
Inverted Index: Fondasi Utama Mesin Pencari dalam Mengelola Informasi
Pendahuluan
Di era digital yang dipenuhi miliaran dokumen dan data teks, kemampuan untuk mencari informasi dengan cepat dan relevan menjadi sangat penting. Ketika pengguna mengetikkan kata kunci di mesin pencari seperti Google, hasil yang muncul dalam hitungan milidetik bukanlah hasil dari pencarian linear, tetapi dari sistem indeks yang efisiensalah satunya disebut Inverted Index.
Inverted Index merupakan struktur data inti dalam sistem pencarian teks (information retrieval) yang memungkinkan komputer menemukan dokumen yang relevan tanpa harus membaca keseluruhan isi satu per satu. Konsep ini menjadi dasar bagi berbagai aplikasi seperti mesin pencari, sistem rekomendasi, dan pencarian teks pada basis data besar.
Source : https://spotintelligence.com/2023/10/30/inverted-indexing/
Apa Itu Inverted Index?
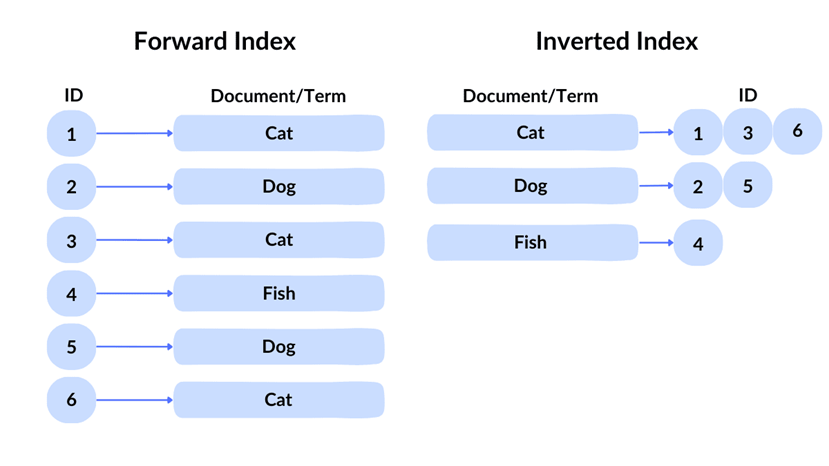
Secara sederhana, Inverted Index adalah struktur data yang menyimpan pemetaan dari setiap kata (term) ke daftar dokumen yang mengandung kata tersebut.
Berbeda dengan indeks biasa (forward index) yang mencatat isi setiap dokumen, inverted index bekerja “terbalik” — dari kata menuju dokumen.
Contohnya:
| Kata | Dokumen yang Mengandung |
| data | D1, D3, D5 |
| machine | D2, D3 |
| learning | D2, D4 |
Ketika pengguna mencari kata “learning”, sistem cukup melihat daftar dokumen di indeks untuk menemukan hasil terkait, tanpa membuka seluruh isi koleksi.
Asal-Usul dan Konsep Dasar
Konsep inverted index muncul dari ilmu Information Retrieval (IR) yang mulai dikembangkan sejak tahun 1950-an, dan menjadi fondasi bagi sistem pencarian teks modern.
Metode ini diadaptasi dari cara pustakawan menyusun indeks kata dalam buku atau katalog perpustakaan, tetapi dioptimalkan secara digital agar mampu menangani volume data yang sangat besar.
Inverted Index pertama kali diterapkan secara luas dalam mesin pencari komputer pada tahun 1990-an, seiring berkembangnya World Wide Web dan meningkatnya kebutuhan akan pencarian informasi otomatis.
Struktur dan Komponen Utama Inverted Index
Inverted Index umumnya terdiri dari dua komponen utama:
| Komponen | Penjelasan |
| Dictionary (Vocabulary) | Berisi daftar semua kata unik (terms) yang muncul dalam koleksi dokumen. |
| Posting List (Inverted List) | Menyimpan daftar dokumen tempat kata tersebut muncul, beserta informasi tambahan seperti frekuensi dan posisi kata. |
Contoh struktur sederhana:
Term: “machine”
Posting List:
→ Doc1 (posisi: 4, 20)
→ Doc3 (posisi: 12)
Informasi posisi ini sering digunakan dalam pencarian phrase query (misalnya: “machine learning”), agar sistem bisa memastikan urutan kata sesuai konteks.
Cara Kerja Inverted Index
Proses pembentukan dan penggunaan inverted index melibatkan beberapa tahapan utama:
- Tokenization
Teks dari setiap dokumen dipecah menjadi kata-kata (token), biasanya setelah melalui pembersihan tanda baca dan simbol.
- Normalization
Kata-kata diubah menjadi bentuk dasar (misalnya “running” → “run”), serta diubah menjadi huruf kecil agar pencarian tidak sensitif terhadap kapitalisasi.
