
Apakah Handphone Kita Selalu Mendengar? Mengenal Cara Kerja Voice Assistant Siri, Alexa, dan Google.

Generated by: Gemini Nano Banana
Teknologi voice assistant saat ini sudah menjadi bagian dari kehidupan kita. Setiap smartphone baik Android maupun iOS sudah dibekali dengan embedded voice assistant seperti Siri dan Google Assistant. Untuk mengaktifkan fitur ini, pengguna cukup mengucapkan “Hey Siri” atau “Ok Google” dan secara otomatis assistant siap untuk mendengarkan instruksi pengguna. Tapi, apakah ini berarti smartphone yang kita gunakan secara aktif mendengarkan kita secara terus-menerus? Yuk kita kenalan dengan teknologi di belakang voice assistant.
Sistem Pengenal Kata Kunci
Teknologi voice assistant mengandalkan sebuah sistem pengenal kata kunci yang disebut Key-Word Spotting atau Wake-Word Detection. Sistem ini merupakan bentuk pengenalan suara yang memantau aliran audio secara terus-menerus untuk serangkaian kecil frasa / kalimat pendek. Karena perangkat harus mendengarkan bahkan ketika tidak aktif digunakan, sistem ini biasanya diimplementasikan sebagai sistem berukuran kecil dan berdaya rendah yang berjalan secara lokal di perangkat tersebut.
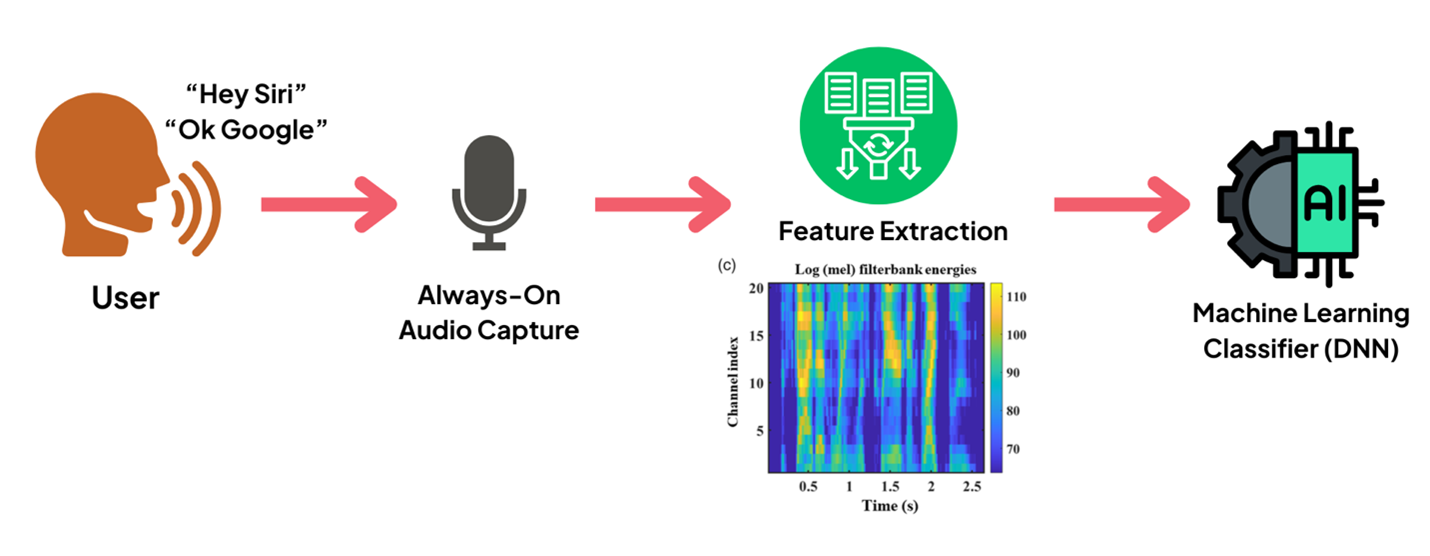
Gambar 1. Pipeline Sistem Pengenalan Kata Kunci
- Always-On Audio Capture
Untuk dapat mendeteksi kata kunci, sebuah microphone akan terus-menerus mendengarkan dan memberikan rekaman audio kepada low-power processor. Sebuah perangkat yang memiliki Digital Signal Processor (DSP) tersendiri atau low-power cores dapat melakukan monitoring walaupun dalam kondisi processor yang sedang tidak aktif. Sebagai contoh, Android AlwaysOnHotwordDetection memberikan kemampuan untuk mengatur DSP agar dapat berjalan dalam kondisi rendah energi dan kemampuan mendeteksi kata kunci. Sementara pada Apple iPhone yang tidak memiliki DSP tersendiri, digunakan motion coprocessor yang berfungsi sebagai always-on processor (AOP) sehingga perangkat dapat mendeteksi kata kunci walaupun ketika kondisi processor sedang tidak aktif (sleep). - Feature Extraction
Audio yang diterima kemudian diproses secara lokal dan dikonversi ke dalam fitur akustik Mel-Frequency Cepstral Coefficients (MFCCs). MFCCs dapat menguraikan suara ke dalam kumpulan fitur (seperti: nada, warna suara, dan volume) sehingga perangkat dapat mengenali potongan suara tanpa perlu menganalisa keseluruhan suara. - Machine Learning Classifier
Potongan suara yang telah diproses oleh MFCCs kemudian dianalisa dengan menggunakan model Deep Neural Networks (DNNs) atau Convolutional Neural Networks (CNNs) untuk mengestimasikan apakah suara mengandung kata kunci tertentu. Proses pengenalan ini diambil berdasarkan data training menggunakan dataset suara dan diadaptasikan dengan suara pengguna ketika pertama kali pengguna melakukan setup voice assistant di perangkat mereka.
