
BLEU vs ROUGE: Dua Metrik Populer untuk Menilai Kualitas Teks dari AI

Model bahasa seperti ChatGPT, Google Translate, dan sistem peringkasan otomatis kini mampu menghasilkan teks yang terdengar sangat alami. Namun, salah satu pertanyaan penting ketika bekerja dengan sistem semacam itu adalah bagaimana kita tahu apakah teks yang dihasilkan oleh mesin itu benar-benar bagus? Untuk menjawabnya, para peneliti menggunakan berbagai metrik evaluasi otomatis. Dua metrik evaluasi yang paling populer dalam hal ini adalah BLEU dan ROUGE. Keduanya adalah metode yang sama-sama mengukur kesamaan antara teks hasil model dan teks referensi manusia, namun dengan pendekatan yang berbeda.
BLEU: Mengukur Precision
BLEU, singkatan dari Bilingual Evaluation Understudy, diperkenalkan oleh IBM pada tahun 2002 (Papineni et al., 2002). Metrik ini dirancang untuk menilai kualitas hasil machine translation, yaitu menilai seberapa mirip hasil terjemahan mesin dengan hasil terjemahan manusia.
Prinsip dasarnya adalah menghitung kemiripan n-gram (urutan kata) antara teks hasil model dan teks referensi (hasil manusia). Semakin banyak n-gram yang cocok, semakin tinggi nilai BLEU-nya.
Contoh sederhana:
Referensi: The cat is on the mat.
Prediksi: The cat is on mat.
- Unigram (kata tunggal) yang cocok: The, cat, is, on → 4 dari 5 kata (precision = 4/5 = 0.8).
- Bigram (dua kata berurutan): “The cat”, “cat is”, “is on” → 3 dari 4 cocok (precision = 3/4 = 0.75).
BLEU juga memiliki yang namanya brevity penalty, yaitu penalti jika hasil terlalu pendek dibanding referensi. Jika prediksi terlalu singkat, skornya akan turun walau n-gram cocok.
Berikut adalah formula umum dari BLEU:
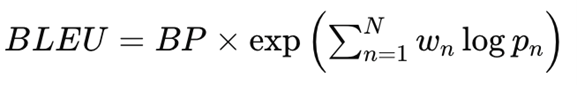
Di mana:
BP = brevity penalty
pn = precision untuk n-gram ke-n
wn = bobot untuk setiap n-gram (biasanya sama rata)
BLEU menghasilkan skor antara 0 – 1 (atau 0 – 100%). Skor mendekati 1 berarti hasil model sangat mirip dengan referensi manusia.
ROUGE: Mengukur Recall
Sementara BLEU fokus pada precision, ROUGE (Recall-Oriented Understudy for Gisting Evaluation) lebih menekankan pada recall, yaitu seberapa banyak informasi dari referensi yang berhasil ditangkap oleh teks hasil model (Lin, 2004). Metrik ini populer dalam task NLP seperti text summarization.
Berbeda dengan BLEU yang menghitung n-gram dari prediksi terhadap referensi, ROUGE menghitung n-gram dari referensi terhadap prediksi.
Contoh sederhana:
Referensi: The cat is on the mat.
Prediksi: The cat on mat.
Unigram dari referensi: The, cat, is, on, the, mat
Cocok dengan prediksi: The, cat, on, mat → 4 dari 6 (recall = 4/6 = 0.67)
ROIGE yang paling sering digunakan adalah ROUGE-N (berdasarkan n-gram) dan ROUGE-L (berdasarkan longest common subsequence / LCS).
Contoh, ROUGE-L menilai kesamaan urutan kata terpanjang yang berurutan antara referensi dan prediksi.
BLEU vs ROUGE
Meskipun keduanya mengukur kesamaan teks, BLEU dan ROUGE berbeda dalam fokus dan tujuan.
| Aspek | BLEU | ROUGE |
| Fokus utama | Precision | Recall |
| Aplikasi umum | Machine Translation | Text Summarization |
| Pendekatan | Mengukur seberapa banyak kata dari hasil model yang muncul di referensi | Mengukur seberapa banyak kata dari referensi yang muncul di hasil model |
| Sensitivitas panjang teks | Diberi penalti jika terlalu pendek | Tidak terlalu sensitif |
| Pertimbangan makna | Berdasarkan kesamaan literal (kata demi kata) | Berdasarkan jumlah informasi yang tertangkap |
Dalam praktiknya, peneliti sering menggunakan keduanya secara bersamaan untuk mendapatkan gambaran yang lebih seimbang antara ketepatan dan kelengkapan, serta sebagai perbandingan.
Contoh Perbandingan
Misalkan mahasiswa SoCS BINUS sedang mengembangkan sistem peringkasan otomatis untuk artikel profil kampus, yang akan dipublikasikan di situs SoCS. Sistem ini dirancang untuk merangkum artikel panjang menjadi versi singkat tanpa kehilangan informasi penting.
Referensi (ringkasan manusia):
“School of Computer Science BINUS merupakan salah satu jurusan dan kampus favorit di Indonesia, dikenal dengan inovasi di bidang teknologi dan kualitas lulusannya yang kompetitif.”
Ringkasan model:
“SoCS BINUS adalah salah satu jurusan favorit di Indonesia dengan lulusan yang unggul di bidang teknologi.”
- BLEU: Banyak n-gram yang cocok seperti “SoCS BINUS”, “jurusan favorit”, dan “bidang teknologi”. Precision tinggi karena pilihan kata sangat mirip.
- ROUGE: Hampir semua informasi penting dari referensi tercakup dalam hasil model. Recall tinggi karena maknanya sama walaupun ada perbedaan susunan kata.
Hasil: BLEU dan ROUGE sama-sama tinggi, artinya sistem ringkasan AI tersebut bekerja dengan baik karena hasilnya akurat dan tetap mempertahankan inti informasi.
Namun jika model menghasilkan: “BINUS adalah kampus dengan banyak kegiatan seni,” maka BLEU mungkin masih sedikit tinggi (karena ada istilah “BINUS”), tetapi ROUGE akan turun drastis karena informasi utama bergeser dari topik teknologi dan kualitas akademik.
Tantangan dan Metrik Modern
BLEU dan ROUGE masih menjadi standar evaluasi dalam NLP, tetapi keduanya memiliki kelemahan besar: mereka tidak memahami makna semantik. Dua kalimat yang berbeda kata namun sama maknanya bisa diberi skor rendah.
Karena itu, muncul metrik baru seperti BERTScore (Zhang et al. 2019) yang menggunakan representasi dari model transformer seperti BERT untuk menilai kesamaan makna antar teks.
Kesimpulan
BLEU dan ROUGE adalah dua metrik klasik yang masih relevan untuk menilai kualitas teks dari model AI. BLEU cocok untuk mengevaluasi hasil terjemahan yang menuntut ketepatan kata, sedangkan ROUGE lebih sesuai untuk ringkasan yang menuntut kelengkapan informasi.
Keduanya sama-sama penting, BLEU memastikan teks “tepat”, sementara ROUGE memastikan teks “lengkap.” Dan di masa yang akan datang, evaluasi kualitas bahasa akan semakin bergeser ke arah pemahaman makna yang lebih dalam, bukan sekadar menghitung kata, tetapi memahami konteks.
Penulis
Muhammad Alfhi Saputra, S.Kom., M.Kom. – FDP Scholar
Referensi
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 311–318.
- Lin, C. Y. (2004). ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, 74–81.
- Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2020). BERTScore: Evaluating text generation with BERT. International Conference on Learning Representations (ICLR).