakar pada prinsip RLHF.
- Google Deepmind: Mengembangkan pendekatan yang serupa untuk dialog berbasis nilai.
Selain itu, RLHF juga mulai diterapkan dalam sistem AI untuk robotika, voice assistant, hingga pengambilan keputusan semi-otomatis yang memerlukan pemahaman konteks sosial dan interaksi yang lebih manusiawi.
Kesimpulan
Reinforcement Learning from Human Feedback (RLHF) telah menjadi fondasi penting dalam pengembangan model AI. Dengan menggabungkan kemampuan komputasional LLMs dan intuisi manusia, RLHF menawarkan pendekatan yang lebih adaptif, fleksibel, dan bertanggung jawab dalam membentuk perilaku AI. Meski memiliki tantangan, teknik ini membuka jalan menuju sistem AI yang lebih selaras dengan nilai dan kebutuhan manusia, sekaligus menunjukkan bahwa kecerdasan buatan yang efektif bukan hanya soal data besar, tetapi juga tentang bagaimana manusia membimbing mesin untuk belajar lebih bijak.
Penulis
Satriadi Putra Santika, S.Stat., M.Kom – FDP Scholar
Daftar Pustaka
Lambert, N. (2025). Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2504.12501v2.
Lambert, N., Werra, L. V., Castricato, L., & Havrilla, A. (2022). Illustrating Reinforcement Learning from Human Feedback (RLHF). Hugging Face. https://huggingface.co/blog/rlhf. Di akses 30 Juni 2025.
Mahareja, A. P. (2025). Reinforcement Learning Human Feedback: Menghubungkan AI dengan Keahlian Manusia. Qiscus. https://www.qiscus.com/id/blog/reinforcement-learning-human-feedback/#Mengapa_Masukan_Manusia_Diperlukan_dalam_Proses_Pembelajaran_Mesin. Di akses 30 Juni 2025.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton. J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155v1.
Shaip. (2023). Reinforcement Learning with Human Feedback: Definition and Steps. Medium. https://weareshaip.medium.com/reinforcement-learning-with-human-feedback-definition-and-steps-ccfbc5efc840. Di akses 30 Juni 2025.