Keamanan Privasi
Dengan adanya teknologi Keyword-Spotting atau Wake-Word Detection ini, timbul permasalahan terkait privasi dan keamanan data pengguna. Fitur Always-On Audio Capture menimbulkan dugaan bahwa perangkat mengambil rekaman percakapan terus-menerus dan mengirimkan data tersebut ke perusahaan perangkat. Untuk menjawab hal itu, teknologi ini menerapkan beberapa hal.
- On-Device Processing
Perusahaan seperti Apple dan Google, menerapkan proses deteksi kata kunci secara lokal di perangkat pengguna. Rekaman suara yang diterima oleh perangkat akan diproses menggunakan DSP dan AOP perangkat untuk mendeteksi apakah perintah voice assistant perlu untuk dijalankan. Dengan metode ini, dapat dipastikan bahwa rekaman yang dikirimkan ke server untuk diproses oleh Machine Learning hanya merupakan rekaman suara yang sudah diverifikasi sebelumnya. Keunggulan lain dari metode ini adalah proses deteksi awal tidak memerlukan koneksi internet. - Multi-Stage Architecture
Baik Apple maupun Google menerapkan multi-stage architecture untuk memastikan keamanan data, privasi, penggunaan daya, maupun akurasi. Pada bagian pertama, rekaman awal akan diproses pada model yang lebih kecil di low-power processor. Model ini memiliki recall yang tinggi namun bisa menghasilkan false positive. Ketika nilai berada di atas batas, rekaman kemudian dilanjutkan ke bagian kedua dimana saat ini rekaman diproses oleh prosesor utama. Google dalam patennya memperkenalkan metode Multi-Stage Hotword Detection. Rekaman awal yang ditangkap akan diproses pada tahap coarse-stage, jika nilai melebihi ambang batas maka rekaman ini akan diteruskan ke tahap fine-stage untuk diproses lebih lanjut oleh prosesor utama. Jika pada tahap pertama (coarse-stage) kata kunci tidak ditemukan, maka rekaman tidak akan pernah diteruskan ke tahap kedua. Sementara itu, Apple menerapkan metode Two-Pass Detection System. Tahap awal rekaman akan dianalisa oleh AOP dengan menggunakan model DNN-HMM kecil untuk mendeteksi kata kunci. Ketika nilai kepercayaan (confidence) sudah melebihi angka batas, maka suara akan teruskan ke tahap kedua, yaitu pemrosesan pada prosesor utama. Pada tahap ini, Application Processor akan menggunakan Conformer-Based Model untuk mendapatkan hasil presisi tinggi. Sama seperti Google, jika kata kunci tidak ditemukan pada tahap pertama, maka suara tidak akan diteruskan pada tahap kedua. - Speaker Verification