- Stopword Removal
Kata umum seperti “and”, “the”, “of” dihapus karena tidak membawa makna penting dalam pencarian.
- Index Construction
Dari hasil pemrosesan, sistem membuat struktur pemetaan kata ke dokumen (posting list).
- Query Processing
Ketika pengguna mengetikkan query, sistem langsung memeriksa posting list pada dictionary untuk menemukan dokumen yang relevan.
Jenis-Jenis Inverted Index
| Jenis | Deskripsi | Kelebihan |
| Basic Inverted Index | Menyimpan daftar dokumen tanpa posisi kata. | Cepat dan hemat memori. |
| Positional Inverted Index | Menyimpan posisi kemunculan kata dalam dokumen. | Mendukung pencarian frasa dan konteks. |
| Compressed Index | Menggunakan teknik kompresi seperti delta encoding untuk menghemat ruang. | Efisien dalam penyimpanan besar. |
| Distributed Index | Diterapkan pada sistem terdistribusi (misalnya Google atau Elasticsearch). | Dapat menangani skala data besar dan paralel. |
Inverted Index vs Forward Index
| Aspek | Forward Index | Inverted Index |
| Arah Pemetaan | Dokumen → Kata | Kata → Dokumen |
| Tujuan | Menyimpan isi dokumen | Mempercepat pencarian |
| Kinerja Pencarian | Lambat (harus membaca semua dokumen) | Cepat dan efisien |
| Penggunaan | Analisis isi dokumen | Mesin pencari, retrieval sistem |
Penerapan Inverted Index di Dunia Nyata
Inverted Index menjadi tulang punggung berbagai sistem pencarian dan analisis teks, antara lain:
| Bidang | Contoh Penggunaan |
| Mesin Pencari Web | Google, Bing, dan DuckDuckGo menggunakan inverted index untuk mencocokkan kata kunci dengan miliaran halaman web. |
| Database Teks dan Dokumen | Elasticsearch, Solr, dan Lucene mengimplementasikan inverted index untuk pencarian cepat pada data besar. |
| Sistem Rekomendasi | Menemukan item atau produk berdasarkan kemiripan kata kunci dalam ulasan atau deskripsi. |
| Analisis Media Sosial | Mendeteksi topik tren berdasarkan frekuensi kemunculan kata tertentu dalam posting pengguna. |
| Aplikasi Forensik Digital | Mencari kata atau pola tertentu di dalam arsip dokumen yang besar. |
Keunggulan Inverted Index
- Efisiensi tinggi dalam pencarian teks besar.
- Waktu respon cepat, cocok untuk aplikasi real-time.
- Mendukung pencarian kompleks, seperti frasa dan boolean query.
- Mudah diperluas pada sistem terdistribusi dan big data.
- Kompatibel dengan berbagai teknik ranking seperti TF-IDF dan BM25.
Keterbatasan Inverted Index
- Membutuhkan ruang penyimpanan besar, terutama jika menyimpan posisi kata.
- Proses pembaruan (update index) bisa mahal secara komputasi.
- Rentan terhadap inkonsistensi jika ada perubahan dokumen tanpa reindeks.
- Tidak cocok untuk data yang berubah sangat cepat (streaming data) tanpa strategi caching.
Contoh Implementasi Sederhana
Misalkan terdapat tiga dokumen:
- D1: machine learning is fun
- D2: learning from data
- D3: machine learns patterns
Hasil inverted index:
| Term | Posting List |
| machine | D1, D3 |
| learning | D1, D2 |
| learns | D3 |
| data | D2 |
| fun | D1 |
| patterns | D3 |
Ketika pengguna mencari kata “learning”, sistem langsung mengembalikan D1 dan D2 tanpa harus membaca seluruh teks.
Kesimpulan
Inverted Index merupakan salah satu konsep paling fundamental dalam sistem pencarian modern. Dengan memetakan hubungan antara kata dan dokumen, struktur ini memungkinkan pencarian teks berskala besar dilakukan dengan cepat dan efisien.
Dari mesin pencari web hingga sistem rekomendasi cerdas, inverted index menjadi dasar bagi teknologi yang membantu manusia menavigasi lautan informasi digital.
“Inverted index adalah peta jalan bagi mesin pencari — bukan membaca semua dokumen, tetapi langsung menuju tempat informasi berada.”
Penulis
Fiqri Ramadhan Tambunan S.Kom., M.Kom – FDP Scholar
Referensi
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.
- Zobel, J., & Moffat, A. (2006). Inverted Files for Text Search Engines. ACM Computing Surveys.
- Baeza-Yates, R., & Ribeiro-Neto, B. (2011). Modern Information Retrieval: The Concepts and Technology behind Search. Addison-Wesley.
- Butcher, M. (2022). Inside the Architecture of Elasticsearch and Lucene. Journal of Data Engineering.
- Singhal, A. (2001). Modern Information Retrieval: A Brief Overview. IEEE Data Engineering Bulletin.