
Memahami Attention Mechanism dalam Deep Learning: Cara Model AI “Memperhatikan” Informasi Penting
Pendahuluan
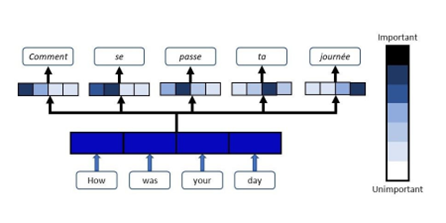
Salah satu kemajuan terbesar dalam bidang deep learning dalam dekade terakhir adalah munculnya attention mechanism, atau mekanisme perhatian. Konsep ini menjadi fondasi utama dari berbagai model modern, seperti Transformer, BERT, dan GPT, yang telah merevolusi bidang pemrosesan bahasa alami (NLP), visi komputer, hingga multimodal AI. Secara intuitif, attention mechanism memungkinkan model untuk memfokuskan perhatian hanya pada bagian data yang relevan, sama seperti manusia yang tidak memproses seluruh informasi sekaligus, melainkan memilih bagian yang penting untuk dipahami lebih dalam.
Konsep ini pertama kali diperkenalkan oleh Bahdanau et al. (2014) dalam konteks penerjemahan mesin (Neural Machine Translation) untuk mengatasi keterbatasan model sequence-to-sequence tradisional. Sejak saat itu, attention menjadi komponen penting dalam hampir semua arsitektur deep learning modern.
Source : https://teksands.ai/blog/attention-mechanism
Latar Belakang: Keterbatasan Model Sebelumnya
Sebelum adanya attention, model NLP seperti RNN (Recurrent Neural Network) dan LSTM (Long Short-Term Memory) memiliki keterbatasan dalam memproses urutan panjang. Pada model encoder-decoder tradisional, seluruh informasi kalimat masukan dikompresi ke dalam satu vektor tetap (context vector). Akibatnya, semakin panjang kalimat, semakin sulit bagi model untuk mengingat konteks awal. Masalah ini dikenal sebagai bottleneck representasi. Di sinilah attention mechanism muncul sebagai solusi: alih-alih menyimpan semua informasi dalam satu vektor, model dapat “memperhatikan” bagian-bagian tertentu dari input sesuai kebutuhan saat menghasilkan keluaran.
Konsep Dasar Attention Mechanism
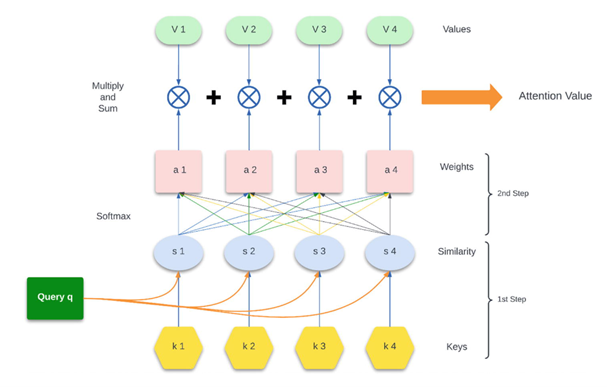
Secara sederhana, attention mechanism bekerja dengan memberikan bobot (weight) pada setiap bagian input berdasarkan tingkat relevansinya terhadap tugas tertentu. Prosesnya melibatkan tiga komponen utama:
- Query (Q) – representasi dari elemen yang sedang diproses (misalnya kata yang ingin diterjemahkan).
- Key (K) – representasi dari setiap elemen dalam input.
- Value (V) – informasi aktual yang dikaitkan dengan setiap key.
Model menghitung kesamaan (similarity) antara query dan setiap key untuk menentukan seberapa penting setiap value. Hasilnya adalah bobot perhatian (attention weights) yang kemudian digunakan untuk menggabungkan informasi dari value.
Secara matematis, perhatian dihitung sebagai berikut:
Rumus ini pertama kali dipopulerkan oleh Vaswani et al. (2017) dalam makalah terkenal “Attention is All You Need”, yang memperkenalkan arsitektur Transformer.
Jenis-Jenis Attention Mechanism
Selama perkembangannya, terdapat beberapa varian dari mekanisme perhatian, tergantung pada cara perhitungannya dan konteks penggunaannya:
- Soft Attention
Mekanisme ini menggunakan fungsi softmax untuk menghitung distribusi bobot perhatian secara halus (kontinu). Digunakan dalam model modern seperti Transformer.
- Hard Attention
Berbeda dengan soft attention, sistem ini memilih satu atau beberapa bagian input secara eksplisit. Karena bersifat tidak dapat diturunkan (non-differentiable), pelatihannya lebih sulit dan biasanya menggunakan metode seperti reinforcement learning.
- Self-Attention (Intra-Attention)
Digunakan ketika query, key, dan value berasal dari sumber yang sama.
Contohnya pada kalimat “Kucing itu duduk di kursi”, setiap kata dapat memperhatikan kata lain dalam kalimat yang sama untuk memahami konteks keseluruhan.
Self-attention merupakan dasar dari arsitektur Transformer dan model bahasa besar (LLM).