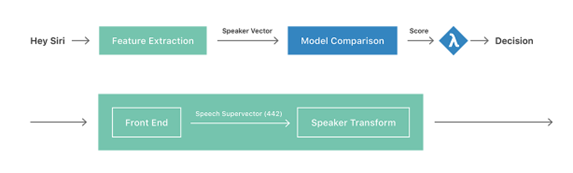
Gambar 2. Diagram Voice Signature Detection pada Apple Siri. (Sumber: https://machinelearning.apple.com/research/personalized-hey-siri)
Pada beberapa perangkat seperti Apple, digunakan sistem keamanan tambahan dengan menerapkan Speaker Verification. Sistem ini memastikan bahwa kata kunci hanya dapat diaktifkan oleh pengguna. Untuk mencapai hal tersebut, Apple meminta pengguna untuk merekam suara pada tahap konfigurasi awal, dan menyimpannya ke dalam voice signature yang diberikan voice-id. Dengan adanya sistem ini, suara yang tertangkap oleh AOP akan dicocokan terlebih dahulu dengan voice signature yang ada, sehingga mengurangi aktivasi tidak diinginkan oleh orang lain.
Kesimpulan
Teknologi Key-Word Spotting atau Wake-Word Detection memberikan kemudahan kepada pengguna untuk memberikan perintah dan berinteraksi kepada voice assistant secara hands-free. Baik Google dan Apple menggunakan pendekatan berupa DSP dan AOP agar proses dapat dilakukan secara lokal dan menggunakan daya yang rendah. Suara yang terdeteksi akan diproses menggunakan 2 tahap: tahap awal (coarse-step) pada perangkat rendah daya (DSP dan AOP) dan tahap kedua (fine-step) pada prosesor utama. Setelah tahap ini, maka perintah akan diteruskan ke server untuk dilakukan proses lebih lanjut dengan menggunakan Machine Learning.
Jadi voice assistant seperti Siri dan Google melakukan proses secara lokal tanpa menggunakan internet untuk mendengarkan dan memproses kata kunci. Rekaman suara tidak pernah dikirimkan ke server kecuali kata kunci ditemukan.
Penulis:
Muhamad Keenan Ario, S.Kom., M.Kom – Mobile Application & Technology.
Referensi
- Bobe, B. (2024, October 30). How voice assistants like Siri, Alexa & Google work ? https://medium.com/@threatspotlight/how-voice-assistants-like-siri-alexa-google-work-a2e6129c1bc7
- Integration flows. (n.d.). Android Open Source Project. https://source.android.com/docs/automotive/voice/voice_interaction_guide/integration_flows
- Personalized Hey Siri. (n.d.). Apple Machine Learning Research. https://machinelearning.apple.com/research/personalized-hey-siri
- Hey Siri: an on-device DNN-powered voice trigger for Apple’s personal assistant. (n.d.). Apple Machine Learning Research. https://machinelearning.apple.com/research/hey-siri
- (2024, November 1). Wake Word Processing: in the cloud or On-Device? https://www.sensory.com/wake-word-revalidation-in-the-cloud/
- Foerster, J. N., Gruenstein, A. H., Casado, D. M., & Llc, G. (2014, October 29). US10008207B2 – Multi-stage hotword detection – Google Patents. https://patents.google.com/patent/US10008207B2