- Cross-Attention
Digunakan ketika query berasal dari satu urutan dan key-value dari urutan lain.
Contohnya pada sistem penerjemahan: decoder memperhatikan keluaran encoder untuk menerjemahkan kata berikutnya.
- Multi-Head Attention
Alih-alih hanya satu mekanisme perhatian, sistem ini menggunakan beberapa head paralel yang masing-masing belajar memperhatikan aspek berbeda dari input.
Hasilnya kemudian digabungkan, memungkinkan model menangkap beragam hubungan semantik dalam data.
Source : https://vitalflux.com/attention-mechanism-workflow-example/
Peran Attention dalam Model Transformer
Arsitektur Transformer sepenuhnya dibangun berdasarkan self-attention. Tidak seperti RNN yang memproses data secara berurutan, Transformer dapat memproses semua token secara paralel.
Dalam setiap lapisan Transformer, terdapat tiga komponen utama:
- Multi-Head Self-Attention – memungkinkan model memahami hubungan antar token.
- Feed Forward Network – mengubah hasil perhatian menjadi representasi baru.
- Residual Connection & Normalization – menjaga stabilitas pelatihan.
Inovasi ini memungkinkan Transformer melampaui performa model RNN dan CNN dalam berbagai tugas, dari penerjemahan bahasa, deteksi objek, hingga analisis citra medis.
Aplikasi Attention Mechanism
- Pemrosesan Bahasa Alami (NLP)
- Digunakan pada model seperti BERT, GPT, dan T5 untuk memahami konteks kalimat panjang.
- Membantu dalam tugas seperti machine translation, question answering, dan text summarization.
- Visi Komputer (Computer Vision)
- Diterapkan dalam model Vision Transformer (ViT) untuk menggantikan konvolusi pada CNN.
- Attention membantu model memahami bagian penting dari gambar tanpa memerlukan filter spasial tetap.
- Speech Recognition dan Multimodal Learning
- Attention digunakan untuk menghubungkan sinyal suara dengan teks dalam sistem pengenalan ucapan.
- Pada model multimodal (seperti GPT-4V), attention menghubungkan informasi dari berbagai sumber seperti teks, gambar, dan suara.
- Bioinformatika dan Medis
- Membantu menganalisis data sekuens DNA dan mendeteksi pola penting pada citra medis.
Kelebihan Attention Mechanism
- Kemampuan menangkap konteks global
Model tidak terbatas pada urutan lokal tetapi mampu memperhatikan hubungan antar elemen yang jauh. - Pemrosesan paralel yang efisien
Tidak seperti RNN, seluruh urutan data dapat diproses sekaligus. - Fleksibel dan dapat diterapkan lintas domain
Digunakan dalam NLP, visi komputer, hingga data graf dan multimodal. - Interpretabilitas lebih baik
Bobot perhatian dapat divisualisasikan untuk menunjukkan bagian mana dari input yang paling berpengaruh terhadap keputusan model.
Tantangan dan Arah Riset Masa Depan
Meskipun sukses besar, attention mechanism juga memiliki tantangan:
- Kompleksitas komputasi tinggi, terutama pada urutan panjang (karena perhitungan matriks O(n2)O(n^2)O(n2)).
- Konsumsi memori besar, terutama pada model berskala besar seperti GPT.
- Bias perhatian, di mana model mungkin terlalu fokus pada pola tertentu dan mengabaikan konteks lain.
Penelitian terkini mengembangkan berbagai varian efficient attention seperti Linformer, Performer, dan Sparse Attention untuk mengurangi biaya komputasi. Di masa depan, pendekatan ini diharapkan membuat teknologi berbasis Transformer lebih hemat energi dan dapat diterapkan di perangkat ringan.
Kesimpulan
Attention mechanism adalah salah satu inovasi paling berpengaruh dalam perkembangan deep learning modern. Dengan kemampuannya untuk meniru cara manusia memfokuskan perhatian, mekanisme ini telah mengubah cara komputer memahami bahasa, gambar, dan data kompleks lainnya.
Dari penerjemahan bahasa hingga visi komputer, attention kini menjadi fondasi utama berbagai arsitektur AI canggih. Seiring penelitian berlanjut, perhatian akan tetap menjadi kata kunci dalam evolusi sistem kecerdasan buatan yang lebih adaptif, efisien, dan cerdas.
Penulis
Fiqri Ramadhan Tambunan S.Kom., M.Kom – FDP Scholar
Referensi
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473.
- Vaswani, A., et al. (2017). Attention is All You Need. Advances in Neural Information Processing Systems (NeurIPS).
- Dosovitskiy, A., et al. (2020). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. ICLR 2021.
- Choromanski, K., et al. (2021). Rethinking Attention with Performers. International Conference on Learning Representations (ICLR).
- Tay, Y., et al. (2022). Efficient Transformers: A Survey. ACM Computing Surveys, 55(6), 1–28.
- Lin, Z., Feng, M., Santos, C. N. d., Yu, M., Xiang, B., Zhou, B., & Bengio, Y. (2017). A Structured Self-Attentive Sentence Embedding. ICLR 2017.